







最近有人问了浪尖一个flink共享datastream或者临时表会否重复计算的问题。
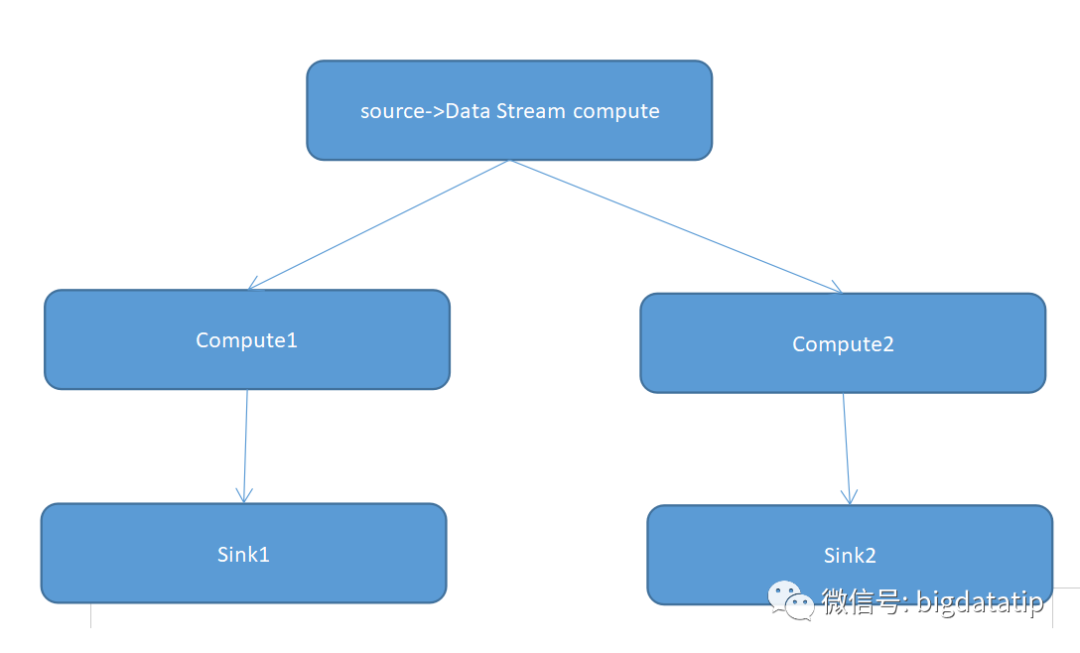
对于 flink 的datastream ,比如上图,source 经过datastream计算之后的结果想共享给compute1和compute2计算,这样可以避免之前的逻辑重复计算,而且数据也只需拉去一次。
而对于flink的sql呢?假如compute1和compute2之前是经过复杂计算的临时表,直接给下游sql计算使用会出现什么问题呢?
先告诉大家答案 ,临时表注册完了之后,实际上并没有完成物化功能,这时候后续有多个sqlupdate操作依赖这个临时表的话,会导致临时表多次计算的。
这个其实也不难理解,因为每次sqlupdate都是完成sql 语法树的解析,实际上也是类似于spark的血缘关系,但是flink sql不能像spark rdd血缘关系那样使用cache或者Checkpoint来避免重复计算,因为它并不能支持公共节点识别和公共节点数据的多次分发。
sql代码如下,供大家测试参考
package org.table.kafka;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.environment.StreamE 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









