




本文主要基于开源项目3DDFA[1],对采用深度学习训练方法的3DMM模板人脸重建算法整体流程做一个介绍。如有错误,欢迎评论指正。
一.算法流程
二.具体步骤
1.数据
数据集:300W-LP,AFLW,AFLW2000-3D
身份GT、表情GT和姿态GT生成
采用analysis-by-synthesis的方法生成[6],可以参考笔者之前的公众号文章[7],当然论文里提及下一步face profiling用到的MFF[4]生成的,具体区别在于引入了一些额外的损失函数进来。
数据增强
1)face profiling
![3D-meshing[5]](https://i-blog.csdnimg.cn/img_convert/7ab878d588167e03c76a0e10e6cac26b.png)
![face profiling[1]](https://i-blog.csdnimg.cn/img_convert/e12fd6a9a690692919b948a2cb0da63e.png)
人脸姿态增强,大概步骤如下:
- 利用GT关键点,采用MFF[4]算法进行3DMM拟合,并进一步补全得到完整的带耳朵脖子的全头模型;
- 选定三组锚点:boundary anchors,surrounding anchors,background anchors,然后进行delaunay三角剖分(当然这一步对于后两组的锚点需要进行一些估计);
- 施加想要的姿态变换到3dmm模型上,投影到图像上,也就对应了另一组三角剖分,然后按照论文提到的约束构建方程求解,最后就得到了姿态变换后的图像。
**注:**论文关于face profiling这里介绍不多,官方的matlab代码注释也很少比较难懂,笔者参考[11]中提到的人脸对齐步骤,最终的理解:

- 首先在人脸图像上的关键点上做三角剖分;
- 然后对于人脸图像对应的拟合3DMM模型运用姿态变换得到新视角,投影回图像平面进而得到一个新的三角剖分,计算这两个三角剖分的仿射变换,从而就可以得到姿态变换后的人脸图像了。
2)in-plane rotation
图片旋转。
3)bbox perturb
人脸框扰动。
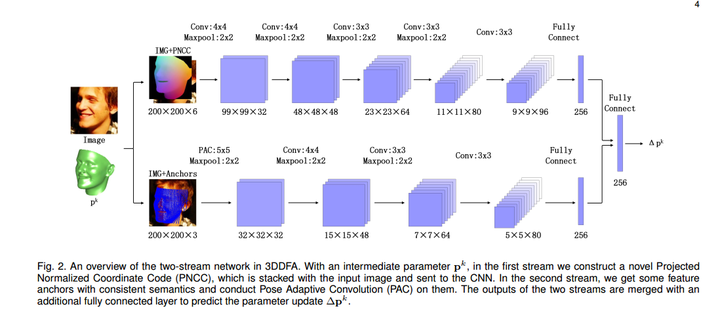
2.网络
输入
1)PAF(model-view feature)
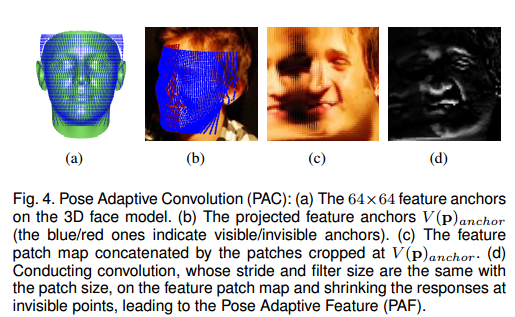
具体步骤如下:
- 对施加了当前身份、表情、姿态参数的3DMM模型进行柱面展开[2][3],然后按照固定的方位角和高度进行采样得到(3,64x64)维度的三维点,并进一步投影到图像平面得到(2,64x64)维度的anchor。


- 假设取kernel size为3,取每个anchor附近的3x3邻域的像素,然后连接到一起,最后得到一张(64x3,64x3,3)大小的图像。

2)PNCC(image-view feature)
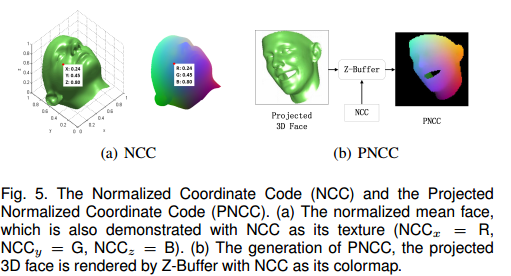
PNCC生成比较简单,具体步骤如下:
- 归一化3DMM的平均脸,使得x,y,z均在(0,1)范围内
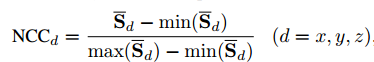
- 将NCC作为顶点像素值,采用Z-Buffer将施加了当前身份、表情、姿态参数的3DMM模型投影得到一张渲染图,即PNCC。
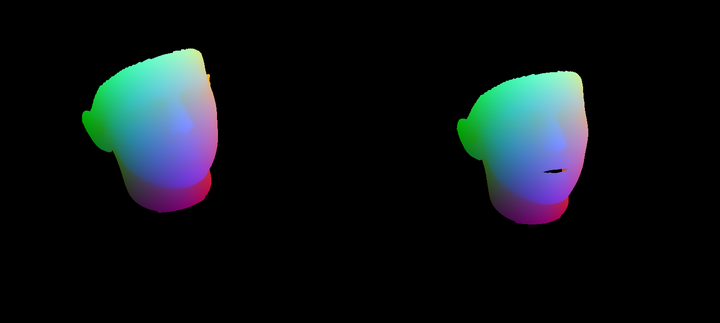
输出
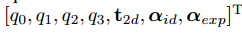
式中,q0q_0q
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 547
547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









