







视图(View)是一个由查询语旬定义数据内容的虚拟表,表中的数据内容就是SQL查询语旬的结果集。之所以说视图是虚拟的表,是因为视图并不在数据库中真实存在,而是在引用视图时动态生成的。对视图的操作与对表的操作一样,可以对其进行查询、修改和删除。
定义视图语法如下:
create view 视图名 as select 字段列表 from 表名 where 条件;
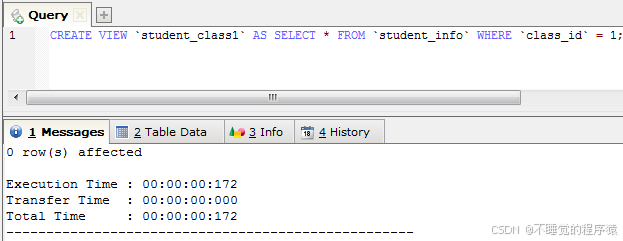
例如:create view `student1` as select * from `student_info` where `class_id` = 1;
然后,我们就可以按照正常表一样查询student_class1表:
例如:select * from `student_class1` where stu_id = 1;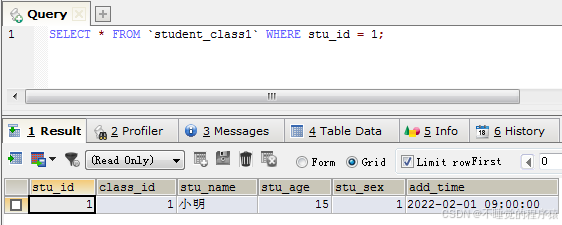
当然,我们还可以创建连表查询的视图:
例如:create view `student2` as select s.*, c.`class_name` from `student_info` as s, `class_info` as c where s.`class_id` = c.`class_id`;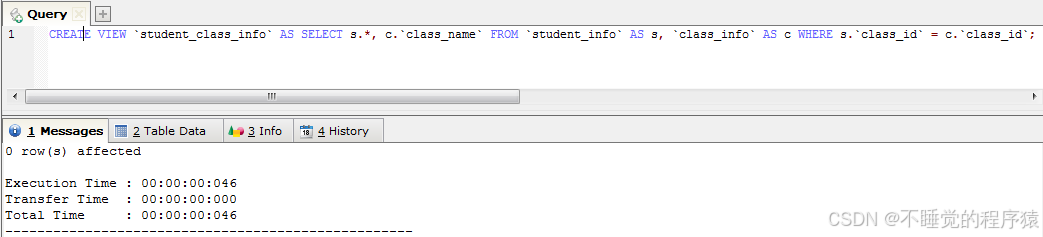
然后,我们就可以在student_class_info表上进行查询:
select * from `student_class_info` where stu_id = 1;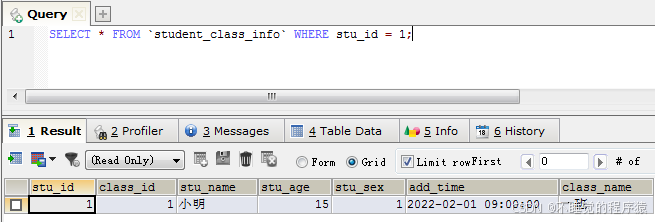
查看视图的信息可以使用: show table status like '视图名';
例如:show table status like 'student_class_info';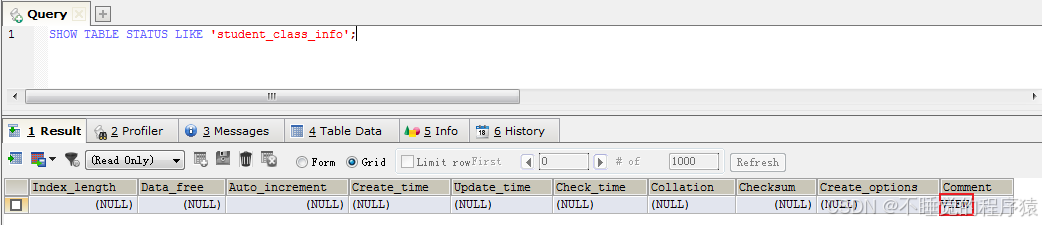
注意,使用单引号包裹视图名称。
结果显示:'student_class_info '表的很多列信息都是NULL,只有在Comment列的值为VIEW,说明该表为视图。
使用 show create view视图名可以查看该视图背后的sql查询语句。
例如:show create view `student_class_info`;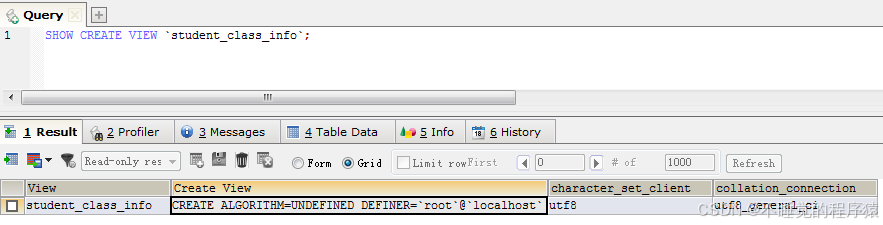
由于列宽原因,无法显示完整信息,我们复制出来查看一下:
create algorithm=undefined definer=`root`@`localhost` sql security definer view `student_class_info` as select `s`.`stu_id` as `stu_id`,`s`.`class_id` as `class_id`,`s`.`stu_name` as `stu_name`,`s`.`stu_age` as `stu_age`,`s`.`stu_sex` as `stu_sex`,`s`.`add_time` as `add_time`,`c`.`class_name` as `class_name` from (`student_info` `s` join `class_info` `c`) where (`s`.`class_id` = `c`.`class_id`)视图的修改是指修改了数据表的定义,当视图定义的数据表字段发生变化时需要对视图进行修改以保证查询的正确进行。在 MySQL 中使用create or replace view 语句可以修改视图。当视图存在时可以对视图进行修改,当视图不存在时可以创建视图。
语法格式如下:create or replace view 视图名 as select 语句;
例如:create or replace view `student_class1` as select * from `student_info` where `class_id` = 2;

我们在对`student_class1`进行查询的时候,就只能是2班的学生了。
最后介绍删除视图的语法:drop view 视图名;
例如:drop view `student_class1`;

除了对视图进行查询操作之外,还可以对视图进行插入,删除和修改操作。并非所有的视图都允许更新,只有某些简单的视图,再对其进行更新操作后,可以等价转化到对基本表的更新。如果一个视图是从单个基本表中导出,只是去掉了一些字段而已,那么这种视图是可以进行更新操作的。但是,如果是多表查询的视图,然后我们通过视图来去尝试修改数据的话,可能会出现一些无法预测的错误出现。因此,视图的存在主要是为了方便查询,不是修改。
存储过程是一组为了完成特定功能的SQL语句集,经编译后存储在数据库中,它可以被应用程序通过接口调用。它产生的原因是因为客户端与服务器端体系结构中执行性能的影响。由于没有存储过程,客户端应用程序发出的每个SQL操作请求都要通过网络发送到数据库服务器,并等待网络返回。这个过程中就有了网络传输的性能消耗。借助存储过程,这些操作步骤可以编写成一个存储过程,应用程序只需要调用一次,就可以获取最终的结果。
简单的理解,我们可以在MySQL中创建一段程序,可以对数据进行复杂的处理。这段程序可以包含SQL语句,以及一些存储变量,甚至包含分支结构或者循环结构等等。
创建存储过程需要使用 create procedure 语句,基本语法格式如下:
create procedure 存储过程名称 ( 形参列表 )
begin
……
end;
上述结构与Java的方法非常类似,存储过程名称相当于方法的名称,形参列表相当于方法参数,而begin和end就是一对花括号,中间就是我们要写的程序代码。
形参列表如:[ in | out | inout ] 参数名称 参数数据类型
其中, in表示输入参数, out表示输出参数, inout 表示既可以输入也可以输出
我们发现,形参列表与Java的方法参数不一样,Java方法的参数是输入参数,若需要输出则需要通过return语句完成,而存储过程直接通过定义形参的“方向类型”来说明是输入参数,还是输出参数,或者两者皆可。其实其他编程语言也存在这种方法参数传递方式。
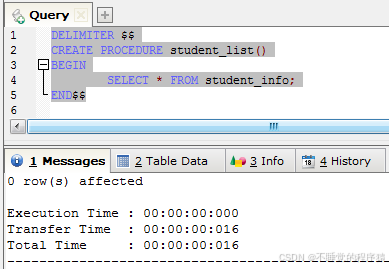
先创建一个无参数的student_list的存储过程,SQL语句如下:
delimiter $$
create procedure student_list()
begin
select * from student_info;
end$$
在mysql中分隔符默认是分号,但是在存储过程中由于要书写很多SQL语句,且每个SQL语句都会依分号结束,因此在存储过程书写过程中,需要使用delimiter重新定义一个结束符。也就是上面的“$$”,最后在存储过程的末尾end的位置添加这个结束符即可。

如何使用存储过程呢?
call 语句用来调用一个创建好的存储过程,基本语法格式如下:
call 存储过程名称 (参数列表)
例如调用上面的存储过程:call student_list;

结果就是输出学生列表。
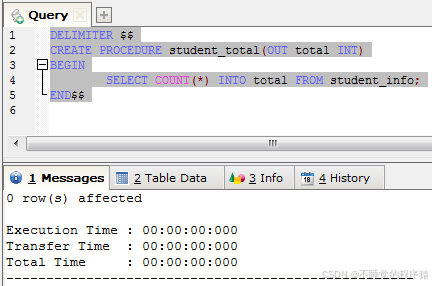
接下来创建名称为 student_total 的存储过程,SQL语句如下:
delimiter $$
create procedure student_total(out total int)
begin
select count(*) into total from student_info;
end$$
我们定义了一个输出类型的参数total,数据类型为整型int,然后我们使用count函数来统计学生的总数量,将这个数量值赋予total即可。

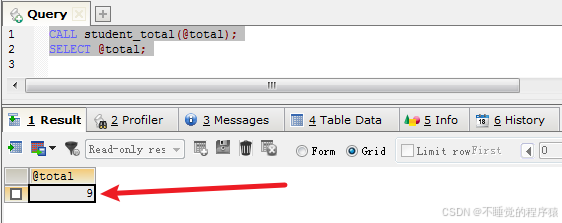
调用上面创建的存储过程:
call student_total(@total);
select @total;
上述调用过程中,我们使用了一个变量“@total”来存储学生的数量。
接下来,我们再创建一个求科目平均分的存储过程,SQL如下:
delimiter $$
create procedure student_avg(in subid int, out score float)
begin
select avg(`exam_score`) into score from `exam_info` where `sub_id`=subid;
end$$
这里我们定义了两个参数,第一个是输入类型的学科ID,第二个是输出类型的平均分。
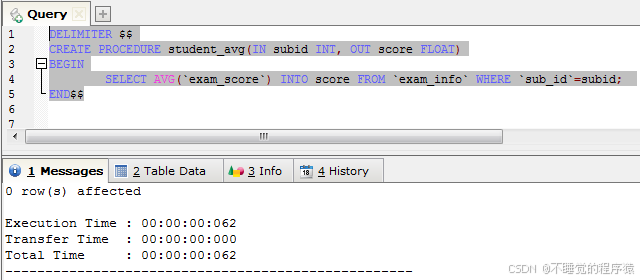

接下来是调用过程(上述参数名称尽量不要与字段名一致),SQL如下:
call student_avg(1, @score);
select @score;
我们输入的参数学科ID是1,也就是计算语文的平均分数。
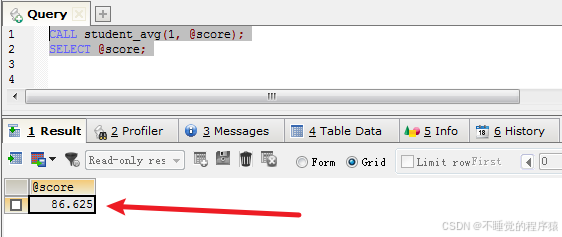
使用show procedure status 语旬查看存储过程,sql 语句如下:
show procedure status like 存储过程名称
例如:show procedure status like 'student_avg';
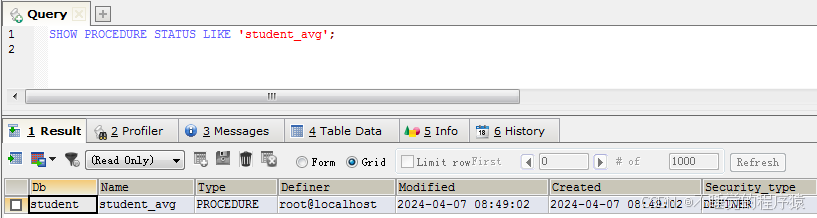
请注意show procedure status 语句只能查看存储过程操作哪一个数据库,存储过程的名称、类型,谁定义的,创建修改时间、字符编码等信息,不能查看存储过程的具体SQL定义。如果需要查看详细定义,需要使用show create procedure 语句。
语法格式为:show create procedure 存储过程名称
例如:show create procedure student_avg;

由于列宽问题,我们看不到完整信息,我们同样复制出来:
create definer=`root`@`localhost` procedure `student_avg`(in subid int, out score float)
begin
select avg(`exam_score`) into score from `exam_info` where `sub_id`=subid;
end
当数据库中存在的存储过程需要删除时 可以使用:DROP PROCEDURE 存储过程;
例如:drop procedure student_avg;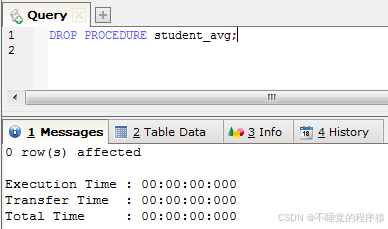
提示:如要修改存储过程的内容,可以先删除该存储过程,再重新创建。
我们顺便介绍一下存储函数,创建存储函数需要使用 create function 语句
create function 函数名称 (参数列表)
returns 数据类型
beign
sql语句
end
它的语法结构与存储过程非常相似。
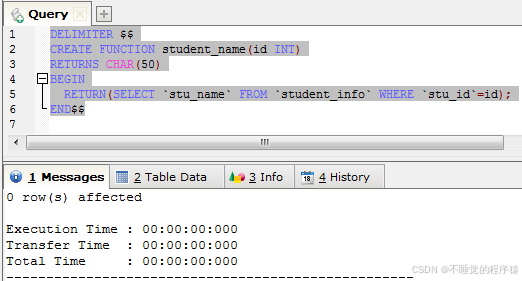
以下创建存储函数student_name,用于根据ID查询学生姓名
delimiter $$
create function student_name(id int)
returns char(50)
begin
return(select `stu_name` from `student_info` where `stu_id`=id);
end$$
请注意,存储函数需要使用return进行数据的返回,而不是参数哦。
存储函数的使用方法和 MySQL 内部函数的使用方法一样的。
调用存储函数:select student_name(2);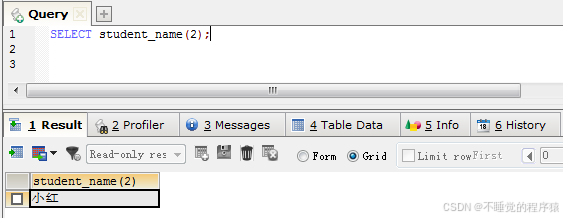
删除存储函数可以使用 drop function 函数名称;
例如:drop function student_name;
触发器是一种特殊类型的存储过程。触发器是通过事件触发并执行的。例如,当我们对表进行update或者delete操作时候,就可以自动执行触发器所定义的SQL语句。触发器的主要作用就是实现由主外键所不能保证的复杂的参照性完整和数据一致性。比如说,当我们向一个表中添加一条数据的时候,我们可以使用触发器来将该数据同步到另一个表中。
创建一个触发器的语法格式如下:
create trigger 触发器名称 trigger_time trigger_event on 表名 for each row trigger_stmt
触发器的名称,由用户自行指定;
trigger time 标识触发时机,可以指定为 before 或 after
trigger_event 标识触发事件,可以指定为 insert,update或delete
for each row 表示行级触发器,每个受影响的行都会执行触发器
trigger_stmt 触发器程序体,由begin和end包含多条语句
我们定义新的两张表结构和数据,如下所示:
create table `order_goods` (
`order_id` int(10) unsigned not null default '0' comment '订单id',
`goods_id` int(10) unsigned not null default '0' comment '商品id',
`goods_name` varchar(10) not null default '' comment '商品名称',
`goods_price` decimal(6,2) unsigned not null default '0.00' comment '商品价格',
`goods_num` smallint(5) unsigned not null default '0' comment '商品数量',
primary key (`order_id`,`goods_id`)
) engine=innodb default charset=utf8mb4 comment='订单商品信息表';
insert into `order_goods`(`order_id`,`goods_id`,`goods_name`,`goods_price`,`goods_num`) values (1,1,'奶茶','5.00',1),(1,2,'酸梅汤','4.00',1),(2,3,'可乐','3.00',1),(2,4,'橙汁','3.00',1);
create table `order_info` (
`order_id` int(10) unsigned not null auto_increment comment '订单id',
`user_id` int(10) unsigned not null default '10' comment '用户id',
`order_total` decimal(6,2) unsigned not null default '0.00' comment '订单总额',
`order_time` datetime not null default current_timestamp comment '下单时间',
primary key (`order_id`)
) engine=innodb auto_increment=3 default charset=utf8mb4 comment='订单信息表';
insert into `order_info`(`order_id`,`user_id`,`order_total`,`order_time`) values (1,1,'9.00', '2022-05-15 10:30:00'),(2,1,'6.00', '2022-05-15 10:30:00');

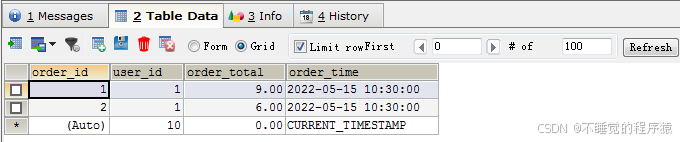
订单表记录了每一笔订单的总费用,以及下单时间。由于订单中可能包含多个商品,因此这是一对多的关系,我们需要单独创建一个订单商品表进行存储。
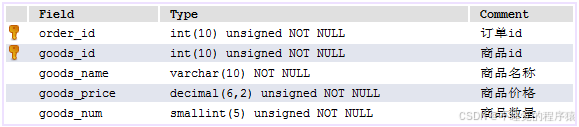
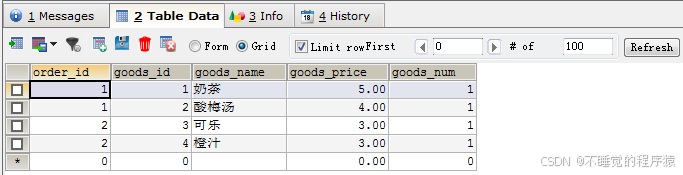
订单商品表中定义了商品的id,名称,单价以及数量等信息。重要的是,每一个商品都隶属于某一个订单,因此需要“order_id”来标示该商品属于哪一个订单。请注意,订单商品使用双主键(商品Id和订单Id)来唯一确定表中的一条数据。因为同一个商品可以存在与不同的订单中,商品Id不可能单独做主键的。有人可能提出疑问,同一个订单中可以出现两个相同(商品Id)的商品嘛?在我们双主键的情况下,是不允许的,解决的办法就是增加商品数量字段了。这个应该很容易理解。
理清订单表和订单商品表的关系之后,我们接下来,就创建一个名为 order_update 的触发器,触发的条件是向订单商品表中插入数据之后对订单表的总额进行更新。这个过程其实非常简单,就是累加新商品的价格,然后更新订单表中的order_total字段即可。
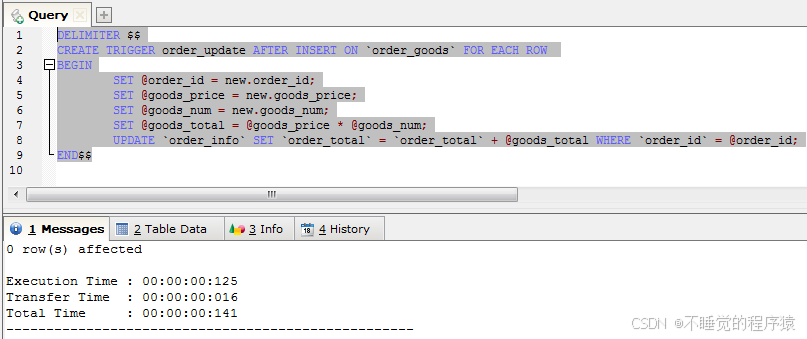
delimiter $$
create trigger order_update after insert on `order_goods` for each row
begin
set @order_id = new.order_id;
set @goods_price = new.goods_price;
set @goods_num = new.goods_num;
set @goods_total = @goods_price * @goods_num;
update `order_info` set `order_total` = `order_total` + @goods_total where `order_id` = @order_id;
end$$
这里需要说明一下触发器的参数:new和old。对于insert语句,只有new是合法的;对于delete语句,只有old才合法;而update语句可以在和new以及old同时使用。
这里我们可以先查看订单Id=1订单总额当前为9元。
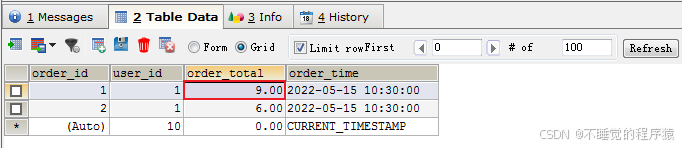
当我们插入一个3元商品后,应该自动执行我们的触发器,订单总额变为12元。
接下来,我们插入订单商品表一条记录:
insert `order_goods` values (1, 3, '可乐', 3, 1);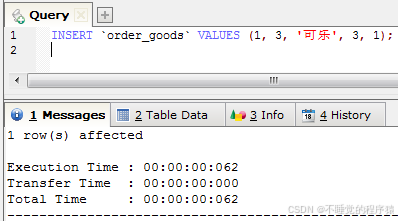
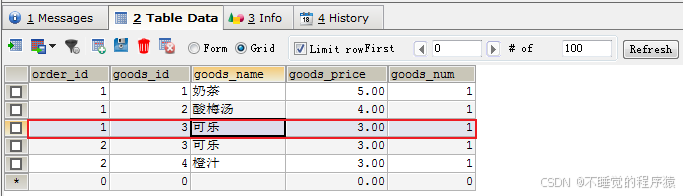
接下来,我们就去查看订单ID=1的订单总额变成了12元,说明我们的触发器成功了。

我们在创建一个新的触发器,删除订单商品,更新订单主体信息。
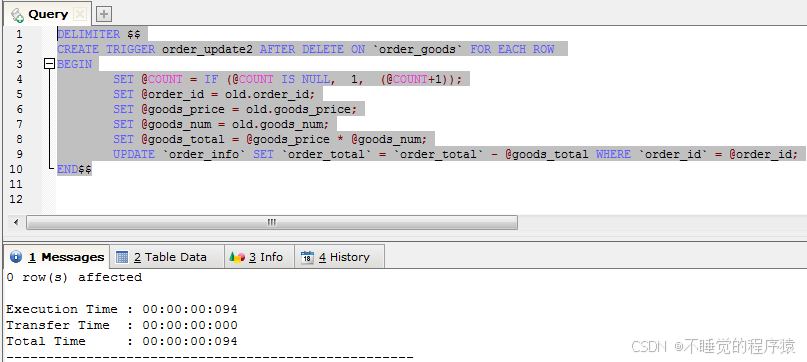
delimiter $$
create trigger order_update2 after delete on `order_goods` for each row
begin
set @count = if (@count IS NULL, 1, (@count+1));
set @order_id = old.order_id;
set @goods_price = old.goods_price;
set @goods_num = old.goods_num;
set @goods_total = @goods_price * @goods_num;
update `order_info` set `order_total` = `order_total` - @goods_total where `order_id` = @order_id;
end$$
接下来,我们执行:delete from order_goods where order_id = 2;

执行上述删除SQL语句的话,会删除两条记录,那么order_update2 就会被调用两次。
那么最终编号为1的订单总额应该是0,且 select @count; 的值应该是 2


最后,使用 drop trigger 语句可以删除触发器。
例如:drop trigger if exists order_update2;

















 456
456

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









