




核心区别:两种不同的“掩码”
在HSTU这类模型中,有两种完全不同目的的掩码:
- 注意力掩码(Attention Mask):控制模型在计算时能“看”到什么。目的是为了保持自回归特性,防止模型“作弊”地看到未来的信息。
- 损失掩码:当前位置的预测一个,没有label不预测或预测结果不计入损失函数
1.HSTU是如何做召回和排序任务的?
将排序和召回重新推导为顺序推导任务 ,
1️⃣ 召回:
将召回任务建模成一个序列预测问题,非常类似于NLP中的“下一个词预测”。模型学习一个概率分布
或
(这里的
指的是混合后的最后一个位置的表示),即根据用户过去的交互历史,来预测在
t时刻用户最可能与之交互的下一个物料。
最终,模型会从当前的候选物料池
中,选出那个预测概率最高的物料:

这个过程与标准的自回归模型(比如GPT)非常相似,但有两个关键区别,可以用(输出目标)
掩码(mask)序列解决1️⃣ 下一个token
可能是负样本(比如曝光未点击、不喜欢);
2️⃣ 下一个token
两种情况对应的掩码
会被设置为0。这意味着,根本不需要预测结果,或者在计算损失函数时,这一步的预测结果不会对模型的参数更新产生影响。
2️⃣ 排序:
排序需要目标感知target-aware的,当前候选项目target和历史行为需要做交叉,且越早越好。(传统自回归模型的局限: 传统自回归模型在预测
y_t时,通常会将前面的历史y_{<t}编码成一个单一的上下文向量(User Embedding)。然后,用这个向量去和所有候选物料的向量做点积或通过一个简单的网络来计算分数。这种方式的“交叉”发生得太晚(在最后的Softmax层),而且交叉的深度不足。)因此,文章将item和用户行为action交错插入到主时间序列来解决这个问题
模型根据历史行为序列,在给定item的情况下预测它的action
重构序列: 不再将 item 和 action 视为一个整体事件,而是将它们拆分并交错插入到时间序列中。新的序列变成了:
物料,行为
,物料
,行为
,...
重新定义预测任务:
- 在物料
的位置,模型需要进行预测行为- 在行为
的位置上,掩码m_t会被设置为0,不进行预测
特性 召回(Retrieval)中的损失掩码 排序(Ranking)中的损失掩码 掩码类型 损失掩码 (Loss Mask) 损失掩码 (Loss Mask) 共同目的 选择性地施加监督,将无意义或有害的预测步骤的损失置为0。 选择性地施加监督,将无意义或有害的预测步骤的损失置为0。 应用规则 基于“目标token”的性质:如果目标是负反馈或非物品特征,则掩码。 基于“当前token”的类型:如果当前位置是行为token,则掩码。 监督位置 任何一个token的位置,只要其下一个token是正反馈物品。 只在物品token ( Φi) 的位置。预测目标 预测下一个正反馈物品。 预测当前物品对应的用户行为。 我理解:对于历史行为序列做的是自回归,在item位置预测行为,其余action或非序列特征的位置上不做预测。由于候选项目是并列的,没有顺序关系,所以掩码注意力主对角线为1,其余为0,不需要做预测,只是融合上下文。自回归之后,需将对候选项目位置的表示通过多任务模型预测,然后排序。

2.时间复杂度
见另一个文章https://blog.youkuaiyun.com/return1999/article/details/151720228?spm=1001.2014.3001.5502
工业级的推荐系统通常是流式训练的, 在这种方式下, 使用self-attention的序列转导框架(如Transformers)训练, 总的计算量会是
, 其中是
用户的token数量,
是embedding的维度. 括号里的第一部分是self-attention的开销, 第二部分是pointwise MLP层的开销。取
, 则总的计算时间复杂度为
, 这个开销实在太高了。
为了缓解计算开销问题, 作者舍弃传统的曝光粒度的训练方式, 转向生成式训练, 将时间复杂度减少了
。另外, 作者也做了用户维度的采样, 进一步减少了时间复杂度。
3.HSTU的注意力和transformer的注意力的区别
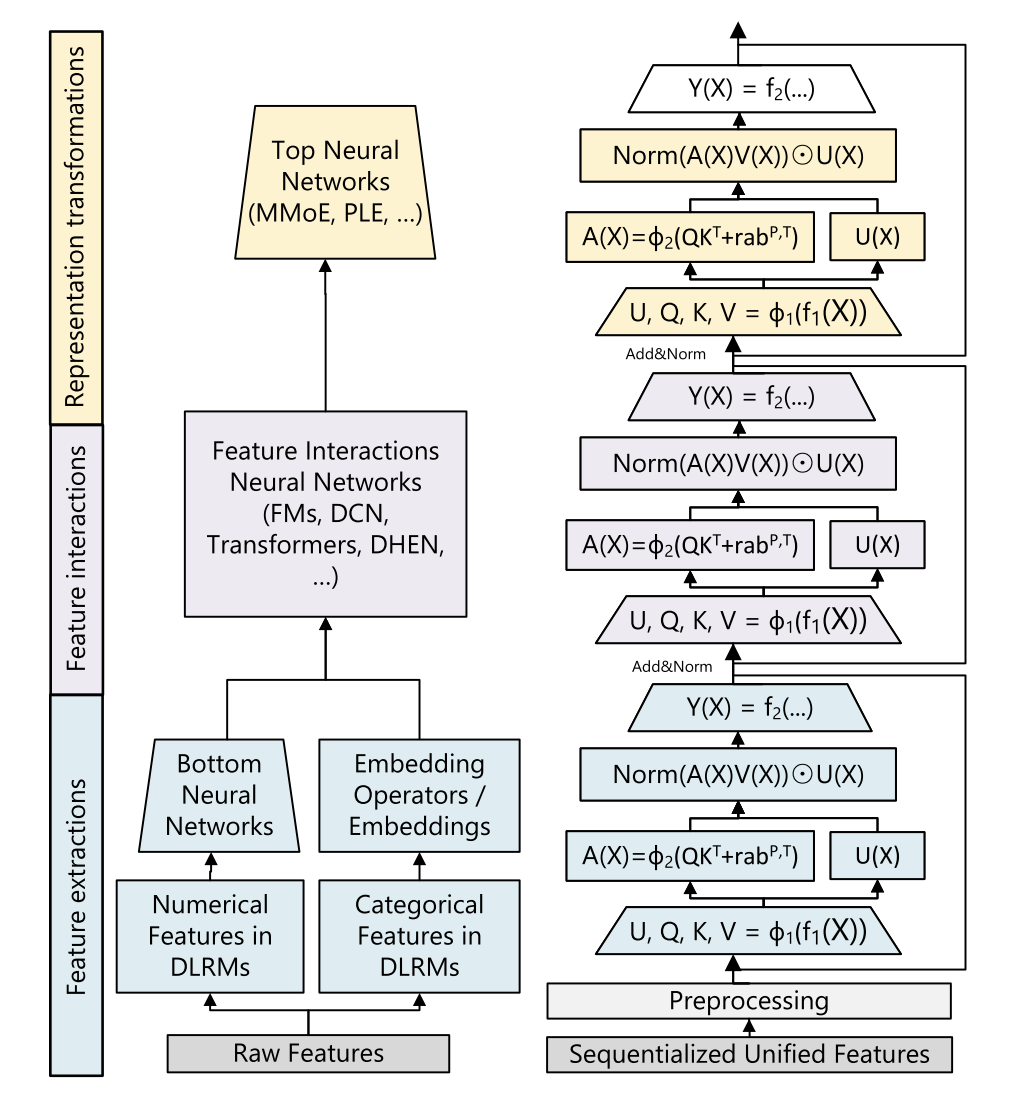
1️⃣softmax
2️⃣激活函数思路
3️⃣门控U(X)
4️⃣参数量
5️⃣公式
6️⃣位置编码

















 1611
1611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









