




目录
丹摩智算介绍
DaModel(丹摩DAMODEL|让AI开发更简单!算力租赁上丹摩!)是一个专注于提供高性能计算资源和服务的平台,特别是针对人工智能开发、机器学习、深度学习等领域的应用。该网站提供的服务和资源可以帮助用户更高效地进行模型训练、算法测试以及数据处理等工作。
1. 用户体验
注册流程
进入DaModel登录页面,提供了多种方式进行登录,方便用户。
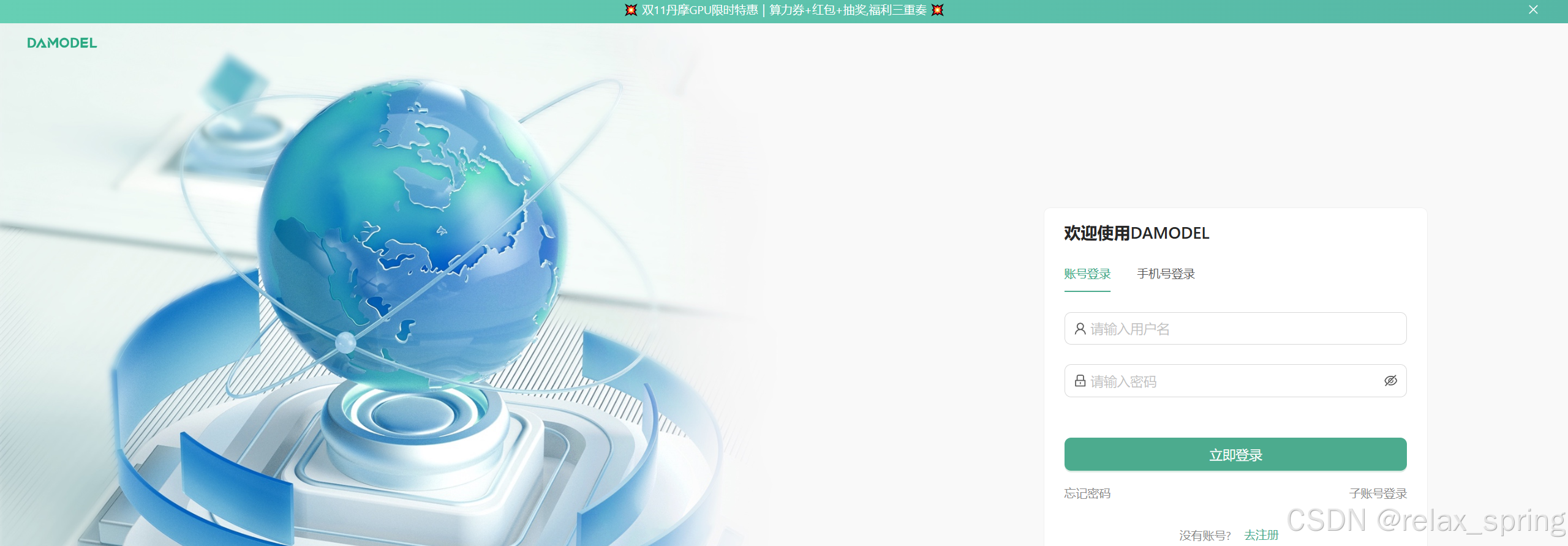
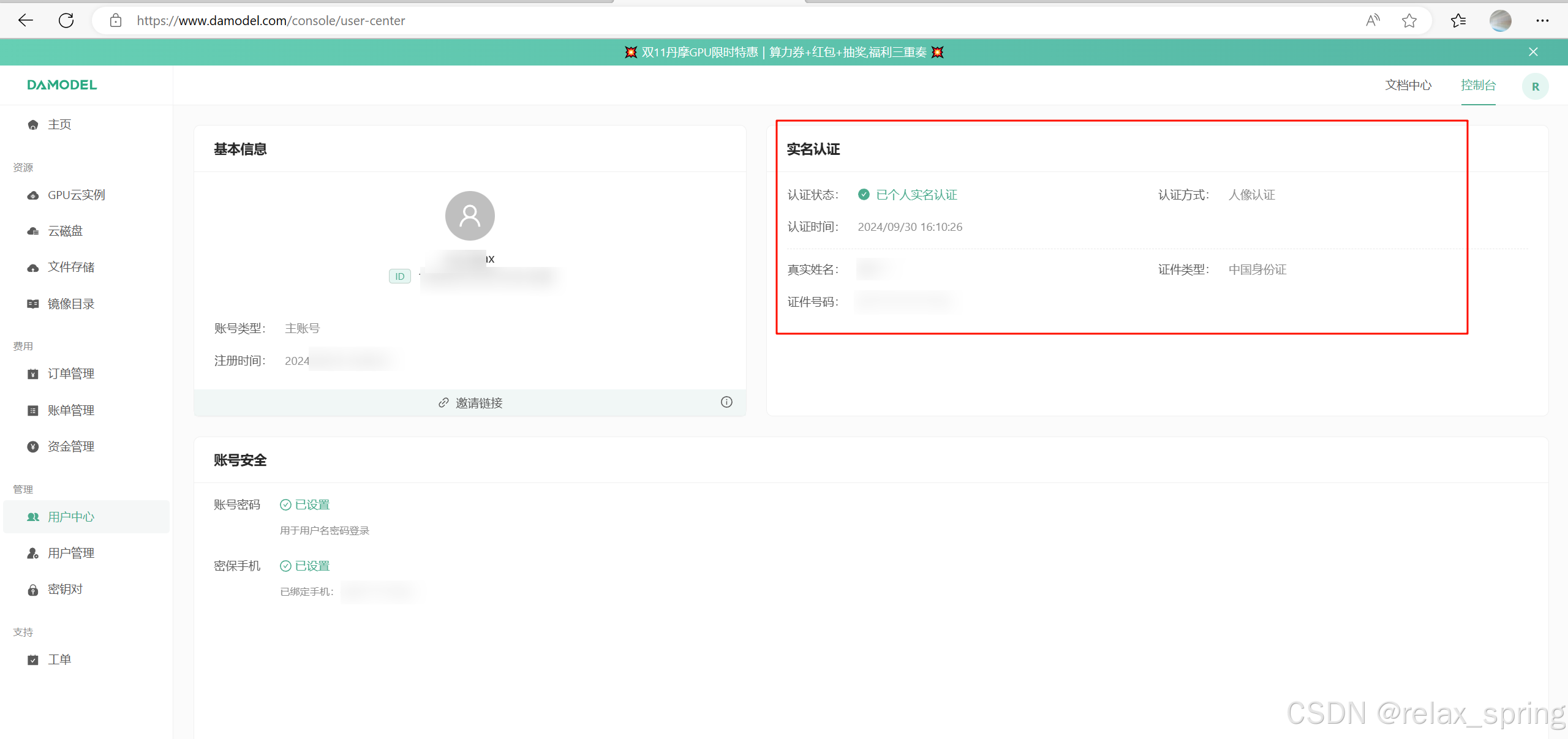
登录成功进入控制台,完成实名认证即可使用DaModel中的各类服务。
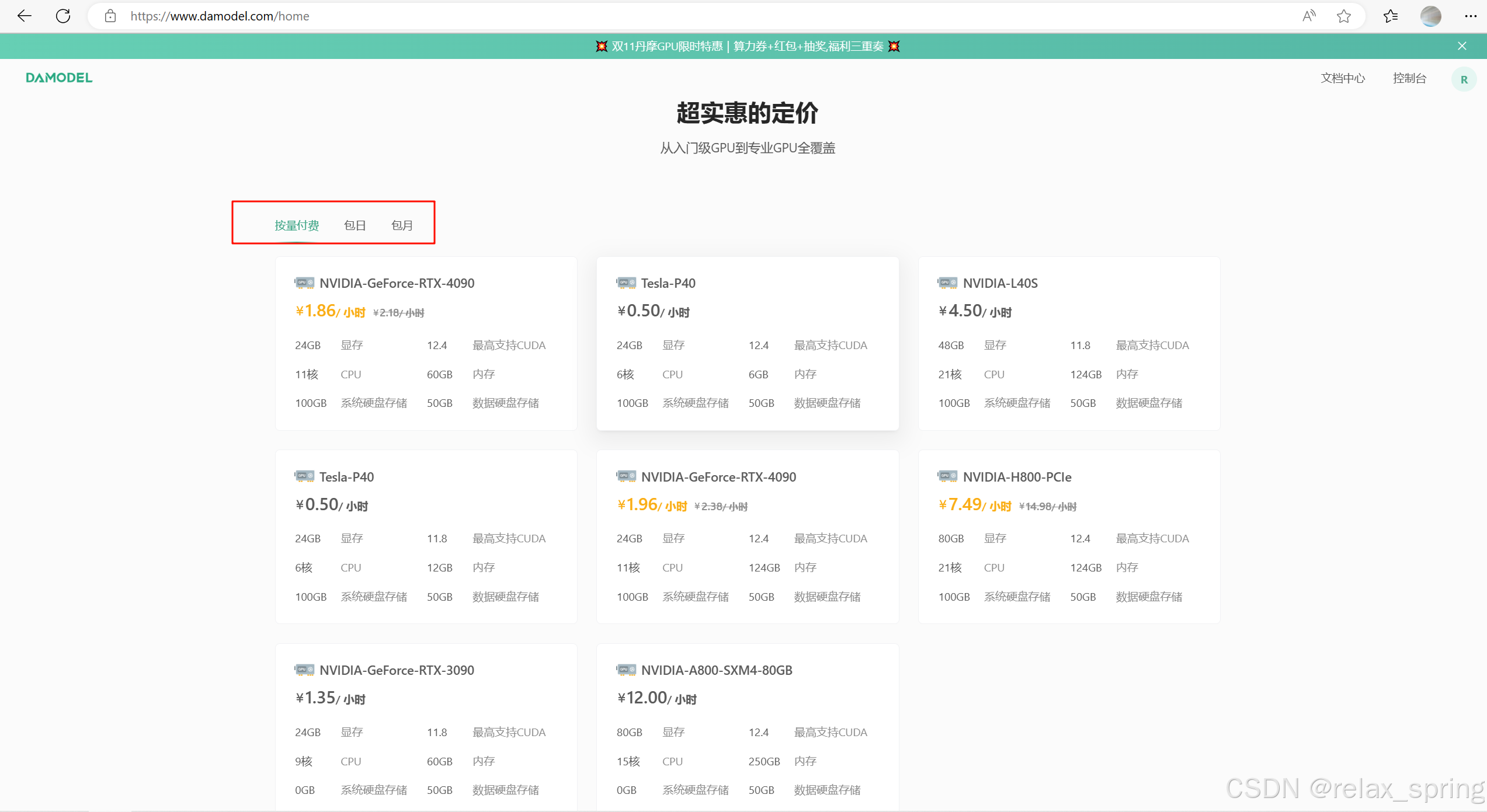
界面设计
进入首页便可以看到DaModel提供了从入门级GPU到专业GPU全范围覆盖,每个GPU型号都列出了详细的规格信息,包括显存、CPU核数、内存、系统硬盘存储和数据硬盘存储等便于用户选择,且支持多种租赁方式,满足用户的不同需求。
文档和支持
DaModel的文档中心还提供了各种解决方案,为用户答疑解惑。
2. 性能表现
计算资源:
进入控制台,创建实例,可看到DaModel目前可支持到4090级显卡,可支持大部分人的学习研究了。
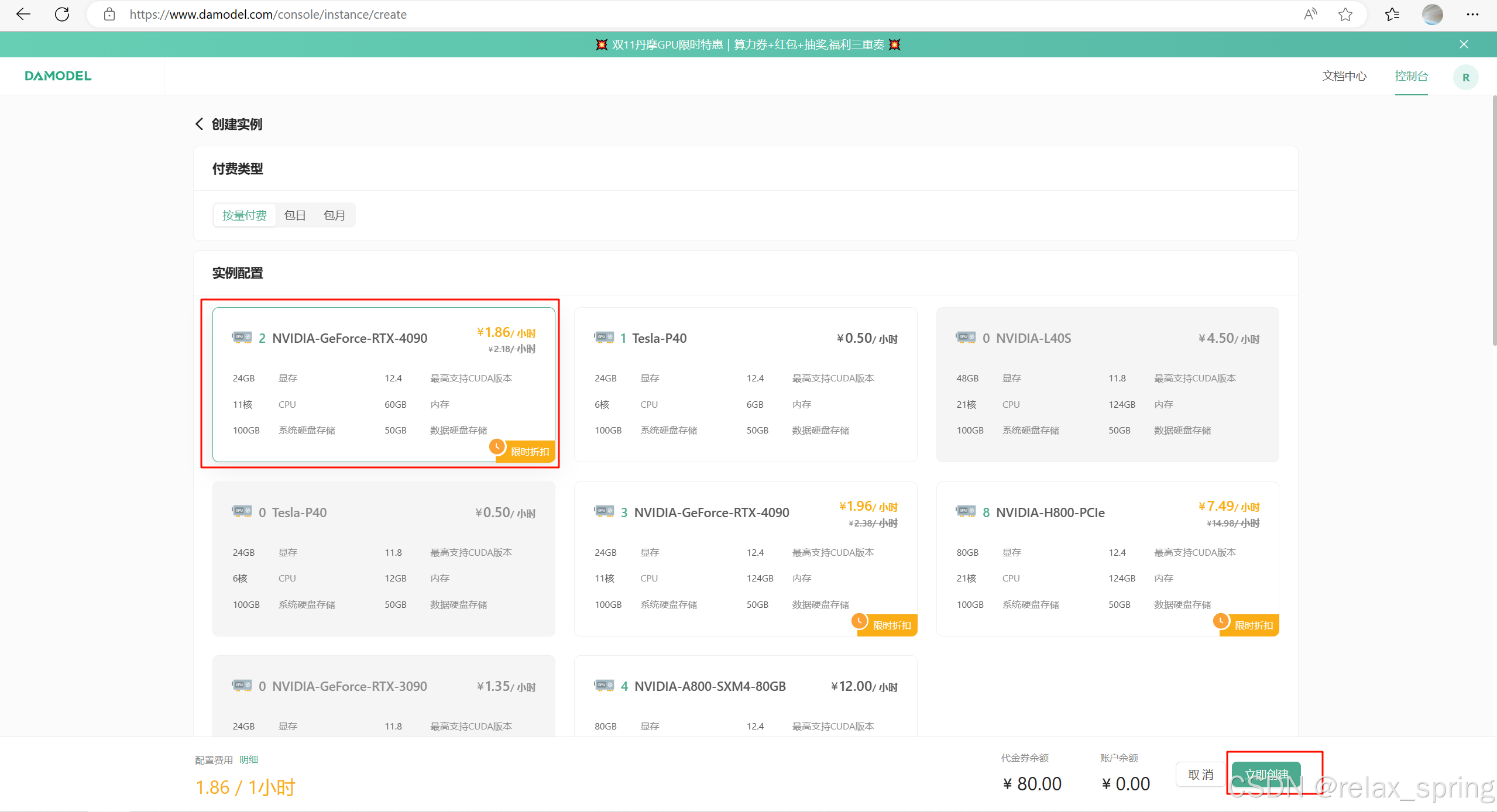
选择好资源,创建密钥对即可购买使用。
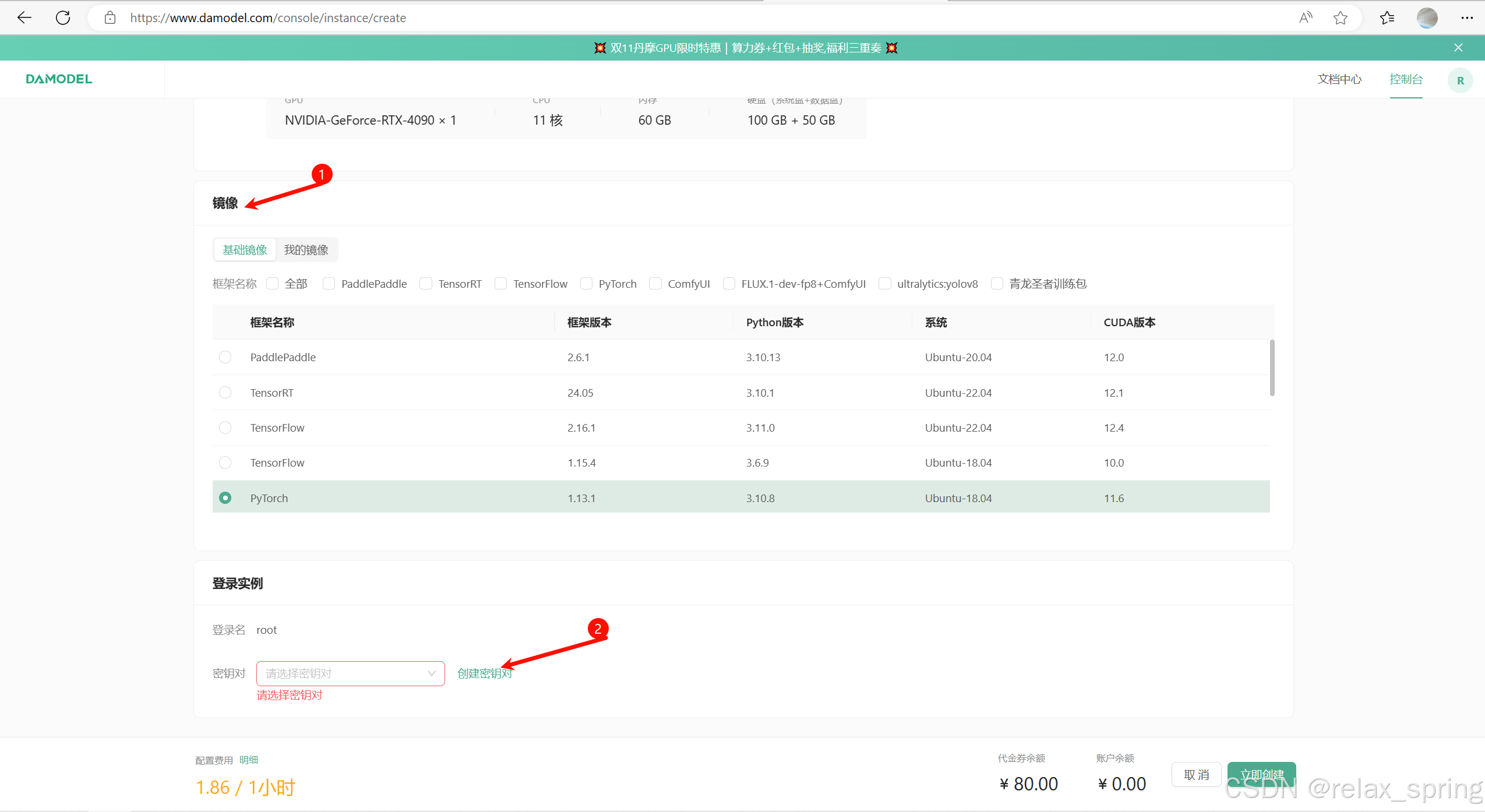
稍作等待,完成后即可使用资源。
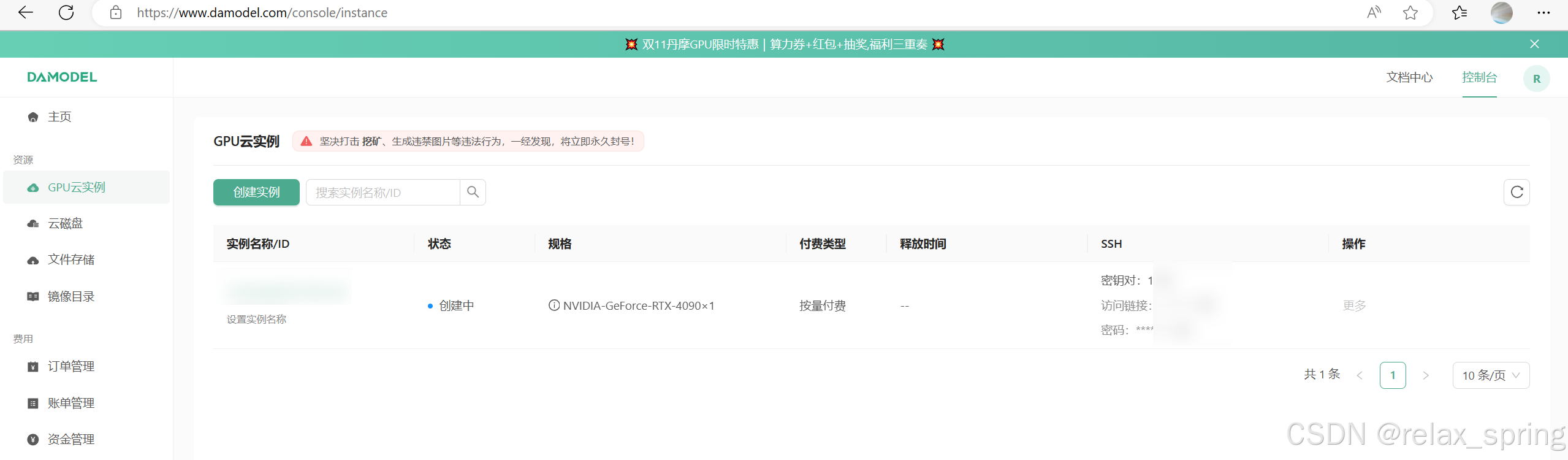
实际测试
我们使用这个GPU测试我的的文生图可看到,生成的图片效果即好又准确。

3. 平台实例
实例选择
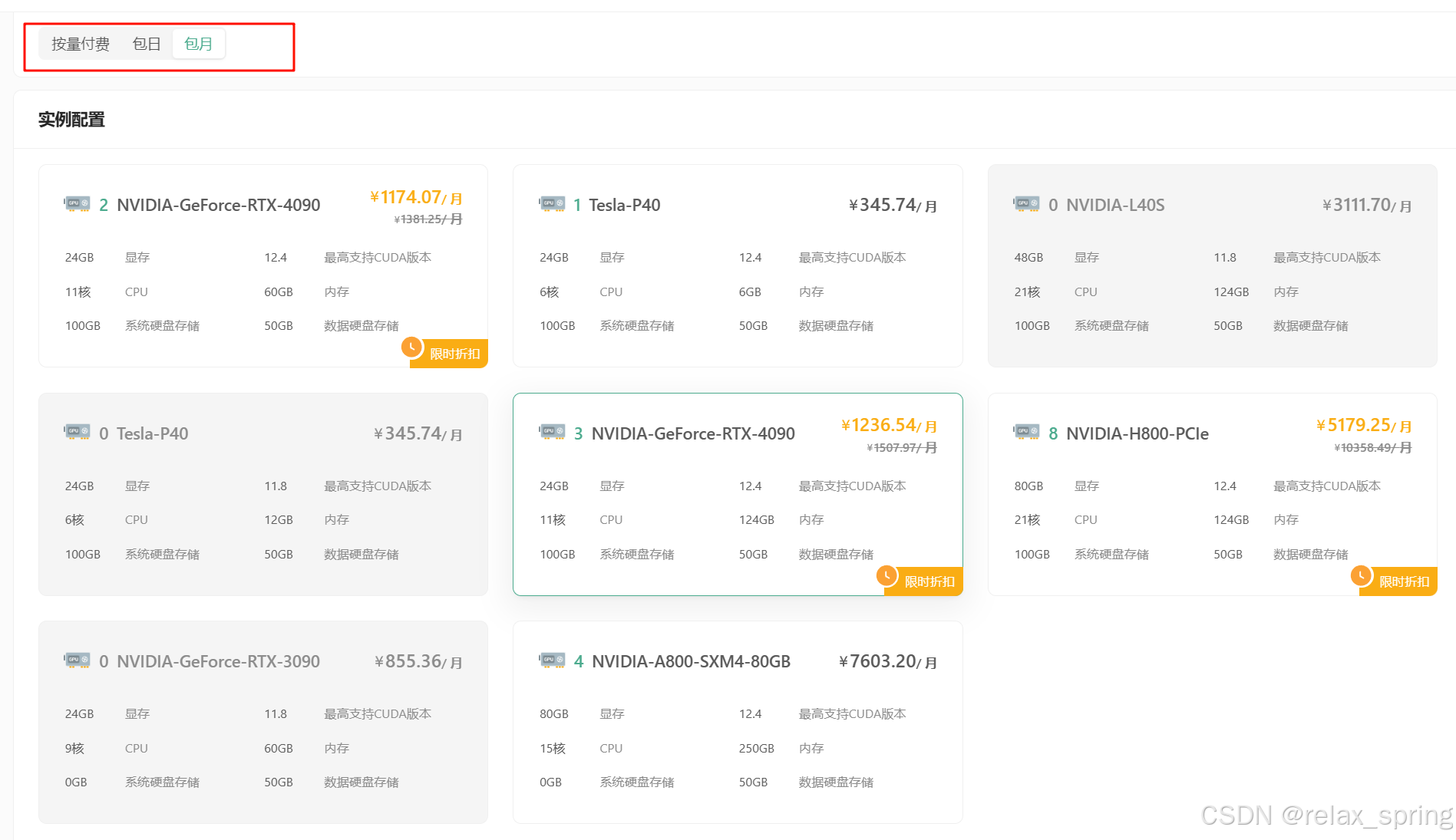
DaModel提供提供了很多实例可供用户选择。
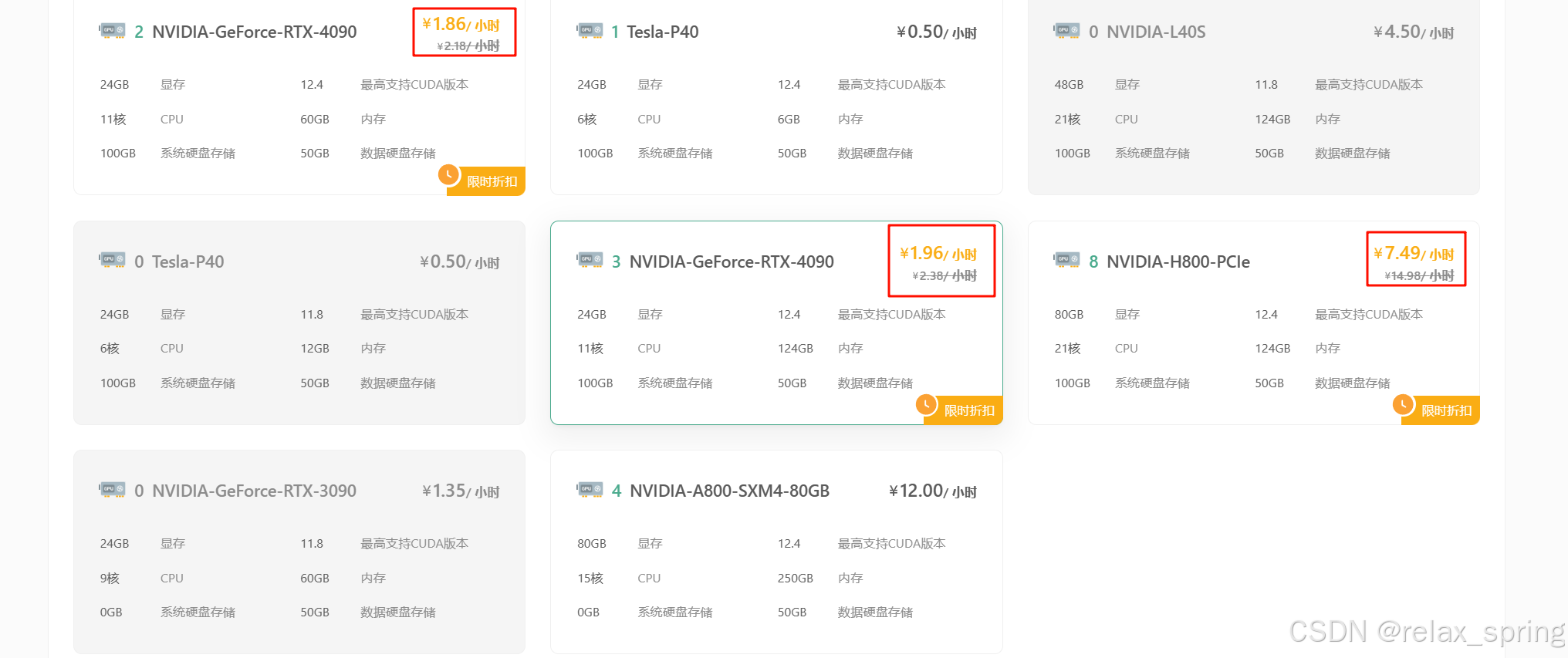
套餐选择
同时DaModel还有多种套餐可供选择,可以根据需求灵活调整配置。
4. 最佳实践
DoModel提供多种快速入门案例,通过案例用户可以快速了解平台服务的使用。

我们以 智谱清影-CogVideoX-2b-部署与使用 案例为例。
CogVideoX 简介
CogVideoX 的核心在于它的 3D 变分自编码器,这项技术能够将视频数据压缩至原来的 2%,极大地降低了模型处理视频时所需的计算资源,还巧妙地保持了视频帧与帧之间的连贯性,有效避免了视频生成过程中可能出现的闪烁问题。
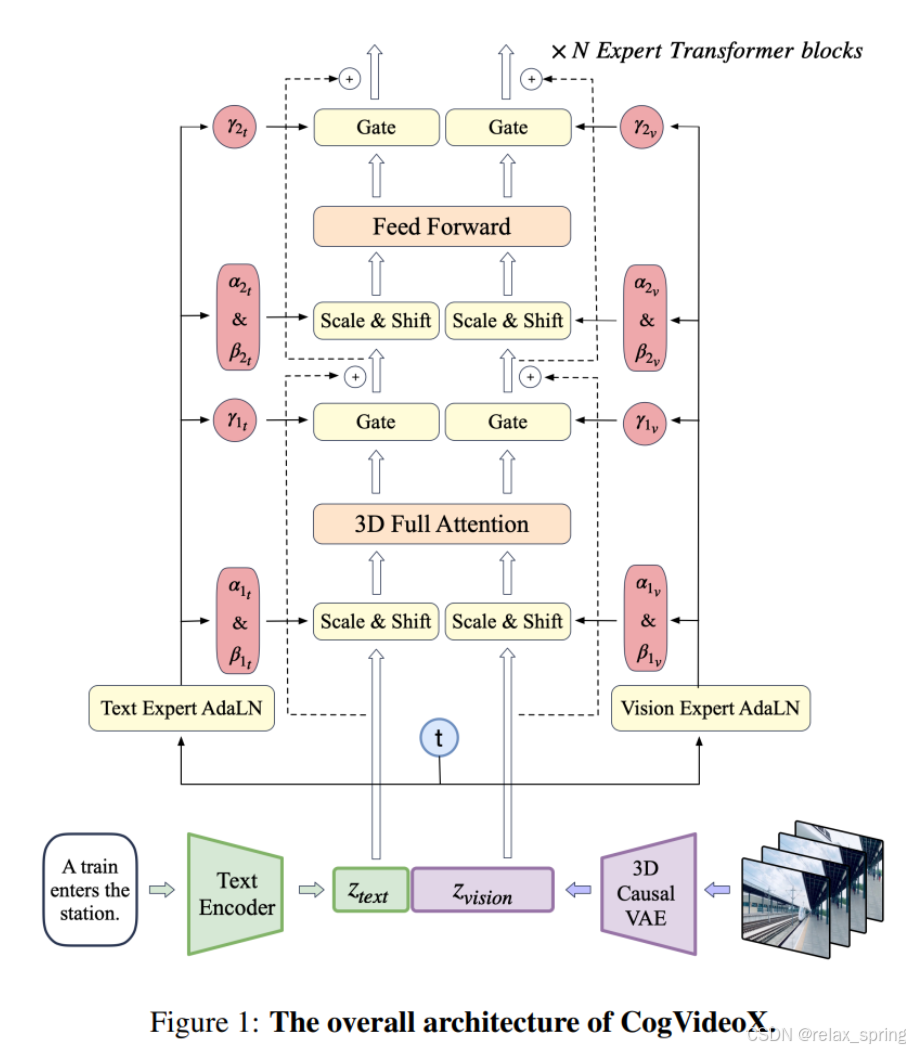
在可控性方面,智谱 AI 研发了一款端到端的视频理解模型,这个模型能够为视频数据生成精确且与内容紧密相关的描述。这一创新极大地增强了 CogVideoX 对文本的理解和对用户指令的遵循能力,确保了生成的视频不仅与用户的输入高度相关,而且能够处理超长且复杂的文本提示。
- 代码仓库:https://github.com/THUDM/CogVideo
- 模型下载:https://huggingface.co/THUDM/CogVideoX-2b
- 技术报告:https://github.com/THUDM/CogVideo/blob/main/resources/CogVideoX.pdf
进入 JupyterLab 后,打开终端,首先拉取 CogVideo 代码的仓库
wget http://file.s3/damodel-openfile/CogVideoX/CogVideo-main.tar下载完成后解压缩CogVideo-main.tar
tar -xf CogVideo-main.tar其次,进入 CogVideo-main 文件夹,输入安装对应依赖:
cd CogVideo-main/
pip install -r requirements.txt以上依赖安装好后,可以在终端输入 python,然后输入以下代码进行测试:
import torch
from diffusers import CogVideoXPipeline
from diffusers.utils import export_to_video5. 其他
DaModel(丹摩用户群 | 帮助文档 - DAMODEL)还创建了官方的用户群,感兴趣的小伙伴可以入群了解详情。

















 6548
6548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









