




本文是有关如何使用 ST Edge AI Developer Cloud 在线平台和服务的分步指南。
- DMZ 是一个物理或逻辑子网,它包含组织面向外部的服务并将其公开给不受信任的、通常更大的网络,例如 Internet。
- ELF 是二进制文件的通用标准格式。
- GUI 代表图形用户界面。
- IOC 是 STM32CubeMX 的项目配置文件。
- K-means 是一种机器学习算法。
- Keras 是一个开源库,为人工神经网络提供 Python 接口。
- MACC 代表乘法累加。
- MATLAB®是一种专有的多范式编程语言和数值计算环境。
- MCU 是 microcontroller unit 的首字母缩写词。
- NPU 是 Neural Processing Unit 的首字母缩写词。
- Netron 是神经网络、深度学习和机器学习模型的查看器。
- npz 是一种用于存储数组的二进制文件格式。
- ONNX 是一个开放的生态系统,为 AI 模型提供开源格式。
- PyTorch 是一个机器学习框架。
- RAM 代表随机存取存储器,即易失性存储器。
- REST API 代表具象状态传输应用程序编程接口。
- scikit-learn 是 Python 编程语言的免费软件机器学习库。
- STM32 模型库是参考机器学习模型的集合,这些模型经过优化,可在 STM32 微控制器上运行。
- 支持向量机 (SVM) 一种机器学习算法。
- TensorFlow Lite 是一个移动库,用于在移动设备、微控制器和其他边缘设备上部署模型。
- TFLiteConverter 是用于将 TensorFlow 模型转换为 TensorFlow Lite 的 API。
- USART 代表通用同步/异步接收器/发射器,它允许设备使用串行协议进行通信。
- X-CUBE-AI 是 STM32Cube 扩展包,是 STM32Cube.AI 生态系统的一部分。
概述
ST Edge AI Developer Cloud (STEDGEAI-DC) 是一个免费的在线平台和服务,支持为基于 Arm Cortex-M 处理器的 STM32 微控制器创建、优化、基准测试和生成人工智能 (AI)。它基于 STEdgeAI-Core 技术。®®
ST Edge AI Developer Cloud 的优势和特点是:
- 在线 GUI(无需安装)可通过 STMicroelectronics 外联网用户凭证访问。
- 网络优化和可视化,提供在 STM32 目标上运行所需的 RAM 和闪存大小。
- 通过将浮点模型转换为整数模型来评估量化的性能。
- STMicroelectronics 托管板场上的基准测试服务,包括各种 STM32 板,以做出最合适的硬件选择。
- 代码生成器,包括网络 C 代码和可选的完整 STM32 项目。
- STM32 模型库:
- 轻松访问模型选择、训练脚本和关键模型指标,直接用于基准测试。
- 来自用户模型的应用程序代码生成器,其中包含 “Getting started” 代码示例。
- 使用 Python 脚本 (REST API) 的机器学习 (ML) 工作流自动化服务。
- 支持 X-CUBE-AI 的所有功能,例如:
- 原生支持各种深度学习框架,例如 Keras 和 TensorFlow Lite,并支持可导出为 ONNX 标准格式的框架,例如 PyTorch、MATLAB 等。®
- 支持 Keras 网络和 TensorFlow Lite 量化网络的 8 位量化。
- 支持各种内置 scikit-learn 模型,例如隔离森林、支持向量机 (SVM)、K-means 等。
- 通过将权重存储在外部闪存中,将激活缓冲区存储在外部 RAM 中,可以使用更大的网络。
- 易于在不同 STM32 微控制器系列之间移植。
- 用户友好的许可条款。
登录
要开始使用该工具,请导航到 ST Edge AI Developer Cloud 的主页,网址为 https://stedgeai-dc.st.com/。此时应显示如下所示的欢迎页面:
当页面完全加载后,单击 “START NOW” 或 “Sign in” 按钮。这会将用户重定向到登录页面,如下所示:
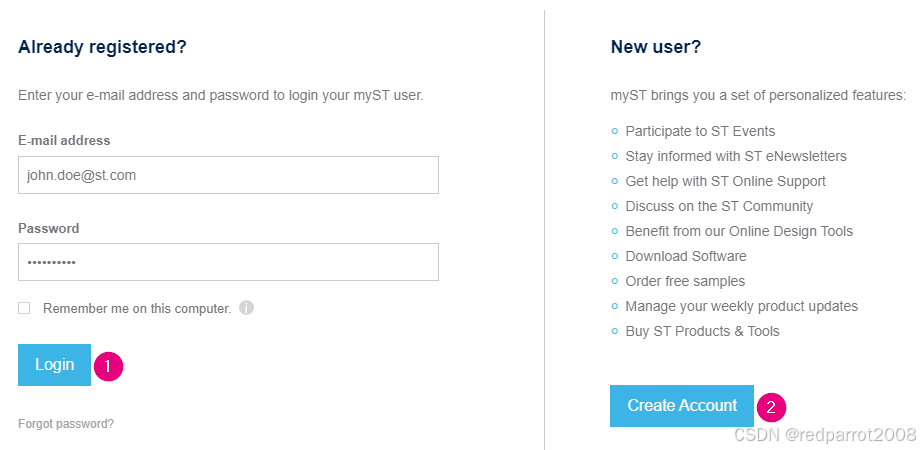
- 如果用户拥有 myST 帐户,他们可以键入其凭据并单击“登录”按钮。
- 如果他们目前没有帐户,他们可以通过单击“创建帐户”按钮并填写所需的表格来创建一个帐户。帐户创建是完全免费的。
信息
使用 ST Edge AI Developer Cloud 需要有效的互联网连接。建议使用稳定的连接,以避免在过程中丢失任何数据。
创建项目
成功登录后,用户将被定向到主页。此页面将三个主要区域分为两组,如下所示:
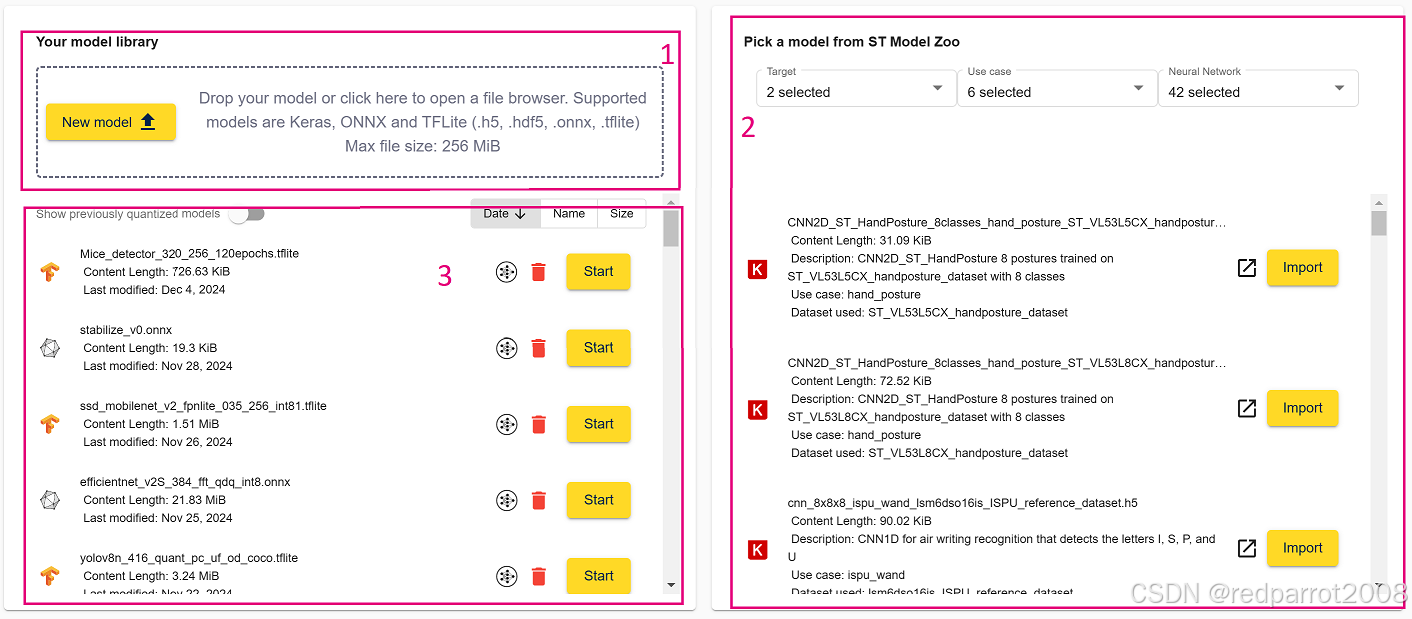
“您的模型库”包括您之前导入的所有模型以及一个可以上传新模型的拖放区。
“从 ST Model Zoo 中选取模型”包括一组来自 ST Model Zoo 的模型,包括一个重定向到自述文件的链接按钮,以了解有关模型属性的更多信息。
上传模型
在第一个区域中,可以通过单击“上传”按钮并从文件资源管理器中选择文件或将其直接拖放到区域中来上传任何预训练的 AI 模型
从 ST Model Zoo 导入
第二个区域显示了预训练的 AI 模型列表,这些模型可用作各种使用案例的起点。这些目前包括八个类别:
- 手部姿势
- 图像分类
- 人类活动识别
- 音频事件检测
- 对象检测
- 语音增强
- 语义分割
- 姿势估计
这些模型源自 STM32 模型库。
要创建新项目,请单击所需模型旁边的“导入”按钮。
使用保存的模型
第三个区域用作工作区,包含用户之前在 ST Edge AI Developer Cloud 中分析和基准测试的所有 AI 模型。
启动项目
本文使用来自 Model Zoo 的 .h5 模型,该模型是使用 TensorFlow Keras API 创建的。要使用该模型,请执行以下步骤:
- 从 Model Zoo 向下滚动模型列表并找到模型。找到后,选择其旁边的“导入”按钮。
CNN2D_ST_HandPosture_8classes_hand_posture_ST_VL53L5CX_handposture_dataset.h5
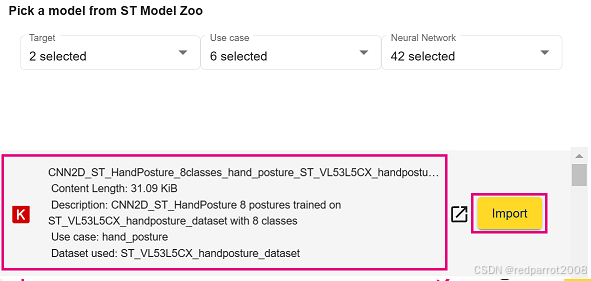
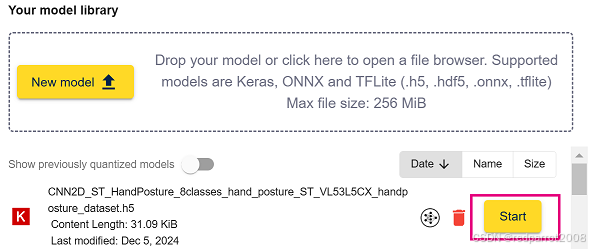
模型现在显示在工作区中。单击 “Start” 按钮创建一个新项目。
2. 单击 “Start” 按钮创建一个新项目。
创建项目后,顶部栏中将提供六个作项:

- Select a platform:选择要使用的平台
- Quantize:使用训练后量化对 float 模型进行量化。
- Optimize:使用不同的选项优化模型。
- 基准测试:在我们的板场的不同 STM32 板上对 AI 模型进行基准测试。
- 结果:查看、分析和比较不同基准测试运行生成的结果。
- Generate:为目标系列和电路板生成代码和项目,以实现优化和基准测试模型。
本页的以下章节提供了有关这些作项的更多详细信息。
此部分还显示当前所选模型的详细信息。这包括相关信息,例如输入和输出形状、类型和 MACC 编号等数据。
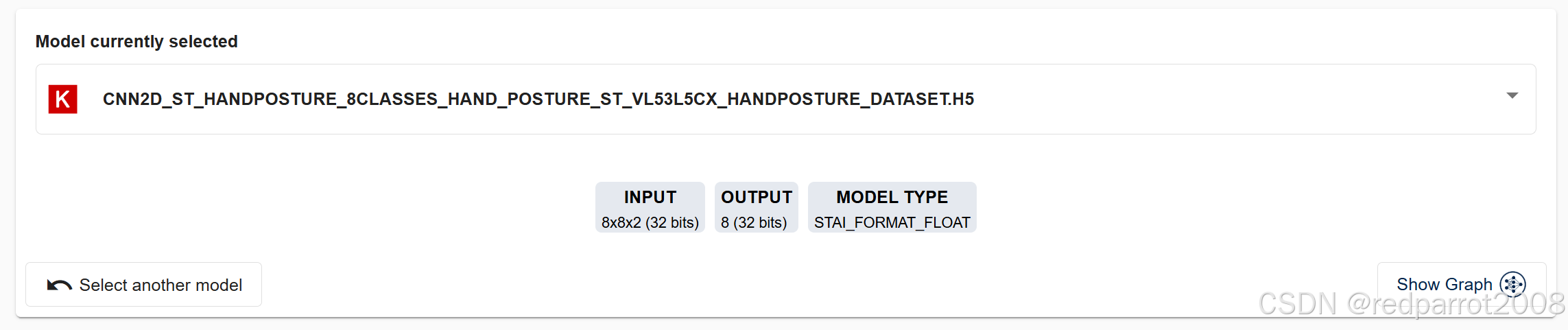
| 信息 |
| 此信息也显示在每个 other作项的部分中。 |
选择您的版本和平台
ST Edge AI Developer Cloud 支持多个版本的后端工具,从 STM32Cube.AI 到当前的 ST Edge AI Core 技术。

选择您的平台选择您的平台
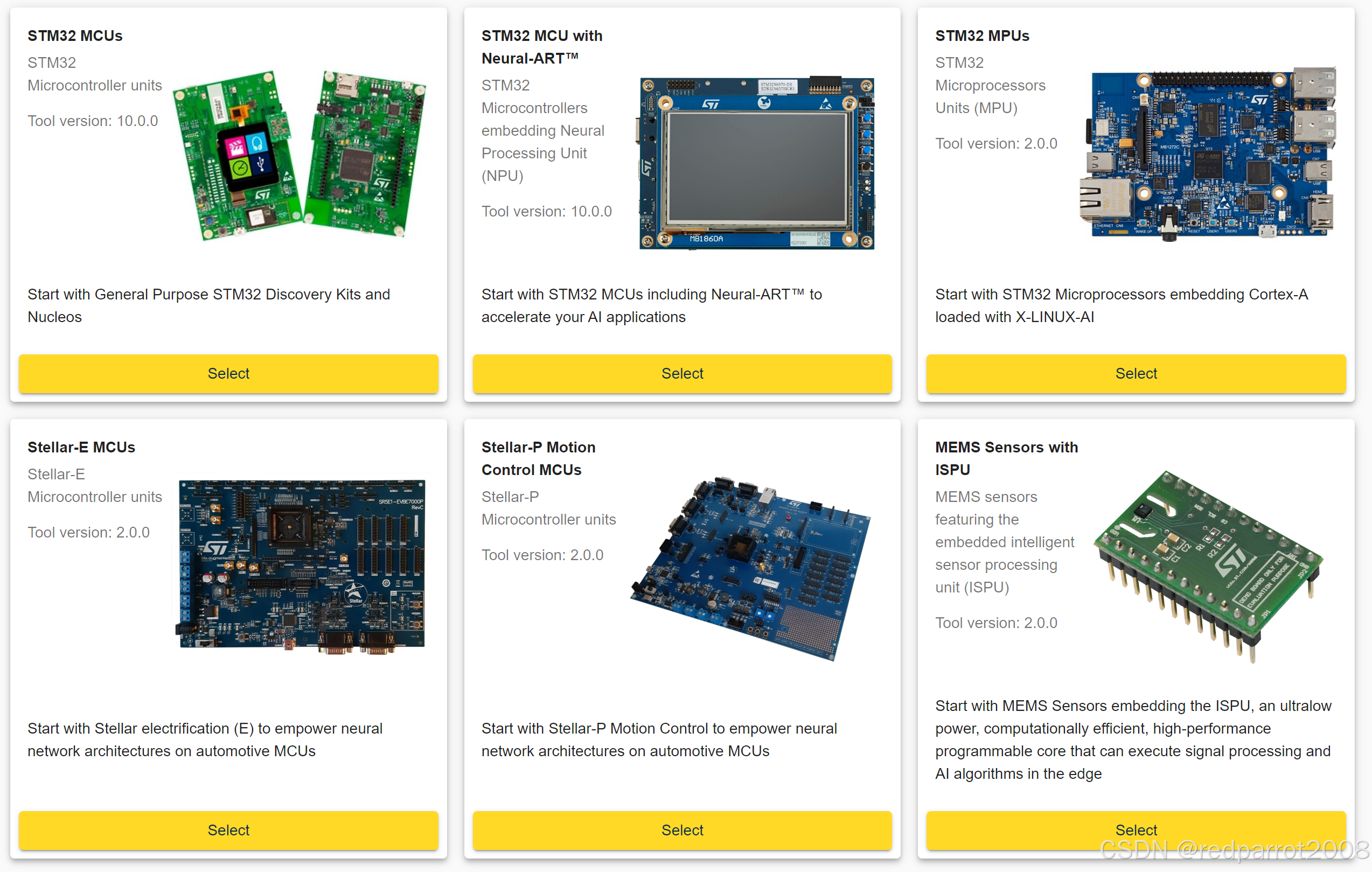
在下一步之前,根据您选择的版本,您可以选择要使用的平台:
- STM32 MCU:从通用 STM32 探索套件和 Nucleos 开始
- STM32 NPU:从包含 Neural-ART™ 的 STM32 MCU 开始,加速您的 AI 应用
- STM32 MPU:从嵌入 Cortex-A 的 STM32 微处理器开始,加载了 X-LINUX-AI
- Stellar 平台:从 Stellar-E 或 Stellar-PG 开始,为汽车 MCU 上的神经网络架构提供支持
- 带 ISPU 的 MEMS 传感器:从嵌入 ISPU 的 MEMS 传感器开始,ISPU 是一种超低功耗、计算效率高、高性能的可编程内核,可以在边缘执行信号处理和 AI 算法
量化
此面板可用于从 Keras 浮点模型创建量化模型(8 位整数格式)。量化是一种优化技术,用于压缩 32 位浮点模型,方法是减小模型的权重大小(较小的存储大小和运行时的内存峰值使用量),提高 CPU/MCU 的使用率和延迟(包括功耗),并可能降低准确性。量化模型对具有整数而不是浮点值的张量执行部分或全部运算。
量化服务使用 TFLiteConverter 提供的 TensorFlow 训练后量化接口。从三个支持的选项中选择任何输入或输出类型,包括 int8、unsigned int8 或 float32。为了防止量化过程中的精度损失,建议用户提供他们的训练数据集或其中的一部分。这可以以 .npz 文件的形式提供。如果未提供量化文件,则将使用随机数据进行量化,生成的量化模型只能用于基准测试,以获得必要的 flash 和 RAM 大小以及推理时间,但不计算准确性。
提供数据集的 .npz 文件后,单击 “Launch quantization” 按钮开始量化过程。此演示在没有数据集的情况下使用随机数进行量化。
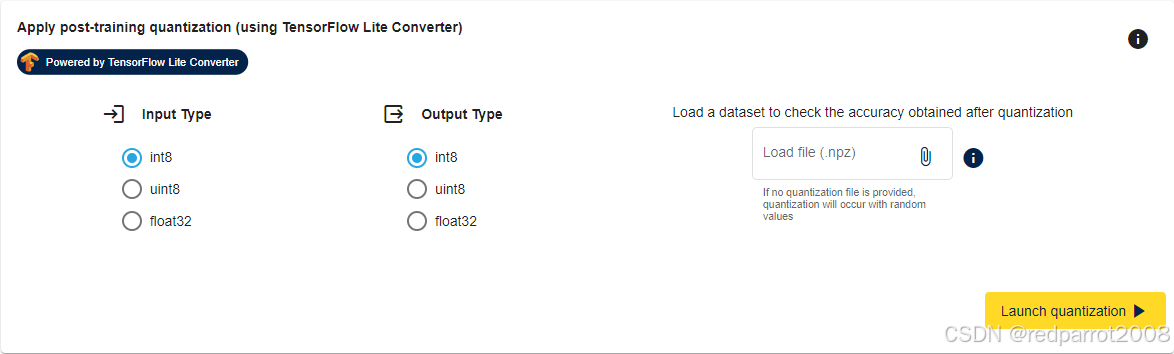
量化过程完成后,量化模型如下所示。点击 “Select” 按钮将您当前的模型更改为量化的模型
优化量化模型后,“History of optimization results” 表显示结果。在此示例中,与执行的默认分析相比,应观察到优化后闪存和 RAM 大小减少了约 70%:
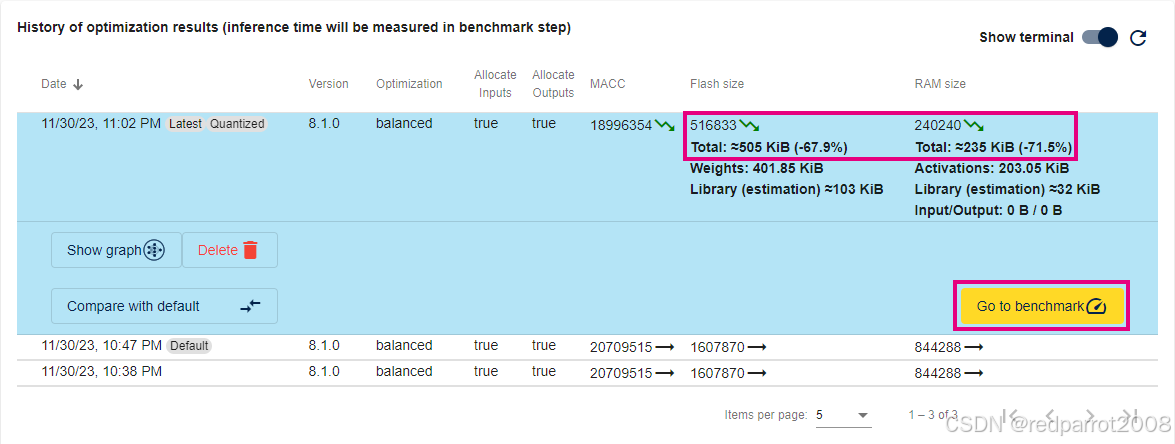
对量化结果满意后,单击 “Go to benchmark” 按钮,将用户带到模型基准测试步骤。
优化
在 optimize 部分中,使用 balanced optimization 选项执行默认优化。这将启用“use activation buffer for input buffer”和“use activation for output buffer”。您可以修改默认设置并单击“优化”以观察影响。
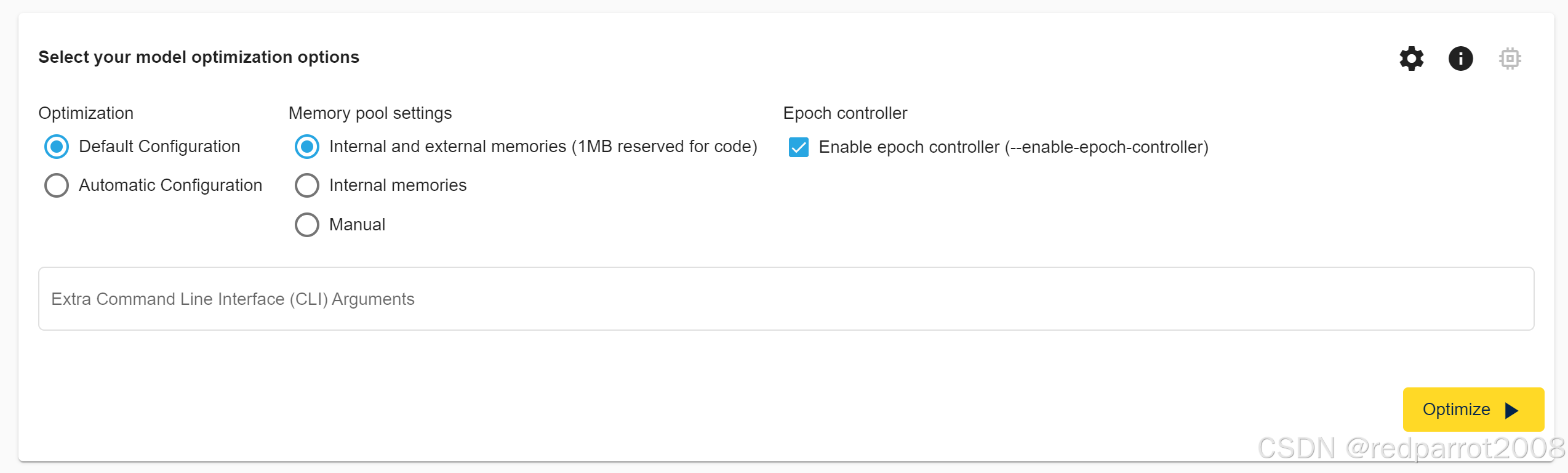
优化选项 (STM32 NPU)
在优化部分中,选择了嵌入在 ST Edge AI Core 中的默认优化配置文件。您可以选择内存配置文件,以便使用可用于 STM32N6 的整个内存范围,包括用于应用程序的 1MB 内部内存和完全内部内存。您可以修改默认设置并单击“优化”以观察影响。
Epoch 控制器选项允许使用 epoch 控制器启用代码生成,针对 ST Neural-ART(tm) 加速器进行了优化,从而提高性能。
TIP:
这种优化基于无数据集方法,这意味着不需要训练、验证或测试数据集即可应用压缩和优化算法。有关更多信息,请参阅 UM2526。
优化选项(STM32 MCU、Stellar-E、Stellar-PG、ISPU)
有三个不同的选项可用于优化 AI 模型:
- RAM 大小和推理时间之间的平衡:这种方法试图在最小 RAM 和最短推理时间之间找到一个平衡点。
- 优化 RAM 大小:此方法旨在优化 RAM 大小。
- 优化推理时间:此方法旨在优化推理时间。
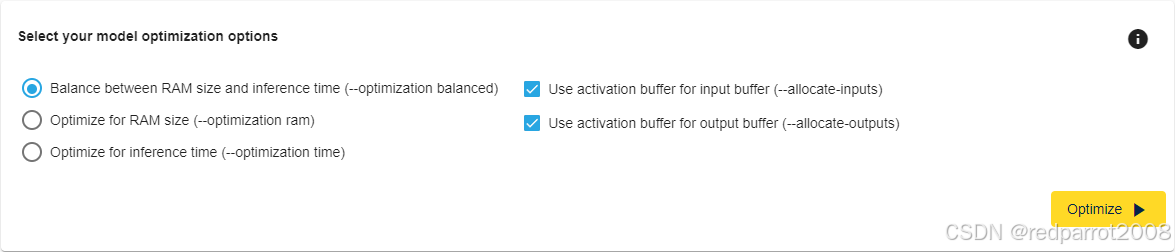
默认情况下,选择平衡选项是为了在最小的占用空间和尽可能短的推理时间之间为用户提供最佳折衷方案。
将激活缓冲区用于输入/输出缓冲区
启用这些选项后,它表示 “activations” 缓冲区也用于处理 input/output 缓冲区。这会影响内存,但不会影响推理时间。根据输入/输出数据的大小,“激活”缓冲区可能更大,但总体上小于激活缓冲区加上输入/输出缓冲区的总和。
要启动优化过程,请选择所需的选项,然后单击“优化”按钮。在优化运行时,用户可以监视终端,该终端提供有关优化运行的详细信息。此处显示任何错误。
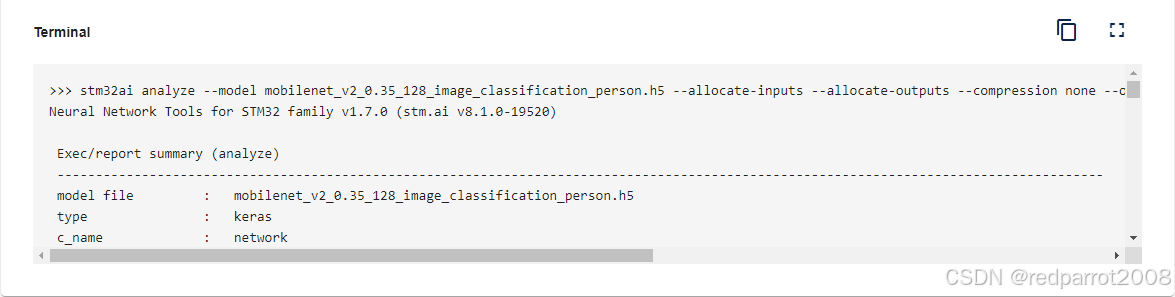
可以通过选择不同的选项来启动多个优化,允许用户选择最适合他们需求的选项。 每次优化作后,终端都会显示 MACC 、 flash 大小和 RAM 大小等报告的数字。
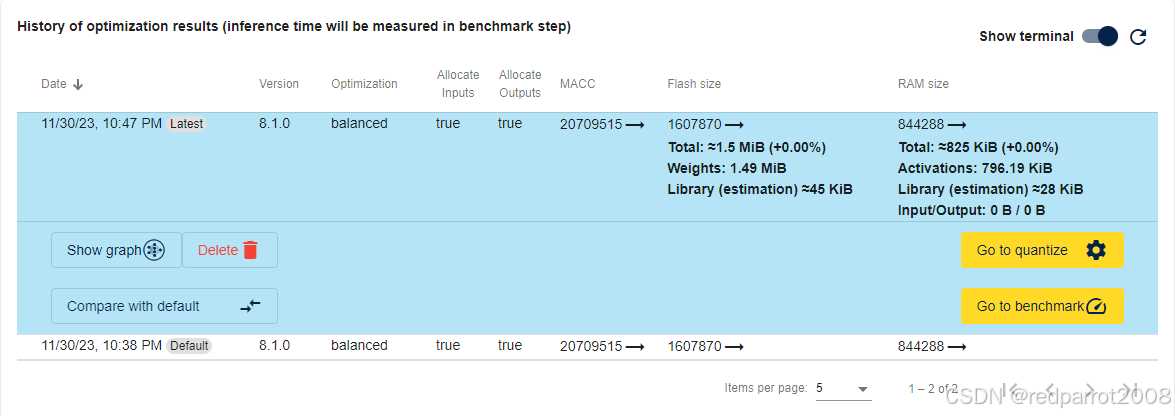 执行所有优化后,用户可以选择最适合其需求的选项。此示例使用平衡方法。从这里,用户可以继续执行下一个作项。
执行所有优化后,用户可以选择最适合其需求的选项。此示例使用平衡方法。从这里,用户可以继续执行下一个作项。
基准测试基准
Benchmark 面板显示当前选定的模型,以及用于优化的当前参数,如下图所示。
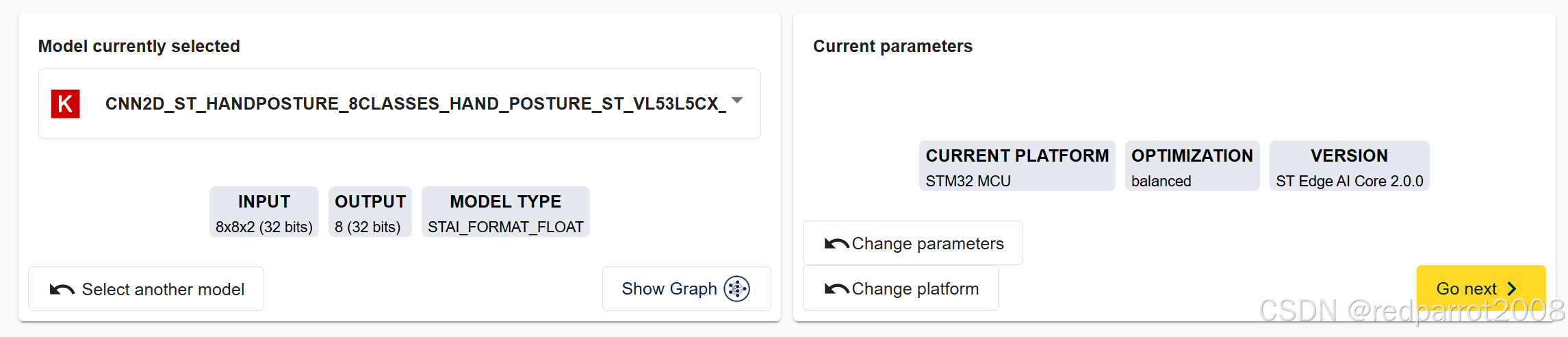
基准测试服务允许用户在多个 STM32 板上远程运行选定的 AI 模型,并获取内部或外部闪存和 RAM 使用情况,以及推理时间。这些STM32板卡托管在意法半导体的场所,称为“板场”,可通过等待队列访问。该面板列出了一些基本的电路板信息,包括 CPU 类型和频率,以及内部和外部内存大小:
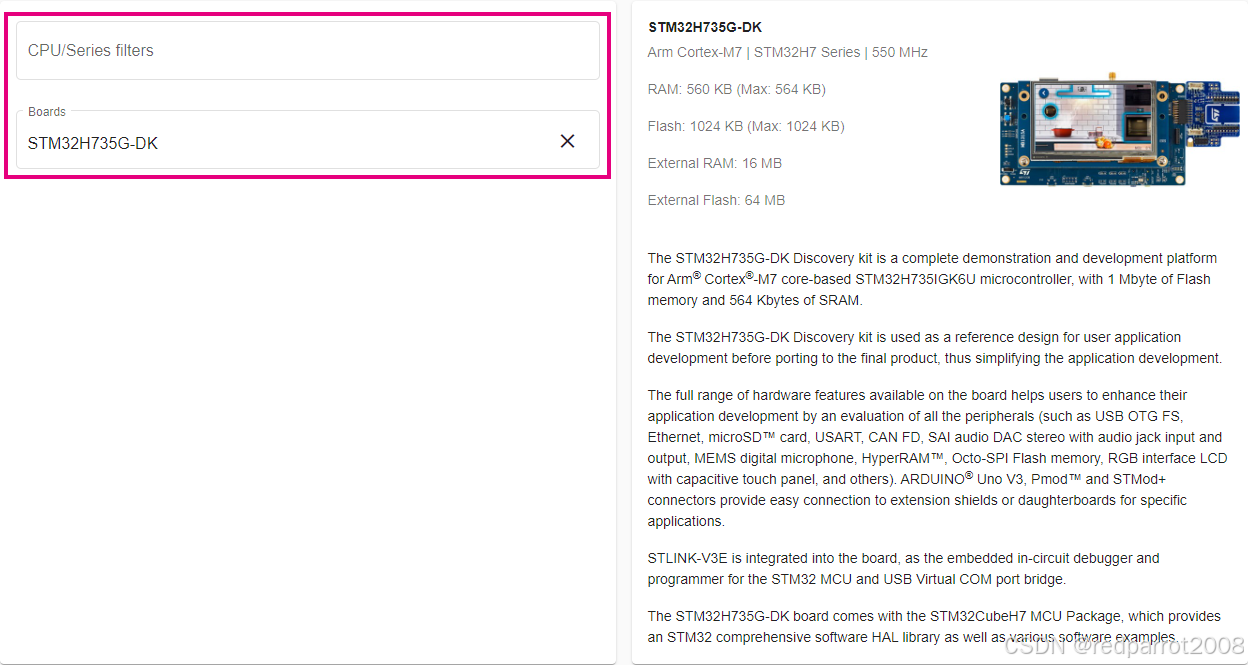
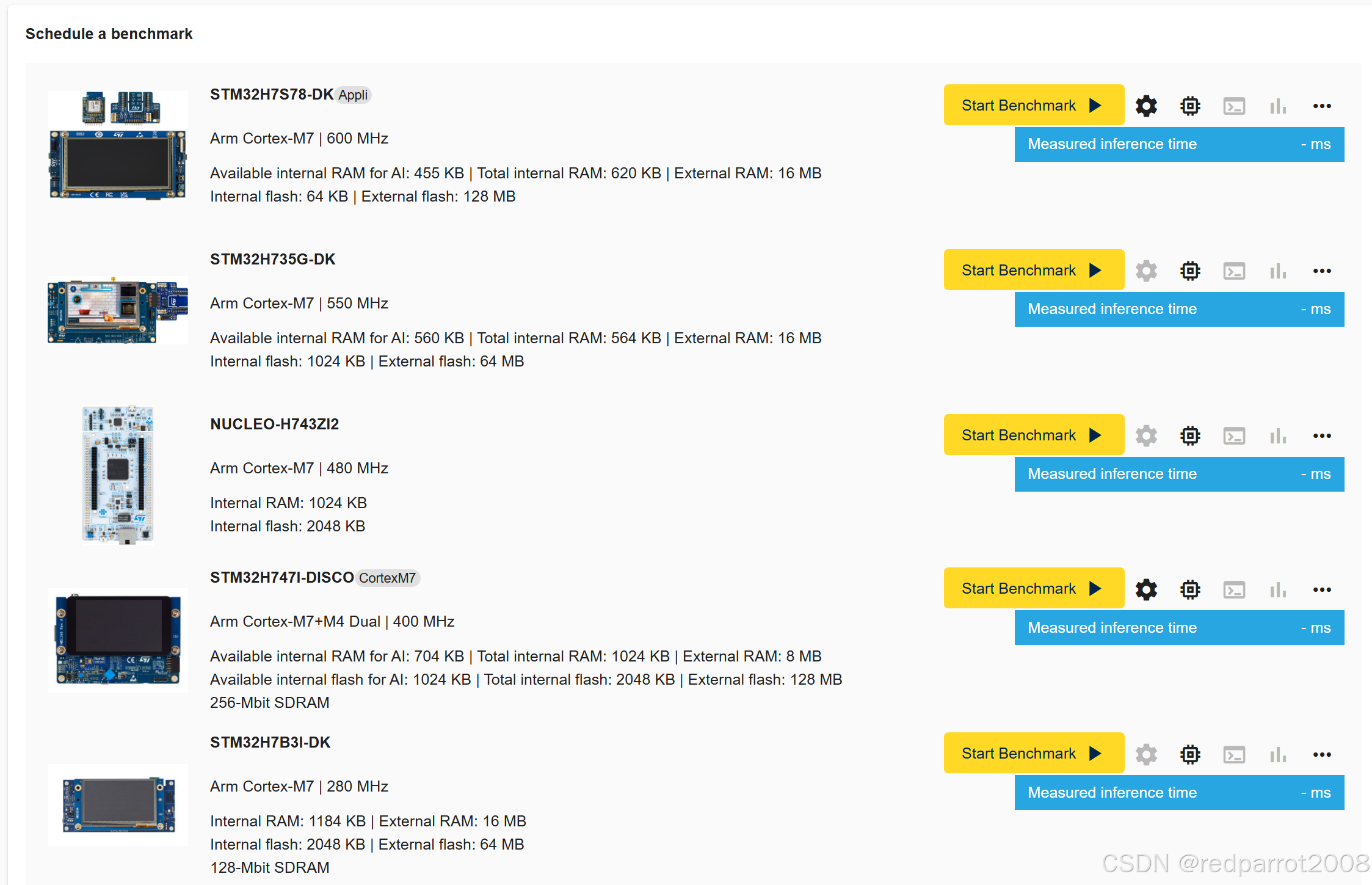 要在给定的开发板上启动 Benchmark,请单击该开发板旁边的 “Start Benchmark” 按钮。这将启动基准测试过程。本文中的示例使用 STM32H735G-DK 板。
要在给定的开发板上启动 Benchmark,请单击该开发板旁边的 “Start Benchmark” 按钮。这将启动基准测试过程。本文中的示例使用 STM32H735G-DK 板。
TIPS:如果所选模型所需的内存大小超过板上的可用内存,则“Start Benchmark”按钮将变灰。
在基准测试过程中,用户可以实时观察进度条和当前状态。将创建用于系统性能应用程序的项目。该工具使用 AI 模型的 C 代码构建项目,并对板场中的一块实际物理板进行编程。它在开发板上运行应用程序,并为用户提供内存占用和推理时间。

基准测试完成后,测得的推理时间将显示在板子旁边,如下所示。
要获取有关每个层使用的资源的更多详细信息,请单击与“Show details per layer”选项对应的“三条”图标。此时将显示一个包含相应条形图的对话框。
条形图以字节为单位显示每个层的大小。用户可以通过单击“切换饼图/条形图”按钮在条形图和饼图之间切换。条形图显示实际大小,而饼图显示分布。

用户可以对执行时间执行相同的作。条形图显示每个层所花费的持续时间(以毫秒为单位),而饼图显示每个层的执行时间分布。要关闭此视图,请单击对话框外的任意位置。
该工具允许用户同时在多个板上启动基准测试。他们可以通过按下所有 “Start Benchmark” 按钮在所有板上启动基准测试。这将对所有板重复该过程,并报告它们旁边的所有板的推理时间。
完成所有基准测试运行后,用户可以继续执行“结果”步骤。
TIPS:信息
没有必要在所有 Board 上运行基准测试。如果对其中一个基准测试感到满意,请直接单击 “three-dot” 图标并选择 “Generate code for this board”。这将跳过“Results”步骤,直接进入“Generate”步骤。
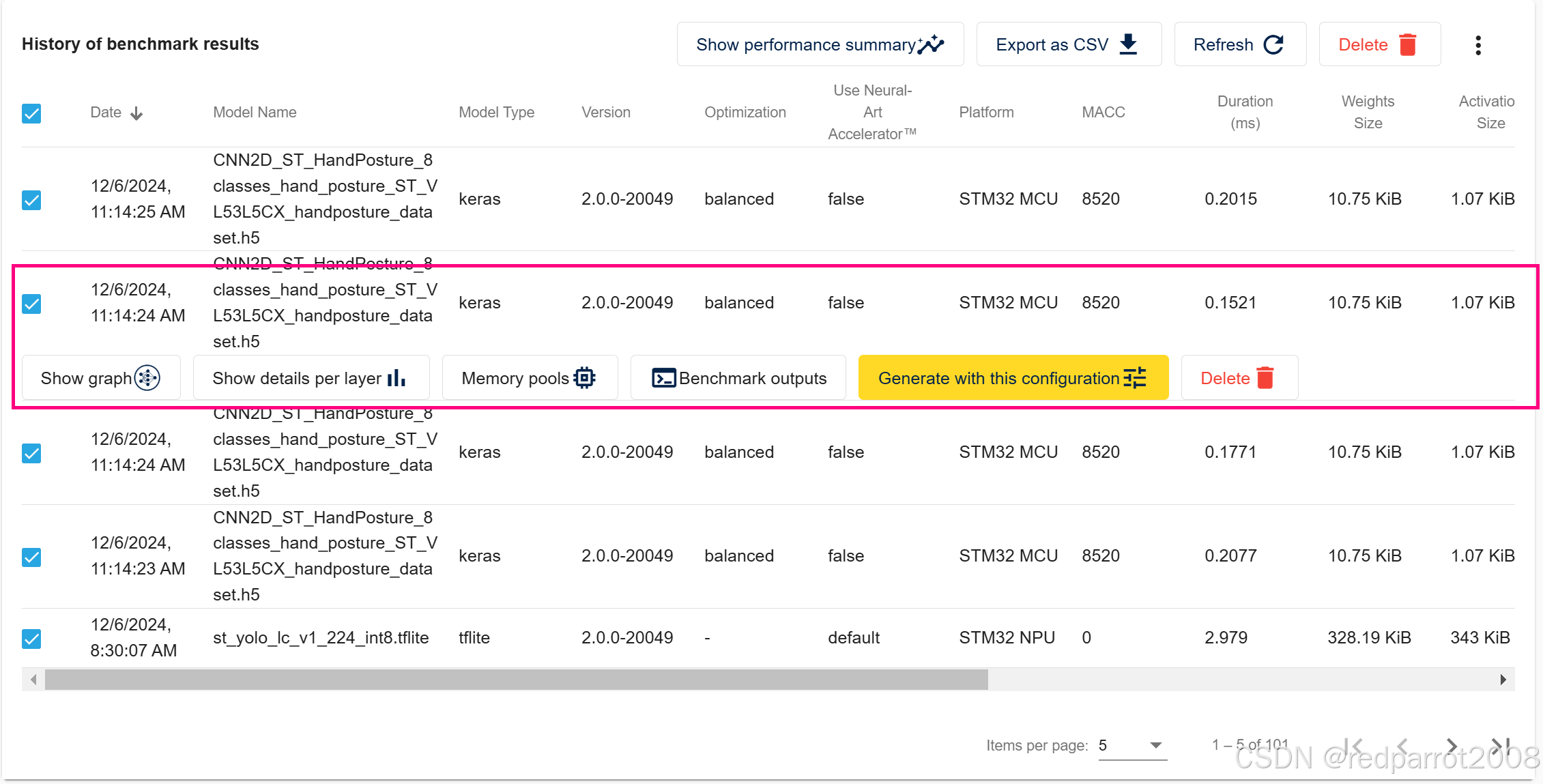
结果
“结果”页面显示了在 ST Edge AI Developer Cloud 中执行的所有基准测试的表格,这对于比较所有基准测试很有用。用户可以通过单击 “Generate with this configuration” 按钮直接选择用于代码生成的基准测试。
本演示使用 STM32H735G-DK 板,可提供最短的推理时间。
生成
“生成”页面提供了满足不同需求的各种输出。这些作包括更新现有项目、创建新的 STM32CubeMX 项目、生成包含所有源代码的 STM32CubeIDE 项目,或下载编译后的固件以估计用户自己电路板上的推理时间。
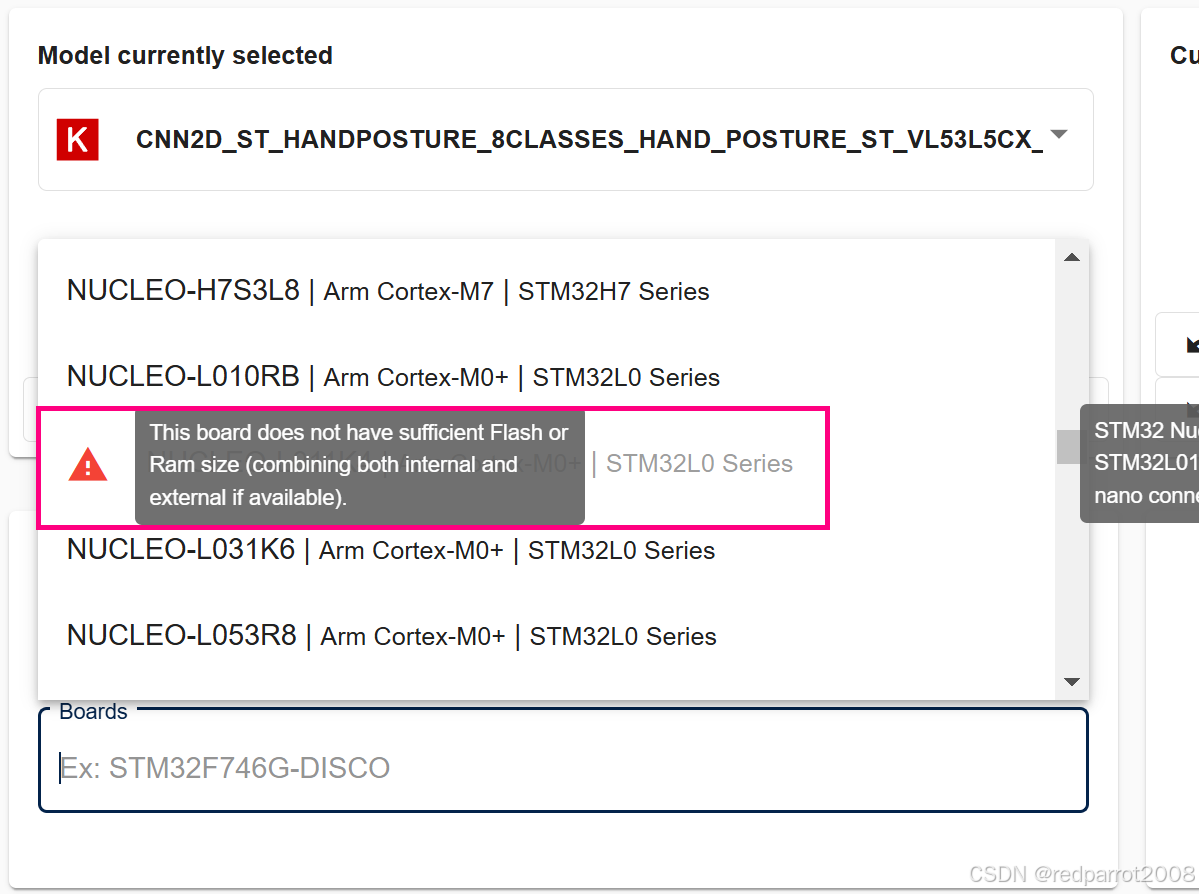
当用户到达 “Generate” 步骤时,他们会看到当前所选模型和当前参数的相同标题。如果来自基准测试或结果步骤,则目标板已被选中。否则,用户需要筛选 CPU 类型或 STM32 系列以选择其目标 STM32 板。
如果要查找的板子灰显并在左侧显示红色三角形,则表示您的模型需要的 RAM 或 Flash 多于此目标上的可用 RAM。
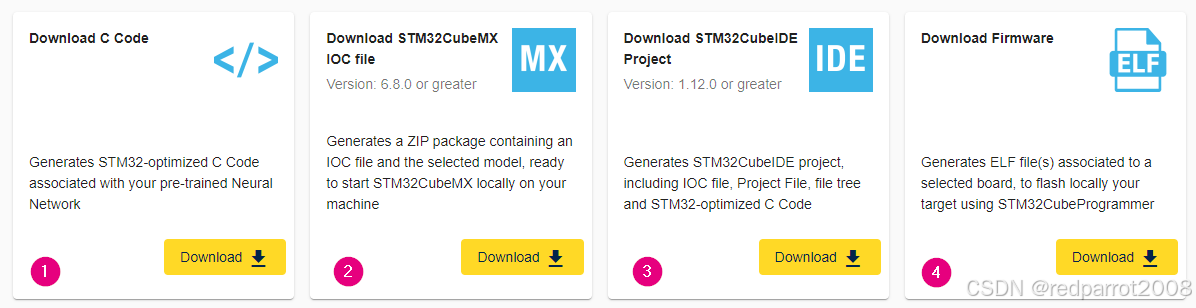
在此之后,用户有四个生成选项可供选择:
- 下载 C 代码
- 下载 STM32CubeMX IOC 文件
- 下载 STM32CubeIDE 项目
- 下载固件
下载 C 代码
此选项生成与用户的预训练神经网络关联的 STM32 优化 C 代码。.zip 包包含所有网络 .c 和 .h 文件、Cube.AI 运行时库文件以及 stm32ai 命令行报告和输出。用户可以将这些新生成的文件替换其项目中的现有文件。
下载 STM32CubeMX IOC 文件
此选项会生成一个包含 IOC 文件和所选模型的 .zip 包,该包已准备好在用户计算机上本地启动新的 STM32CubeMX 项目。用户可以使用 STM32CubeMX v6.6.1 或更高版本打开 IOC 文件,然后直接生成代码或添加其应用程序所需的其他外设。
下载 STM32CubeIDE 工程
此选项使用 STM32CubeIDE 项目生成一个 .zip 包,其中包括 ioc 文件、项目文件、文件树和 STM32 优化的 C 代码:
- Board 是选定的 Board。
- 在项目中激活 X-CUBE-AI,并选择系统性能应用程序。
- 神经网络模型在项目中配置,并在 .zip 包中提供。
- 系统性能应用程序所需的 USART 已配置完毕。
- 生成 STM32CubeIDE 项目以及所有代码和库。
用户可以通过双击包中的 .project 文件,使用 STM32CubeIDE v1.10.0 或更高版本打开项目。
将项目导入 STM32CubeIDE 后,用户可以编辑代码或直接在自己的板上编译和烧录程序。
下载固件
此选项生成与所选板相关的 ELF 文件,可以使用 STM32CubeProgrammer 直接在用户自己的板上编程。在应用程序上启用了系统性能应用程序。
AI 系统性能应用程序是一个自一体机和裸机设备应用程序,允许对生成的神经网络的关键系统集成方面进行开箱即用的测量。精度性能方面在这里没有也不能考虑。报告的测量值包括通过推理实现的 CPU 周期数(持续时间(以毫秒为单位)、CPU 周期数、CPU 工作负载)、已用堆栈和已用堆(以字节为单位)。


















 1030
1030

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









