





在TCP/IP(二)- TCP/IP通识 一文中,我们提到了两个关键字:吞吐量和传输速率,大家还记得吧,这一篇我们简单分析一个性能拆机案例:
传输速率:指单位时间物理传输量;
吞吐:指单位时间内实际的传输速率;
这里我们拆解一个Wi-Fi7性能传输差的实例;
首先,我们明确下影响吞吐的因素;
外部因素:
(1)网卡,网卡的最大速率直接限制了wifi的极限,例如如果一个网卡的速率仅支持1G,那么即使路由最大速率支持2.5G,也只能达到1G的极限;
(2)CPU处理能力,数据传输都需要经过CPU处理交给二三层进行处理,因此CPU的能力也直接影响到吞吐的性能;
(3)环境嘈杂度,主要影响占空比,如果环境太嘈杂,就会存在信道竞争,从而影响最终的速率;
(4)天线角度
...
内部因素:
(1)天线OTA性能、传导性能,这里就是和接收灵敏度强相关,涉及到射频、天线等硬件性能指标;
(2)带宽,从某种意义上说,速率就是带宽,带宽越大,速率越高;
(3)数据报文中数据字段的长度,根据概念就可以知道,单位时间内传输的数据量越大,吞吐就越大,数据的长度也受到TXOP的影响,不同国家这个配置一般不同,我们测试极限时一般使用US国家码;
(4)GI,帧间隙,可以看这里What is GI;
(5)调制解调
(6)制式,可以看这里速率
(7)空间流,1*1或者2*2对于速率都是翻倍的影响;
(8)coding
(9)发射功率,功率大小会影响射频EVM指标,不过也不是功率越大越好;
(10)wifi扫描等行为,这是一个有扫描的吞吐曲线
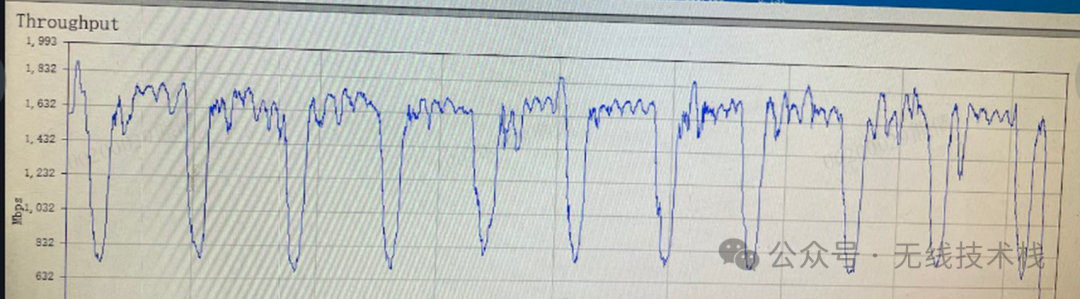
(11)BTC行为,在2.4G频段下,BTC会分时工作,因此性能也会减低,根据不同的业务场景,分时比例不一样;
...
问题:
手机与路由测试Wi-Fi7 mlo性能时,频段连接是5.2G_160M 5.8G_80M(2882Mbps + 1441Mbps),RX无法达标,TX ~ 3.4G,RX ~ 2.9G左右(注意这里设备是支持HBS的)
前置条件:
(1)屏蔽室环境 + 路由2*2
(2)性能脚本,带入一些优化(这个脚本大家如果需要可以私信小编,包括RPS、自动化禁止扫描、自动化吞吐、tcp优化...)
拆解过程:
外部因素确认:
(1)首先,尝试调整天线角度以及拉锯,找到一个性能最佳的角度;
(2)选择一个相对干净的网络环境;
(3)确认网卡的速率支持大于wifi的极限速率;
内部因素确认:
(1)确认带宽、GI、空间流、信号强度、调制解调(Wi-Fi7支持了4k,速率对应MCS13)等符合预期;
(2)排除UDP/TCP差异,尝试先测试UDP性能,因为UDP是无连接型的,性能会比TCP好;
(3)对比单link速度之和与MLO差异,因为双5G有邻频之间的干扰,测试数据如下:
路由配置:2*2(以下测试均配置2*2)1.单link数据5.2G 160MTCP RX:2.05G 2.07G 2.10GUDP RX:2.08G 2.10G 2.11G5.8G 80MTCP RX:路由2*2 ==》982M,路由4*4 ==》920MUDP RX: 路由2*2==》1.06G ,路由4*4 ==》980M2.mlo吞吐数据TCP TX:3.34G(iperf3)TCP RX:2.82G 2.80G 2.85GUDP RX:2.83G 2.80G 2.89GTX功率5dB之后 + 路由2*2:1.单link数据:5.2G 160M:TCP RX: 2.0G 1.9GUDP RX:2.06G5.8G 80M:TCP RX:1.05G 1.08GUDP RX:1.15G 1.16G双link数据:TCP RX:2.89G整体上看手机侧降功率没有提升,并且手机侧稳定在MCS13时,极限吞吐2.9G,仍然相差TX300M左右。
(4)切换信道
切换信道ch40 + ch165测试数据:无改善;
(5)测试Wi-Fi6e 4K
wifi6路由5.2G/5.8G测试数据:性能均优于WIFI7;
测试到这里我们知道与外部环境关系不大,主要差异还是性能本身跑不上去;
进一步拆解:
如果不知道怎么下手,最简单的方法就是拿到一份性能正常的日志信息进行一一对比,看看有哪些差异项:
手机+路由测试,自身RX差TX 300M~500M,相比手机自身TX/RX聚合包数量对比:
(1)聚合包数量,这里就是看单位时间内数量的传输量
//手机TX 3.4G聚合包数量9k
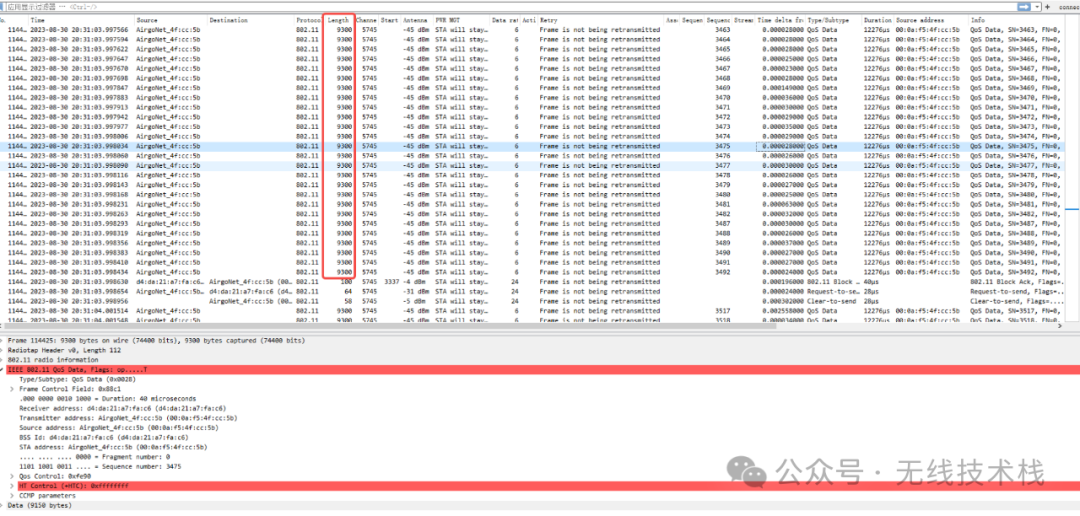
//手机RX聚合包数量3k
这里最初的报文丢失了,口头描述一下
(2)MCS
确认TX/RX是否都可以达到MCS13,这里各家厂商都有不同的确认方式,看log确认就好;
(3)GI确认,可以通过空口确认;
优化方案:
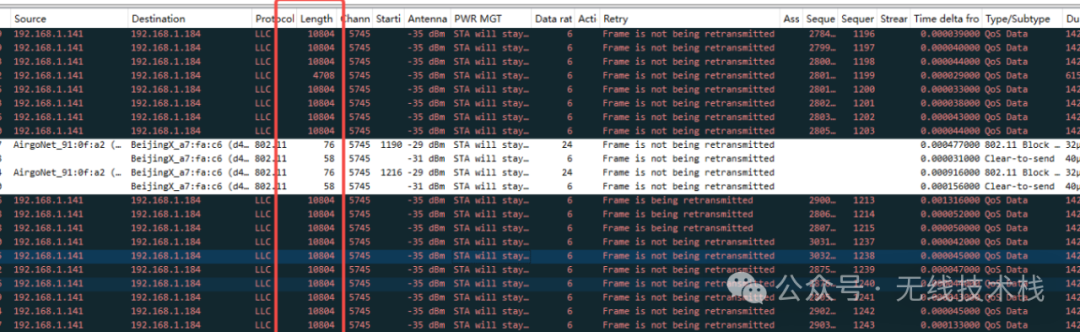
(1)调整聚合包长度
wifitool wl0 setUnitTestCmd 0x48 2 65 6;wifitool wl1 setUnitTestCmd 0x48 2 65 6;wifitool wl2 setUnitTestCmd 0x48 2 65 6
修改手机侧BA-size为1k,Wi-Fi7最大支持1k,参考这里Wi-Fi技术简介(八)-- Wi-Fi7技术解析
调整后生效,截图如下:
(2)调整天线
路由侧天线配置4*4存在互扰,极限性能下需要调整2*2//chainmask即时生效,但重启后无效的命令:cfg80211tool wifi1 txchainmask 3;cfg80211tool wifi1 rxchainmask 3;cfg80211tool wifi2 txchainmask 3;cfg80211tool wifi2 rxchainmask 3;//chainmask重启后仍然生效的命令:uci set wireless.wifi1.txchainmask=3uci set wireless.wifi1.rxchainmask=3uci set wireless.wifi2.txchainmask=3uci set wireless.wifi2.rxchainmask=3uci commitWifi
(3)调整功率
实际测试,在手机RX稳定在MCS13时,路由侧功率调整10dB ~ 15dB,性能较优iwconfig wl0 txpower 10;iwconfig wl2 txpower 15
(4)修改空口配置TXOP
//设置路由TXOPwifitool ath0 setUnitTestCmd 0x47 4 170 0 0 8000wifitool ath1 setUnitTestCmd 0x47 4 170 0 0 8000wifitool ath2 setUnitTestCmd 0x47 4 170 0 0 8000//手机侧可以通过修改国家码达到目的
(5)手机侧一些协议栈的调优,小编加到了工具脚本里,有需要的私信小编获取;
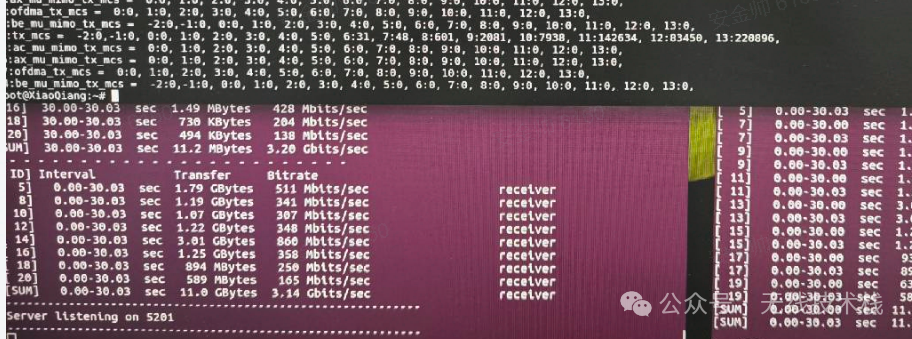
优化结果:
最后极限数据3.2G左右,最高3.29G,几乎与TX持平
通过这个问题得到的优化项目:
1.双端聚合包长度优化,这里不同平台有一些不同的接口,可以根据场景动态设置;
2.路由默认功率对于手机侧较高需要调整路由功率才能测试到极限,路由+路由测试性能3.1G~3.3G,我们后续拆解下手机/路由差异,这里增加一个动态设置功率的接口,争对一些场景进行优化;
3.5+5mlo场景,路由+路由较容易稳定在MCS13,性能最优可以测到3.25G,手机对于方向比较敏感,单路测试容易稳定在MCS13,双路时极难都稳定在MCS13,性能最优可以达到3.2G,需要排查下手机/路由天线方向性和互扰差异;
如果读到这里,你觉得有所收获,就关注下小编的公众号,未来一起进步~



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









