create table IF NOT EXISTS course_score
(
id string,
userid string,
course string ,
score int ,
term string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
stored as textfile
;
加载数据并查看原始数据
hive> load data local inpath './s.txt' overwrite into table course_score;
Loading data to table default.course_score
Table default.course_score stats: [numFiles=1, totalSize=243]
OK
Time taken: 0.463 seconds
hive> select * from course_score;
OK
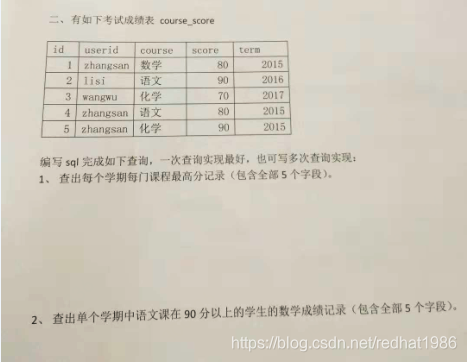
1 zhangzhan shuxue 80 2015
2 lisi yuwen 92 2016
3 wangwu huaxue 70 2017
4 zhangsan yuwen 80 2015
5 zhangsan huaxue 90 2015
6 lisi shuxue 85 2015
7 wangwu yuwen 99 2016
8 zhangsan huaxue 80 2017
9 wangwu yuwen 90 2016
Time taken: 0.193 seconds, Fetched: 9 row(s)
每个学期每门功课分数
> select * ,row_number() over(partition by course,term order by score desc) rn from course_score ;
Query ID = hdfs_20181203130505_05b33809-9aff-4cc6-abd6-bf4ee34dd54b
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks not specified. Estimated from input data size: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Kill Command = /opt/cloudera/parcels/CDH-5.14.2-1.cdh5.14.2.p0.3/lib/hadoop/bin/hadoop job -kill job_1541413124518_0075
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-12-03 13:05:38,842 Stage-1 map = 0%, reduce = 0%
2018-12-03 13:05:44,037 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 1.98 sec
2018-1





 本文提供两个row_number() over()的使用示例。首先展示了一个查询每个学期每门功课最高分的情景,接着介绍了如何在分组学期的基础上,筛选出语文成绩90分以上且对应用户数学科目记录的场景。涉及到的数据操作包括建表、数据加载、分组和过滤。
本文提供两个row_number() over()的使用示例。首先展示了一个查询每个学期每门功课最高分的情景,接着介绍了如何在分组学期的基础上,筛选出语文成绩90分以上且对应用户数学科目记录的场景。涉及到的数据操作包括建表、数据加载、分组和过滤。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









