



 文章讲述了在尝试使用学长在Windows环境下训练的darknet权重文件时,在Linux系统中遇到的‘Assertion‘0’failed.’错误。问题源于Windows与Linux的换行符差异。解决方案是使用vi编辑器,设置文件格式为unix,然后保存,从而修复权重文件使其在Linux环境下正常工作。
文章讲述了在尝试使用学长在Windows环境下训练的darknet权重文件时,在Linux系统中遇到的‘Assertion‘0’failed.’错误。问题源于Windows与Linux的换行符差异。解决方案是使用vi编辑器,设置文件格式为unix,然后保存,从而修复权重文件使其在Linux环境下正常工作。
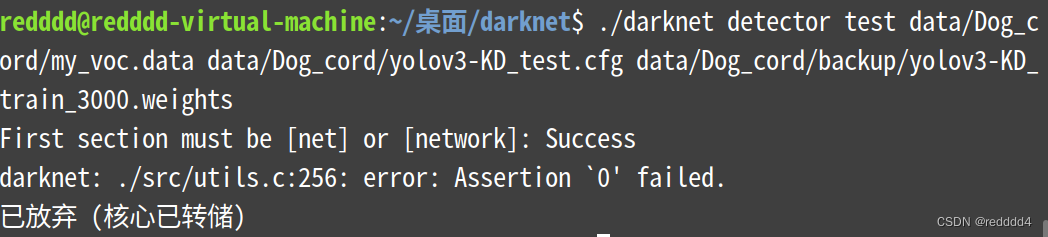
今天借学长的权重文件试用,又出现了新的错误:
First section must be [net] or [network]: Success
darknet: ./src/utils.c:256: error: Assertion `0' failed.
已放弃 (核心已转储)
出现这个问题是因为学长是在Windows下训练的darknet。在Windows下换行符是\n\r,而Linux下则是\n,所以就会有多出来的\r。学长Windows下的权重文件在我的Linux系统里不能被识别。
解决办法:
1.在权重文件目录下打开终端,打开文件,如:输入vi ./yolov3-KD_test.cfg

此时进入文本编辑器,大概长这样:
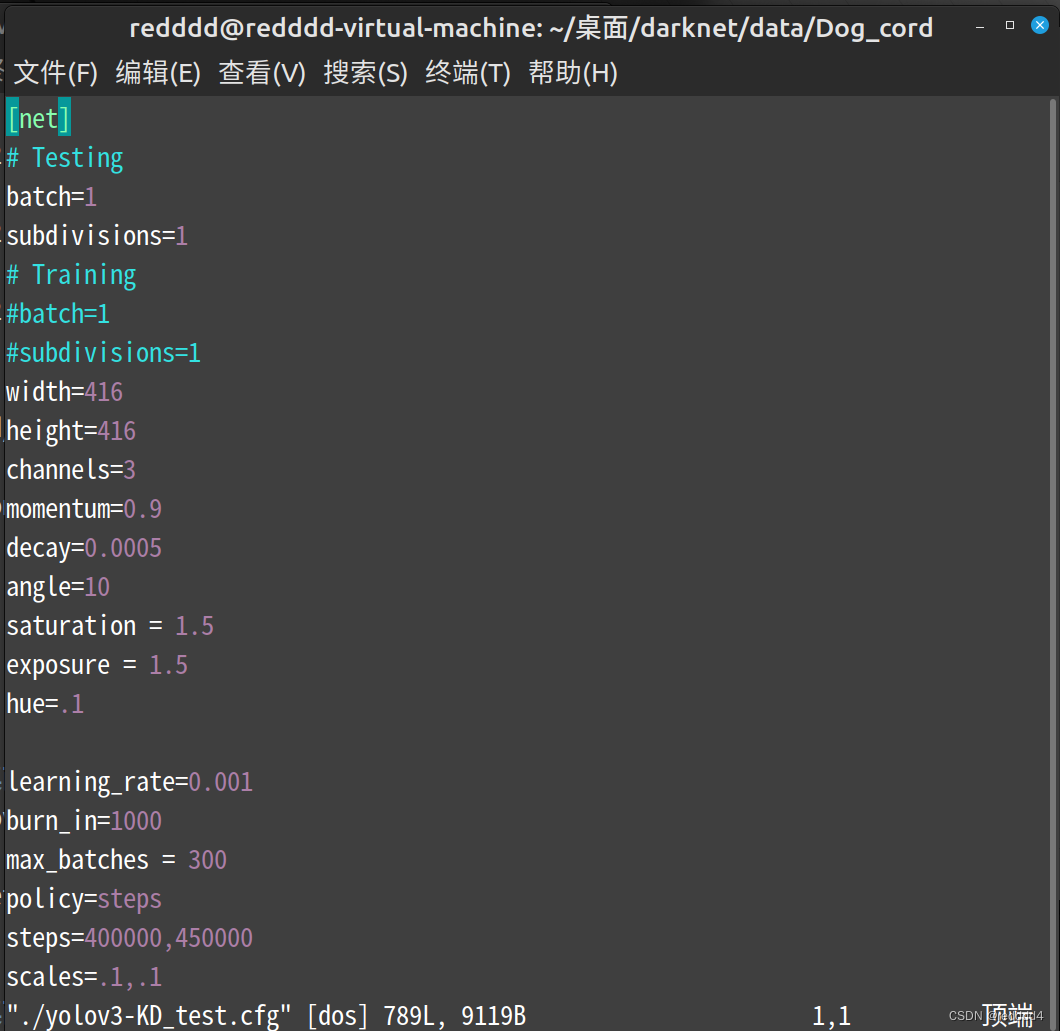
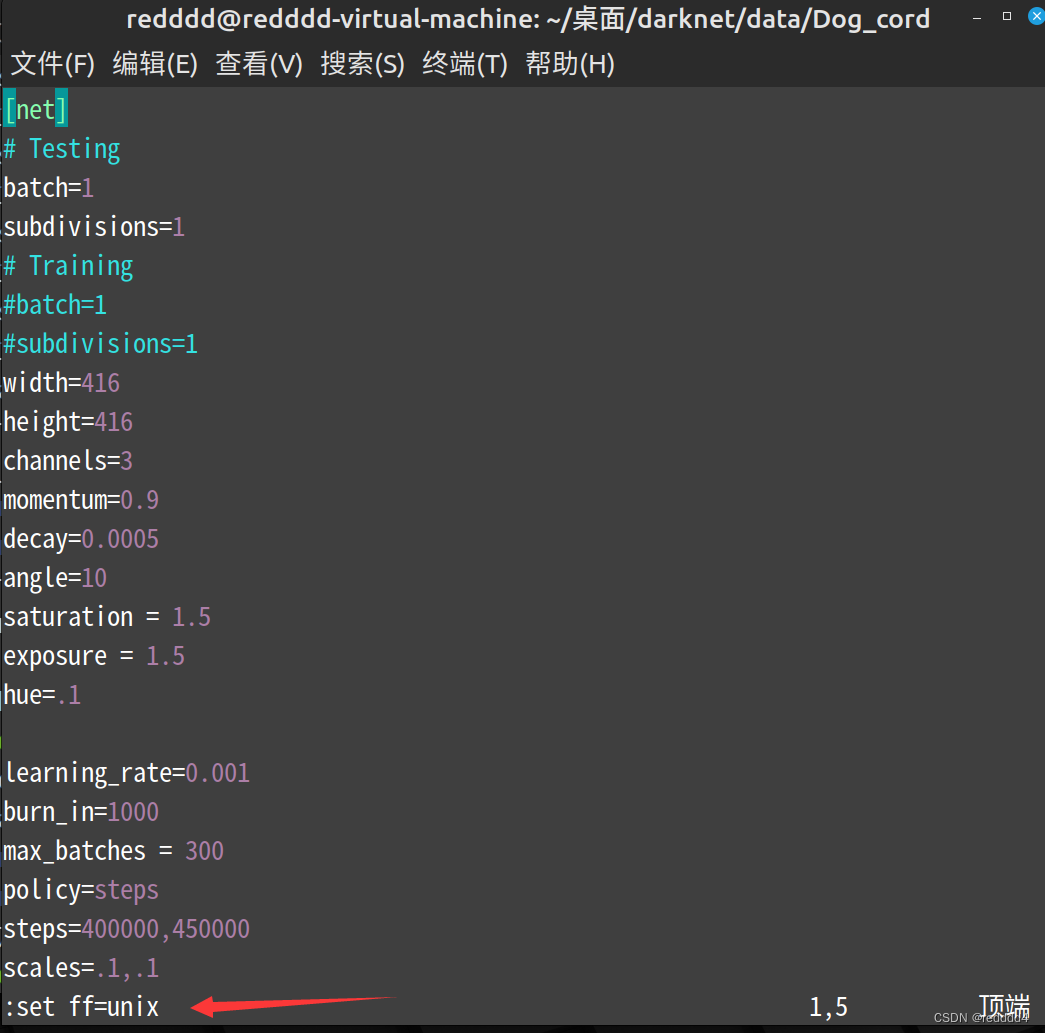
2.输入命令,注意前面的冒号
: set ff=unix
然后按回车
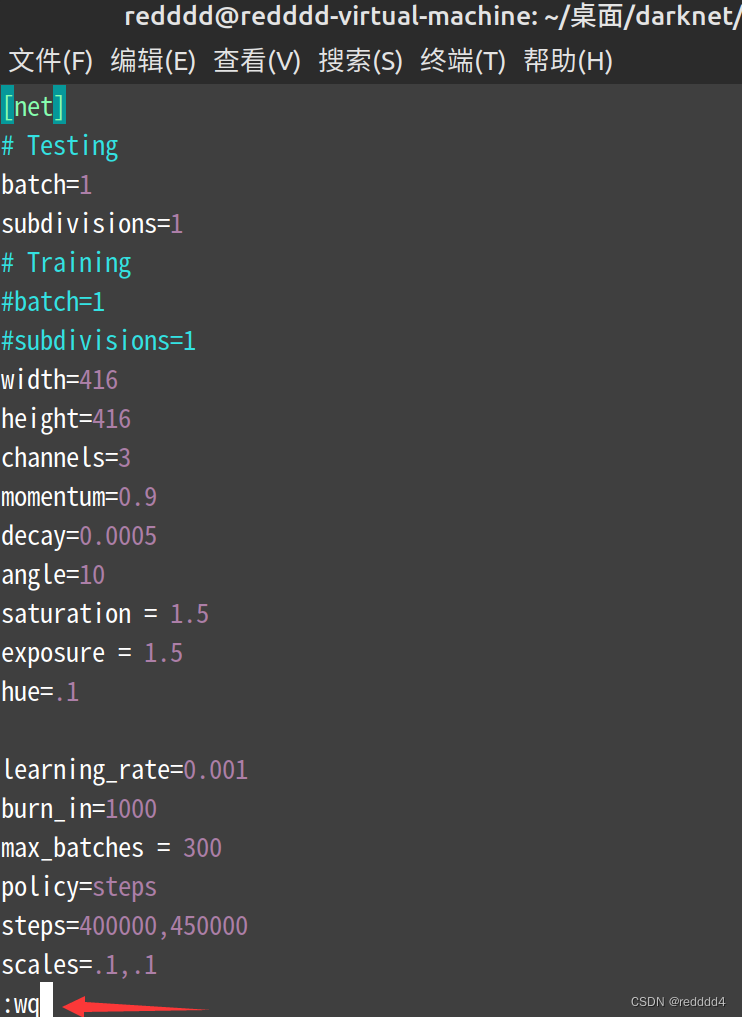
3.输入:wq,保存离开
:wq
再在darknet中打开终端,重新输入验证命令:

可以看到已经解决问题啦。
参考网址:

















 2317
2317

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









