







 本文探讨了Web安全中的信息收集阶段,涵盖robots.txt、网站备份泄露、Git、DS_store、SVN和WEB-INF/web.xml可能导致的安全隐患。通过Zoomeye、Bing和Fofa等搜索引擎的使用技巧,以及站长工具的查询方法,帮助读者掌握信息收集的实用方法。
本文探讨了Web安全中的信息收集阶段,涵盖robots.txt、网站备份泄露、Git、DS_store、SVN和WEB-INF/web.xml可能导致的安全隐患。通过Zoomeye、Bing和Fofa等搜索引擎的使用技巧,以及站长工具的查询方法,帮助读者掌握信息收集的实用方法。

为了更好服务大家在课程中遇到问题,每期我们都会进行一些问题交流和解答。启程2班人额现在已满,请加启程3班-工具系列。如果在看视频过程中,遇到相关问题,可以在论坛(http://bbs.sec-redclub.com/hr/forum.php?mod=viewthread&tid=32&extra=page%3D1)进行提问,相关贴主会对问题进行解答。或者直接加群进行讨论。由于群里只允许讨论和技术相关话题,或者转发技术贴,闲聊一律会被请出去。

信息收集
信息收集一般都是渗透测试前期用来收集,为了测试目标网站,不得不进行各种信息收集。信息收集要根据不同目标进行不同方向收集,工具部分会在下节课程进行讲解,根据个人渗透测试经验总结文章。本文只是抛砖引玉,希望可以给大家一个好的思路。如果文章中有环境搭建部分,靶场后续会在公众号中发布。视频在关注公众号以后,回复我要视频,管理员会在最快时间进行回复。
首先公开上一节中一张图,开始今天主题讲解。
信息收集思维导图
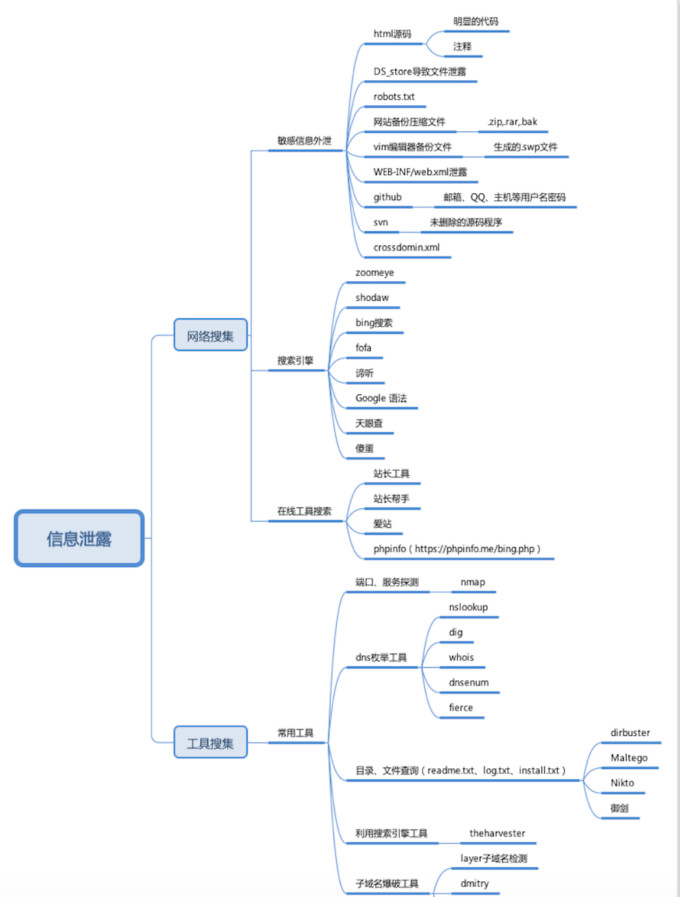
信息收集
1、robots.txt
当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。
robots.txt基本上每个网站都用,而且放到了网站的根目录下,任何人都可以直接输入路径打开并查看里面的内容,如http://127.0.0.1/robots.txt ,该文件用于告诉搜索引擎,哪些页面可以去抓取,哪些页面不要抓取。
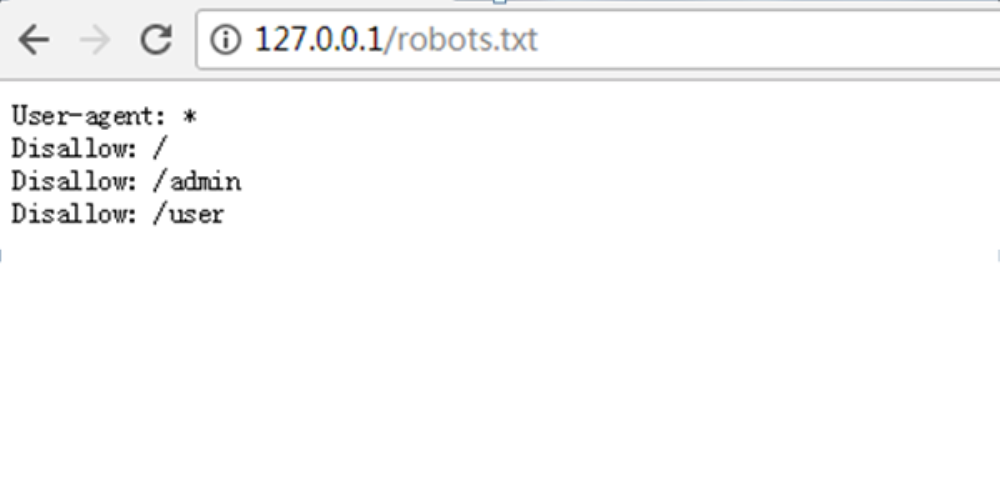
robots.txt防黑客,为了让搜索引擎不要收录admin页面而在robots.txt里面做了限制规则。但是这个robots.txt页面未对用户访问进行限制,可任意访问,导致可通过该文件了解网站的结构,比如admin目录、user目录等等。
怎样即使用robots.txt的屏蔽搜索引擎访问的功能,又不泄露后台地址和隐私目录呢?
有,那就是使用星号(/*)作为通配符。举例如下:
User-agent:*
Disallow: /a*/这个设置,禁止所有的搜索引擎索引根目录下a开头的目录。当然如果你后台的目录是admin,还是有可以被人猜到,但如果你再把admin改为adminzvdl呢?
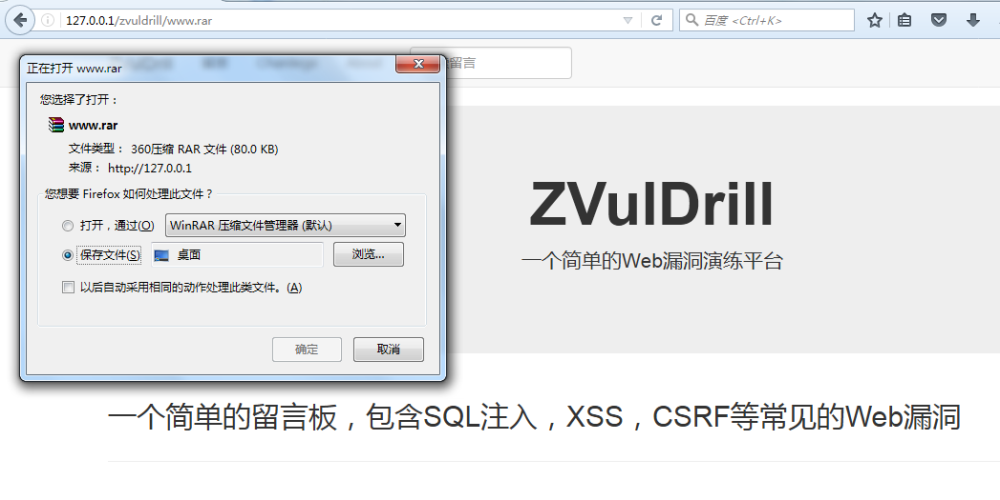
2、网站备份压缩文件
管理员在对网站进行修改、升级等操作前,可能会将网站或某些页面进行备份,由于各种原因将该备份文件存放到网站目录下,该文件未做任何访问控制,导致可直接访问并下载。可能为.rar、zip、.7z、.tar.gz、.bak、.txt、.swp等等,以及和网站信息有关的文件名www.rar、web、rar等等
3、Git导致文件泄露
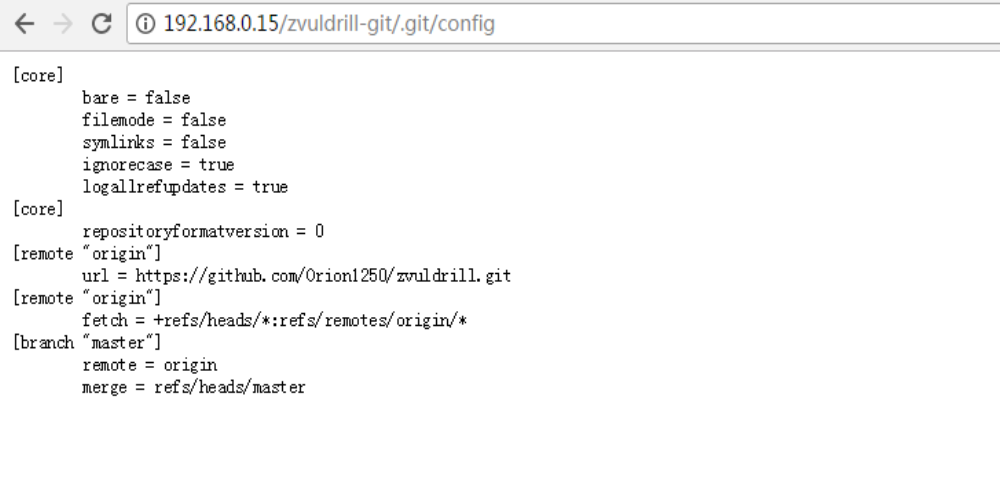
由于目前的 web 项目的开发采用前后端完全分离的架构:前端全部使用静态文件,和后端代码完全分离,隶属两个不同的项目。表态文件使用 git 来进行同步发布到服务器,然后使用nginx 指向到指定目录,以达到被公网访问的目的。
在运行git init初始化代码库的时候,会在当前目录下面产生一个.git的隐藏文件,用来记录代码的变更记录等等。在发布代码的时候,把.git这个目录没有删除,直接发布了。使用这个文件,可以用来恢复源代码
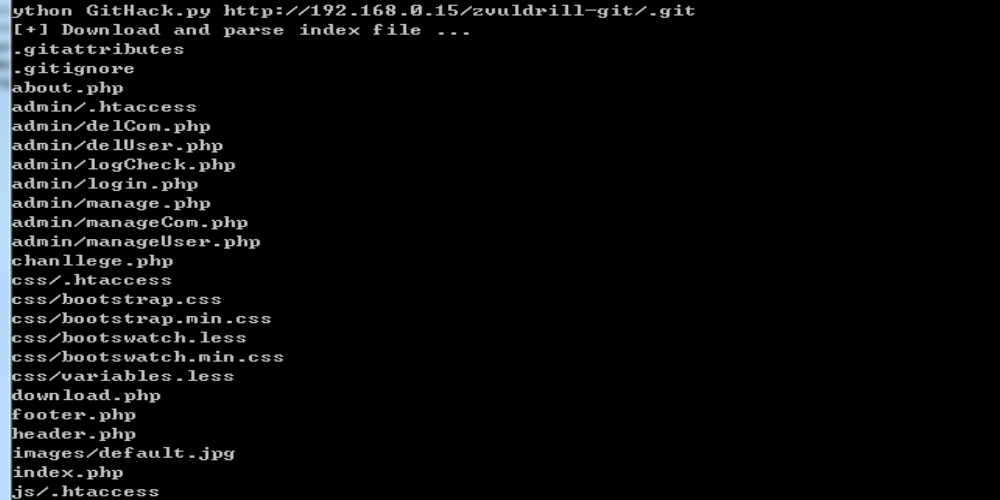
4、DS_store导致文件泄露
.DS_Store是Mac下Finder用来保存如何展示文件//文件夹的数据文件,每个文件夹下对应一个。由于开发/设计人员在发布代码时未删除文件夹中隐藏的.DS_store,可能造成文件目录结构泄漏、源代码文件等敏感信息的泄露。
我们可以模仿一个环境,利用phpstudy搭建PHP环境,把.DS_store文件上传到相关目录。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3185
3185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









