






背景需求
又到毕业季,2024年6月的毕业证书是老师们手写的,本学期我赶紧主动揽活,批量打印毕业证书。
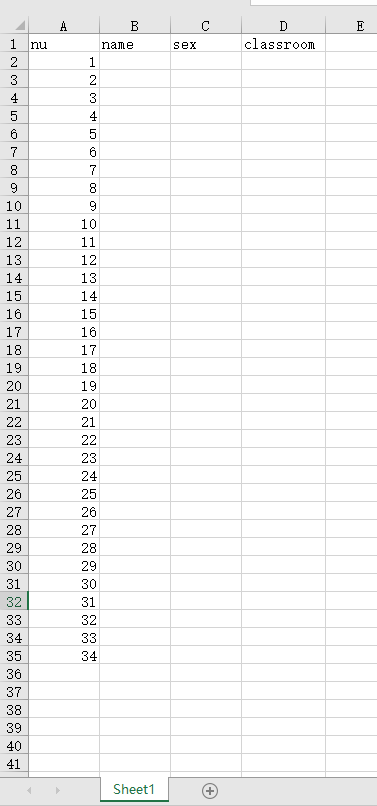
证书没有来,先做一个收集毕业名册的EXCEL
把这个模版批量做7份,注明"大X班毕业证书"
代码很快写出


代码展示
# -*- coding:utf-8 -*-
'''
目的:大班毕业证书(所有大名单都收集后在一个EXCEL工作部内)
作者:阿夏
日期:2023年6月12日 21:54
修改:20250616
'''
from openpyxl import load_workbook
# 1. 读取文件
path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20250616毕业册'
file_path = path + r"\(模板)大班班毕业证名单.xlsx" # 原文件路径
wb = load_workbook(file_path)
# 2. 获取第一个工作表,并重命名为"模板"
first_sheet = wb.worksheets[0]
first_sheet.title = "模板"
# 3. 复制7份,并命名为大1班、大2班...大7班
for i in range(1, 8):
new_sheet = wb.copy_worksheet(first_sheet)
new_sheet.title = f"大{i}班毕业证书"
# 4. 在D2:D34写入班级名称(如 "大1班")
for row in range(2, 35): # D2-D34 共33行
new_sheet[f"D{row}"] = f"大{i}班"
# 5. 另存为新文件
wb.save(path + r"\(模板合集)大班班毕业证名单.xlsx")
print("操作完成!")
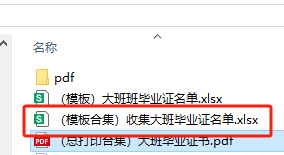
出现7个班级,并且D列有班级号
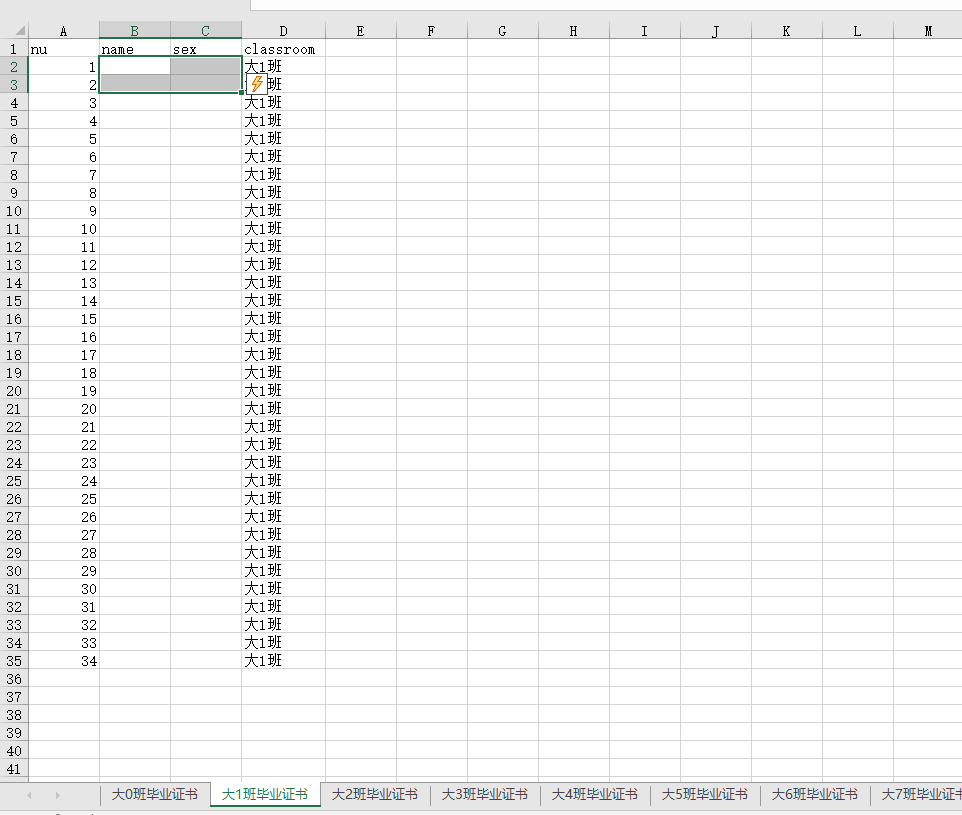
我贴了两行姓名做测试
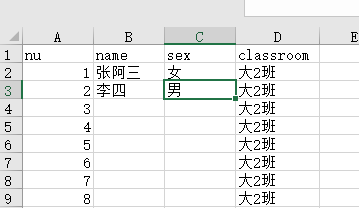
优化生成代码






问了这些问题后,最终实现我想要的效果。
1.只读取有名字的行(因为实际每个班没有34人)
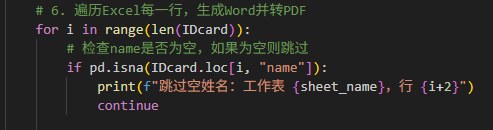
2.为了显示幼儿所在班级学号,做了第二页
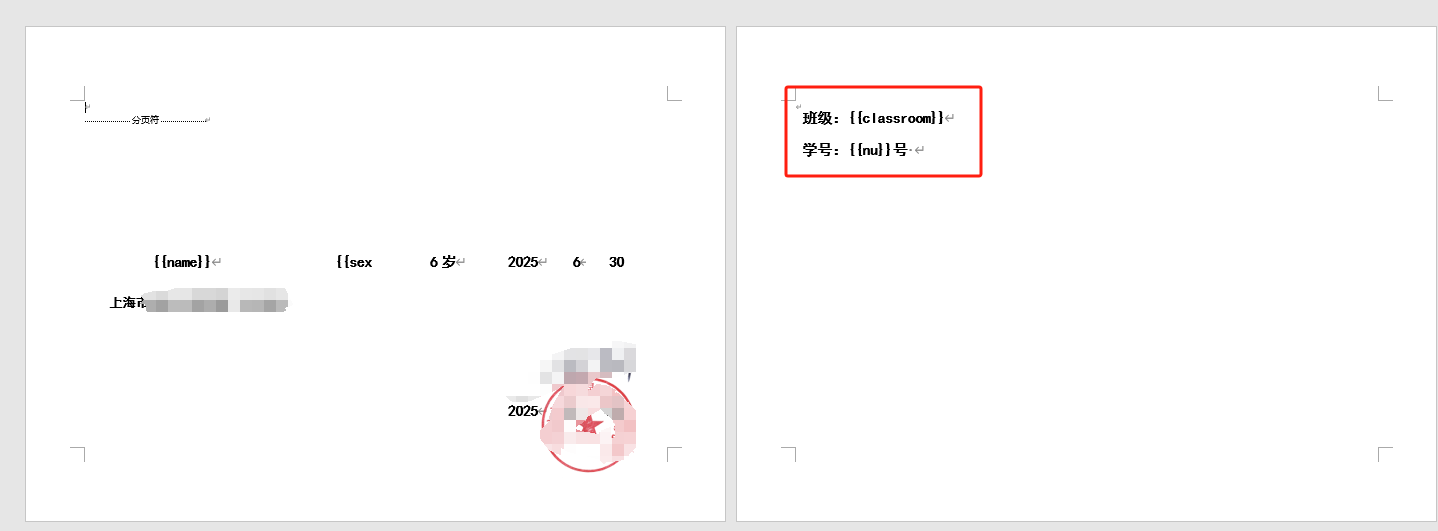
3、每个班级的PDF放在一个文件夹内,最后合并成一个PDF(便于一次性打印,因为每张证书后面有班级,能够区分,可以200多人一次性打印)
代码
# -*- coding:utf-8 -*-
'''
目的:大班毕业证书(读取一个EXCEL中的7个班级信息制作正反PDF(横版打印)。用反面的班级区分
作者:阿夏
日期:2023年6月12日 21:54
修改:20250616
'''
from docxtpl import DocxTemplate
import pandas as pd
import os, time
from docx2pdf import convert
from PyPDF2 import PdfFileMerger
import shutil
# 1. 定义固定路径(直接写绝对路径)
base_path = r"C:\Users\jg2yXRZ\OneDrive\桌面\20250616毕业册" # 所有文件的基础路径
template_path = os.path.join(base_path, "毕业证书模板.docx") # Word模板路径
excel_template_path = os.path.join(base_path, "(模板合集)收集大班毕业证名单.xlsx") # Excel模板路径
pdf_output_dir = os.path.join(base_path, "pdf") # 新建PDF文件夹路径
output_pdf_path = os.path.join(pdf_output_dir, "(打印合集)大{}班毕业证书({}人).pdf") # 班级PDF保存路径
final_all_pdf_path = os.path.join(base_path, "(总打印合集)大班毕业证书.pdf") # 最终合并PDF路径
temp_word_dir = os.path.join(base_path, "零时Word") # 临时Word文件夹路径
# 2. 创建必要的文件夹
os.makedirs(pdf_output_dir, exist_ok=True) # 创建PDF输出文件夹
os.makedirs(temp_word_dir, exist_ok=True) # 创建临时Word文件夹
# 3. 生成1-7班的班级列表
Numnum = list(map(str, range(1, 8))) # ['1', '2', ..., '7']
print("处理的班级:", Numnum)
# 4. 读取Excel文件的所有工作表
excel_data = pd.ExcelFile(excel_template_path)
sheet_names = excel_data.sheet_names # 获取所有工作表名称
# 初始化总PDF合并器
all_pdf_merger = PdfFileMerger()
for sheet_name in sheet_names:
# 检查工作表名称是否符合格式(如 "大1班毕业证书")
if "大" in sheet_name and "班毕业证书" in sheet_name:
# 提取班级数字(如 "大1班毕业证书" -> "1")
class_num = sheet_name.split("大")[1].split("班")[0]
# 5. 读取当前工作表数据
IDcard = pd.read_excel(excel_template_path, sheet_name=sheet_name)
# 初始化有效人数计数器
valid_count = 0
# 6. 遍历Excel每一行,生成Word并转PDF
for i in range(len(IDcard)):
# 检查name是否为空,如果为空则跳过
if pd.isna(IDcard.loc[i, "name"]):
print(f"跳过空姓名:工作表 {sheet_name},行 {i+2}")
continue
# 有效人数+1
valid_count += 1
nu = IDcard.loc[i, "nu"]
name = IDcard.loc[i, "name"]
sex = IDcard.loc[i, "sex"]
classroom = IDcard.loc[i, "classroom"]
context = {
"nu": nu,
"name": name,
"sex": sex,
"classroom": classroom,
}
# 6.1 渲染Word模板
tpl = DocxTemplate(template_path)
tpl.render(context)
# 6.2 保存Word
word_output_path = os.path.join(temp_word_dir, f"{nu:02d}.docx")
tpl.save(word_output_path)
time.sleep(1)
# 6.3 转换为PDF
pdf_output_path = os.path.join(temp_word_dir, f"{nu:02d}.pdf")
convert(word_output_path, pdf_output_path)
time.sleep(1)
# 7. 合并当前班级所有PDF
pdf_files = [f for f in os.listdir(temp_word_dir) if f.endswith(".pdf")]
pdf_files.sort()
class_merger = PdfFileMerger()
for pdf_file in pdf_files:
class_merger.append(os.path.join(temp_word_dir, pdf_file))
# 7.1 保存班级合并PDF到pdf文件夹
class_final_path = output_pdf_path.format(class_num, valid_count)
class_merger.write(class_final_path)
class_merger.close()
# 将班级PDF添加到总合并器
all_pdf_merger.append(class_final_path)
print(f"{sheet_name} 毕业证书已生成:{class_final_path}(共{valid_count}人)")
# 8. 清空临时文件夹
shutil.rmtree(temp_word_dir)
os.makedirs(temp_word_dir, exist_ok=True)
# 9. 合并所有班级PDF为一个总PDF
all_pdf_merger.write(final_all_pdf_path)
all_pdf_merger.close()
print(f"所有班级合并PDF已生成:{final_all_pdf_path}")
# 10. 清理临时文件夹
shutil.rmtree(temp_word_dir)
print("所有班级处理完成!")
测试的结果
成功

等证书来了,还要测量证书的纸张大小(扫描,进一步确定打印位置),在大班办公电脑上设置毕业证书专用的自定义距离。
20250619
今天证书到了,出现几个问题(需要两次打印,一次黑白翻页打印、一次彩色红章打印)
0、拆包,所有证书都检查确保方向一致


1、证书是210*284CM,比A4(210*297)小一厘米,必须使用中班办公室电脑(可以自定义尺寸),自定义一个“大班毕业证书”的尺寸

2、本次有双面打印,中班办公室电脑可以双面,是先打印双数页内容,全部打完后,把出来的纸原样放入送纸口,再打印单数页——所以模版要调整,第一页是班级学号、第二页才是姓名、年龄、学校、毕业时间等信息。
塞纸方向(有字的在上),为了先打印出来的姓名班级学校这一页(先打印双数页),需要在模版里确保单页是姓名学号,双页是姓名班级学校日期。



全部打完后,把出来的纸(白面向上)原样放入打印机,点击确认,继续打印第1页(单页)

截图过期了,需要选择纸张横向,再选双面,横向,

3、但是中班办公室电脑不能彩色打印。在中班电脑上把正反打印后,再把纸拿到保教室电脑(可彩打,但不能自定义尺寸)。纸张比A4小,在送纸口里,把纸向外放一点。



只打印红章
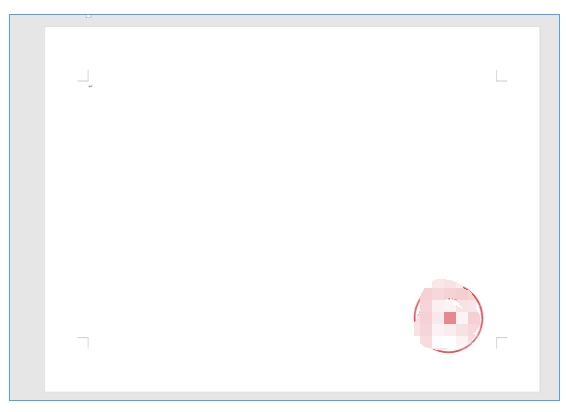


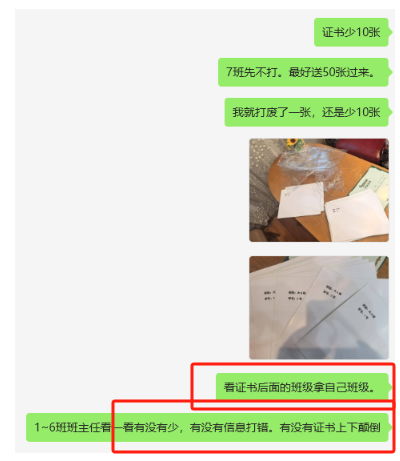
4、通知大班组长,让组员根据班级学号领取


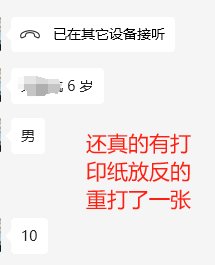
6、已经很小心检查每一张证书方向了,还是有一张打印颠倒的



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











