



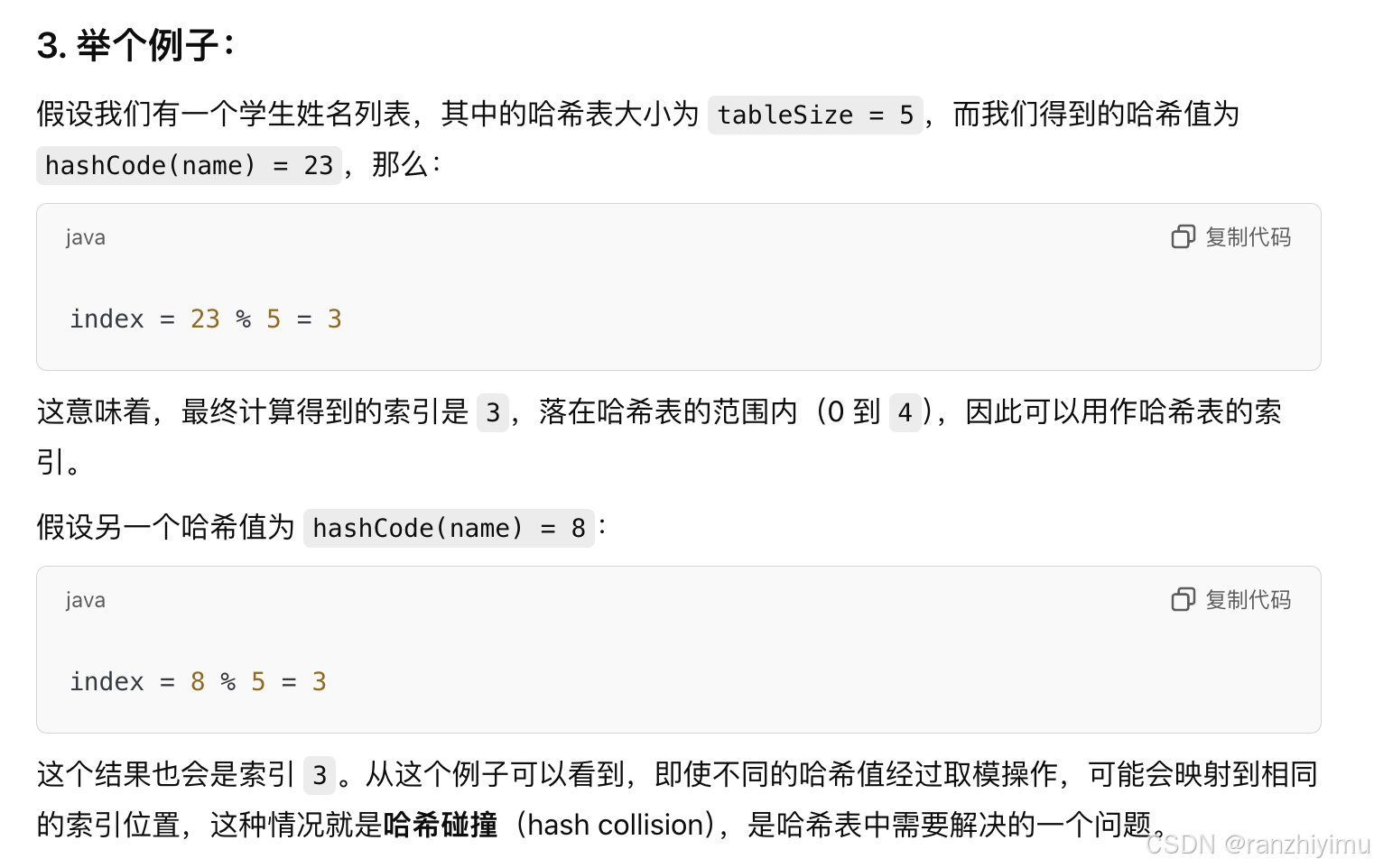
先梳理一下哈希的问题:
哈希code函数处理后的数值不一定落在tableSize的-1的范围内,为了能有效解决这个问题,我们需要去模处理。



242、有效的字母异位词:
242. 有效的字母异位词![]() https://leetcode.cn/problems/valid-anagram/
https://leetcode.cn/problems/valid-anagram/
这道题目主要是设计一个从a到z的数组,来记录第一个字符数组中出现的值,然后再通过第二个字符数组进行扣减,如果最后的记录是每个元素都为0,说明2个数组有相同的字符。否则出现别的值,则说明2个字符数组的元素不完全一致。
在java中,我们调用charAt方法,这是 Java 中 String 类的一个方法,用于获取字符串 s 中第 i 个位置上的字符。
-
s.charAt(i):- 这是 Java 中
String类的一个方法,用于获取字符串s中第i个位置上的字符。 - 假设
s是"abc",那么s.charAt(0)返回的就是字符'a'。
- 这是 Java 中
-
s.charAt(i) - 'a':- 这个表达式的目的是将字符
'a'到'z'转换为一个范围在 0 到 25 之间的整数值。 - 例如,假设
s.charAt(i)返回的是字符'b',那么'b' - 'a'的结果是1。这是因为在 Java 中,字符是基于 ASCII 码表示的,'a'的 ASCII 值是 97,'b'的 ASCII 值是 98。将'b'减去'a',得到的结果是98 - 97 = 1。 - 这样做的目的是将字母
a映射到索引0,b映射到索引1,c映射到索引2,依此类推,z映射到索引25。
- 这个表达式的目的是将字符
-
record[s.charAt(i) - 'a']:record是一个数组,通常定义为int[] record = new int[26];。- 数组
record的大小为26,用于存储每个字母的出现次数,其中:record[0]对应字母'a'的出现次数。record[1]对应字母'b'的出现次数。- ……
record[25]对应字母'z'的出现次数。
s.charAt(i) - 'a'的结果作为数组的索引,用于访问record中对应字母的位置。
代码如下:
class Solution {
public boolean isAnagram(String s, String t) {
int [] recorde =new int [26];
for(int i=0;i<s.length();i++){
recorde[s.charAt(i)-'a']++;
}
for(int j=0;j<t.length();j++){
recorde[t.charAt(j)-'a']--;
}
for(int count :recorde){
if(count !=0){
return false;
}
}
return true;
}
}349、两个数组的交集:
349. 两个数组的交集![]() https://leetcode.cn/problems/intersection-of-two-arrays/如果数组是在1000范围内,那么就可以使用数组来模拟hashSet:
https://leetcode.cn/problems/intersection-of-two-arrays/如果数组是在1000范围内,那么就可以使用数组来模拟hashSet:
public int[] intersection(int[] nums1, int[] nums2) {
int [] hashSet1=new int [1002];
int [] hashSet2=new int [1002];
for(int i:nums1){
hashSet1[i]++;
}
for(int i:nums2){
hashSet2[i]++;
}
Set<Integer> resultSet =new HashSet<>(); //这个对集合去重不知道会造成什么影响,还是用list呢?
for(int i=0;i<1002;i++){
if(hashSet1[i]>0 && hashSet2[i]>0){
resultSet.add(i);
}
}
//转化成数组
int [] resultArray =new int [resultSet.size()];
int index =0;
for(int i:resultSet){
resultArray[index++]=i;
}
return resultArray;
}通过set方式来对第一个数组进行取重。 然后再和第二个数组进行比较,如果发现有 相同的,那么就用一个新的set数组记录下来这个值。 遍历完第二个数组,比较,并记录下来所有重复的元素,然后再把这个新的set转化成数组,最后返回就行。
代码如下:
class Solution {
public int[] intersection(int[] nums1, int[] nums2) {
Set<Integer> resultSet = new HashSet<>();
Set<Integer> nums1Set = new HashSet<>();
for (int num : nums1) {
nums1Set.add(num);
}
for (int num : nums2) {
if (nums1Set.contains(num)) {
resultSet.add(num);
}
}
int[] resultArray = new int[resultSet.size()];
int i = 0;
for (int num : resultSet) {
resultArray[i++] = num;
}
return resultArray;
}
}202. 快乐数
这道题目的逻辑中,一个数要么最终通过数学离散为1,要么就是离散不彻底,会再一次出现,继续下一个周期的往复循环。 我们对于这个n数字,记录到一个哈希set中,如果它再次出现,则不是快乐数,如果它没有重复出现,那么使用一个求平方和的函数分解成另外的数,继续循环,直到n为1或者n打破规则。
代码如下:
class Solution {
public boolean isHappy(int n) {
Set<Integer> record =new HashSet<>();
while(n !=1 && !record.contains(n)){
record.add(n);
n=generation(n);
}
return n==1;
}
public int generation(int n){
int res= 0;
while( n>0 ){
int temp =n%10;
res +=temp*temp;
n=n/10;
}
return res;
}
}尝试写了下python代码:
class Solution:
def isHappy(self, n: int) -> bool:
record =set()
while True :
n=self.generateN(n)
if n==1:
return True
if n in record:
return False
record.add(n)
def generateN(self, n:int) ->int:
temp =0
while n:
n,r =divmod(n,10)
temp += r*r
return temp def generateN(self, n:int) ->int:
temp =0
while n:
n,r =divmod(n,10)
temp += r*r
return temp
def isHappy(self, n: int) -> bool:
record = set()
while n not in record:
record.add(n)
new = 0
str_n =str(n)
for i in str_n:
new +=int(i)**2
if new == 1 :return True
else: n = new
return False 1.两数之和
这道题目可以通过设定一个map,key是原始数组的元素,value是原始数组的对应索引下标。该map来存放我们的数组遍历后的元素,数组中的每个元素和targe的差值对应的那个值,我们会最后放入到map中作为key, 这样就会通过target和 map的key,很快找到另外一个值,
代码如下:
class Solution {
public int[] twoSum(int[] nums, int target) {
int [] res =new int [2];
if(nums ==null ||nums.length ==0){
return res;
}
//倒反天罡,key是nums中元素,value是 索引下标
Map<Integer,Integer> elementIndexMap = new HashMap<>();
for(int i=0;i<nums.length;i++){
int temp =target-nums[i];
if(elementIndexMap.containsKey(temp)){
res[0]=i;
res[1]=elementIndexMap.get(temp);
break;
}
elementIndexMap.put(nums[i],i);
}
return res;
}
}
















 1073
1073

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









