




一、Ollama安装
Ollama 是一个开源项目,专注于在本地运行大型语言模型(LLMs),尤其是 LLaMA(Large Language Model Meta AI)系列模型。它提供了一个简单易用的框架,在个人设备上部署和运行这些模型,而无需依赖云端服务,官网:https://ollama.com/
1.主要特点
- 本地运行:Ollama 支持在本地设备上运行大型语言模型,不依赖云服务,确保数据隐私和安全性。
- 跨平台支持:兼容 macOS、Linux 和 Windows 等操作系统。
- 模型管理:可以轻松下载、管理和切换不同的 LLaMA 模型。
- 高效推理:通过优化,Ollama 能够在资源有限的设备上高效运行大型语言模型。
- 开源:Ollama 是开源项目,可以自由查看、修改和分发代码。
2.使用场景 - 隐私保护:适用于对数据隐私要求较高的场景,如医疗、金融等领域。
- 离线应用:在没有网络连接的环境中运行语言模型。
- 研究与开发:为研究人员和开发者提供一个本地测试和开发语言模型的平台。
3.安装与使用,直接访问官网,下载安装即可

二、Ollama目录更换
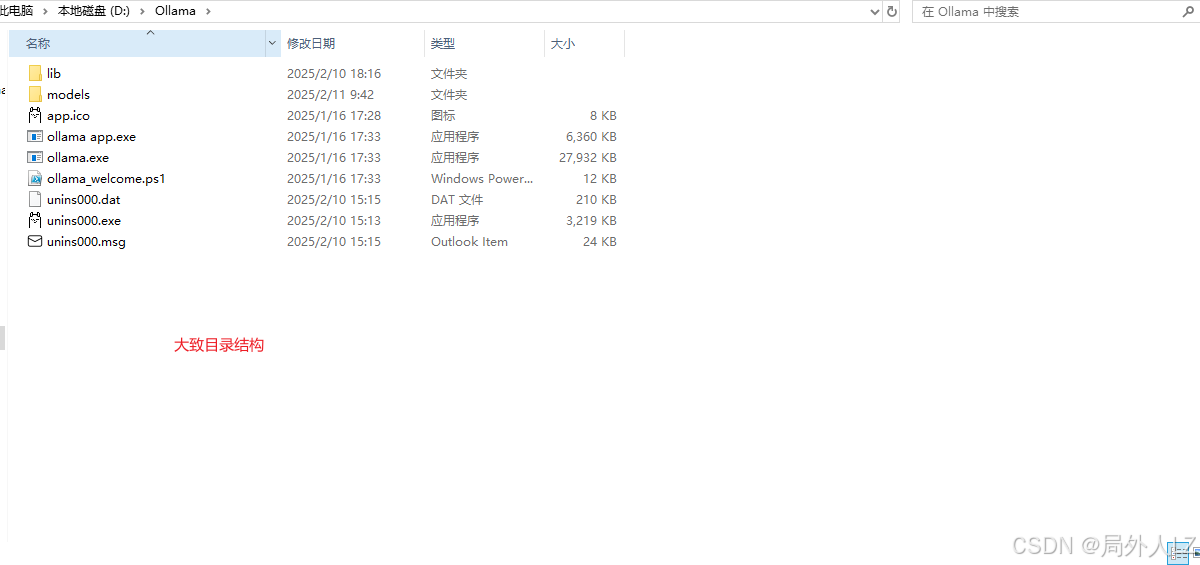
Ollama 默认是安装在C盘,而大模型一般较大,放在c盘并不合适;可以通过以下操作更改Ollama安装目录、模型下载目录
1.查看环境变量,编辑path,找到ollama安装路径,进入该文件,复制全部文件;在其他的盘(以D盘为例)创建ollama目录,把复制的文件全部拷贝到该目录。复制时如果遇见文件无法移动,可执行以下命令终止ollama相关的进程
tasklist | findstr ollama
taskkill /PID 12345 /F
2.修改path环境变量中ollama路径为 D:\ollama
3.在该目录下新建models,增加环境变量OLLAMA_MODELS = D:\ollama\models,用于放下载后的模型
OLLAMA_MODELS:配置模型下载路径
OLLAMA_HOST:配置服务监听网络地址,默认127.0.0.0
OLLAMA_PORT:配置服务监听端口,默认11434
OLLAMA_ORIGINS:配置http客户端请求来源,默认*
OLLAMA_KEEP_ALIVE:配置模型加载到内存中后的存过时间,默认5m
OLLAMA_NUM_PARALLEL:配置请求处理的并发数量,默认1
OLLAMA_MAX_QUEUE:配置请求队列长度,默认512
OLLAMA_DEBUG:配置debug日志
OLLAMA_MAX_LOADEDMODELS:配置最多同时加载到内存中的模型的数量,默认1
4.重启电脑,运行命令启动ollama服务:ollama serve,可访问http://localhost:11434/查看服务是否启动成功
三、本地部署deepseek
1.访问https://ollama.com/search,可查看可下载的模型
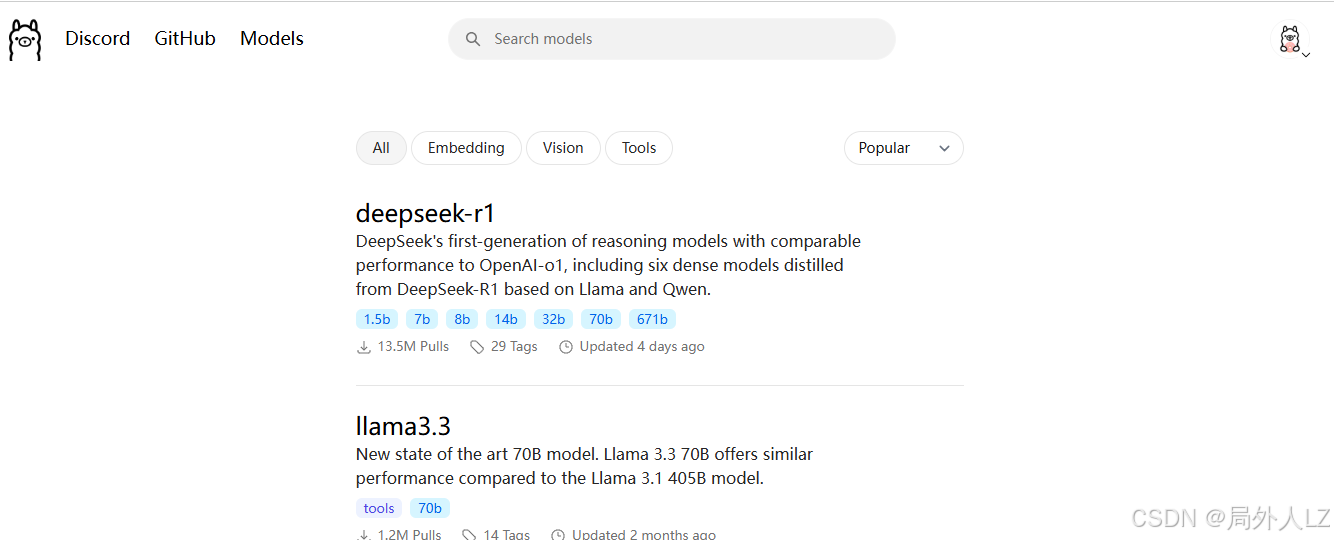
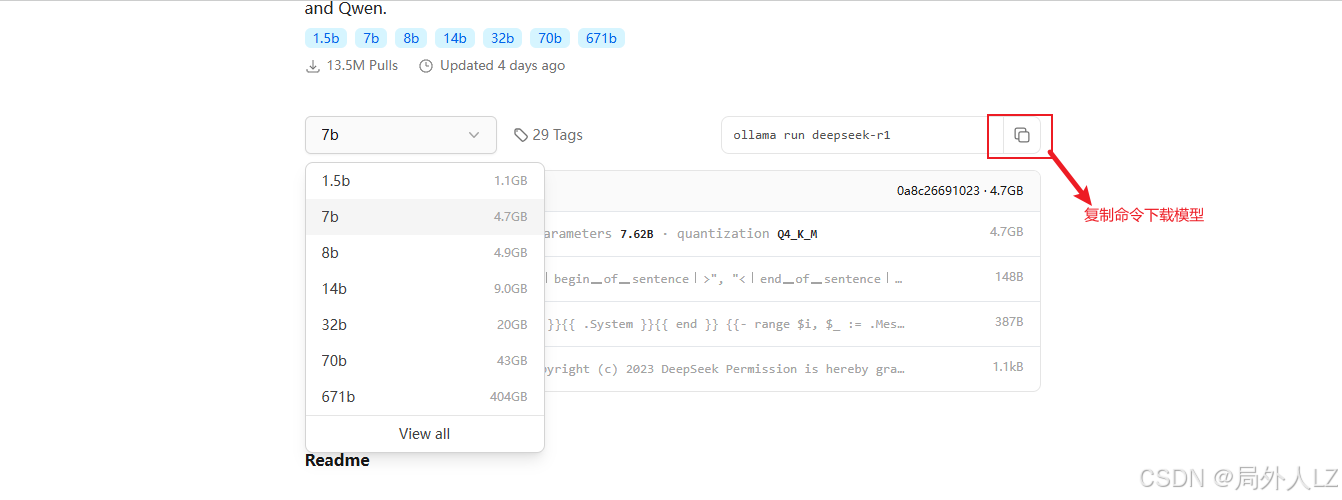
2.下载deepseek-r1、deepseek-coder模型,分别搜索deepseek-r1、deepseek-coder,点击模型查看模型信息,在模型信息中可选择模型版本,复制命令,打开cmd运行命令即可下载
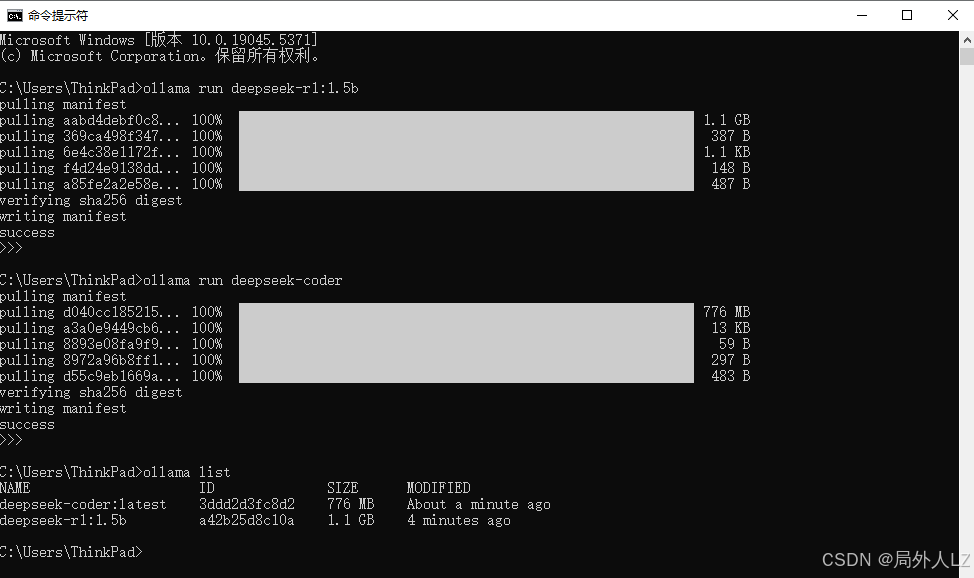
3.模型下载后,运行ollama list命令可查看已下载的所有模型
四、continue插件
轻量级AI代码助手,侧重基础补全,依赖本地模型资源占用较小,响应速度快。由于依赖本地模型,私密性较好,支持离线使用。内置多种AI模型,可通过ollama下载模型,也可配置对应的AI的api-key使用AI模型,官网地址:https://www.continue.dev/
1.打开开发者工具,这里以webstrom为例,在设置中找到插件管理,搜索continue下载即可,下载后按照提示重启webstrom即可
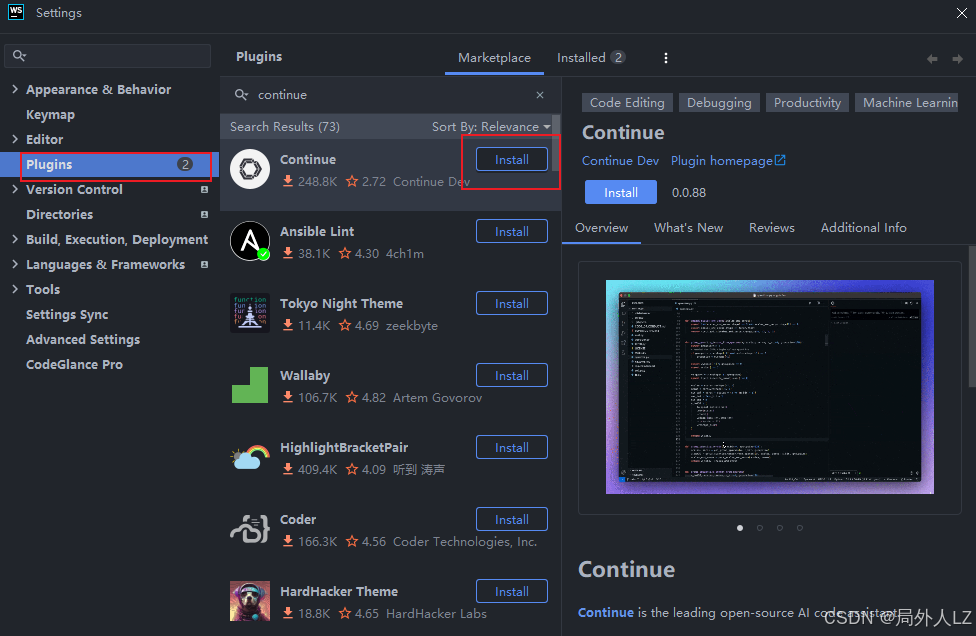
2.打开continue配置文件
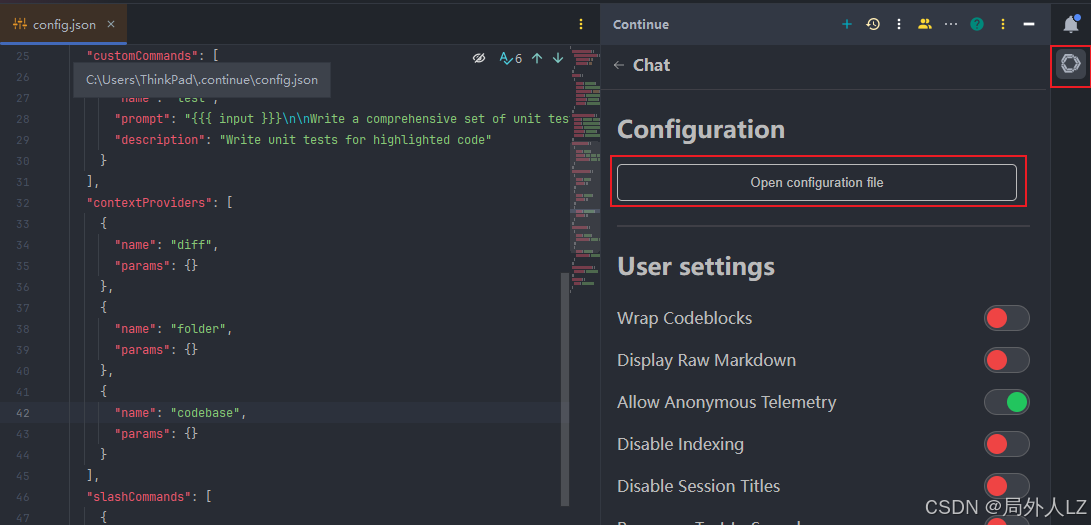
3.配置文件相关配置替换为下面即可,模型需要与之前下载的模型对应起来
"completionOptions": {
"BaseCompletionOptions": {
"temperature": 0,
"maxTokens": 256
}
},
"models": [
{
"title": "DeepSeek1.5b(ollama)",
"model": "deepseek-r1:1.5b",
"contextLength": 128000,
"provider": "ollama",
"apiBase": "http://localhost:11434/"
}
],
"tabAutocompleteModel": {
"title": "DeepSeek Coder(ollama)",
"model": "deepseek-coder:latest",
"provider": "ollama",
"apiBase": "http://localhost:11434/"
},
4.输入canvas生成贪吃蛇游戏,可以看出已经生成代码;说明模型配置成功
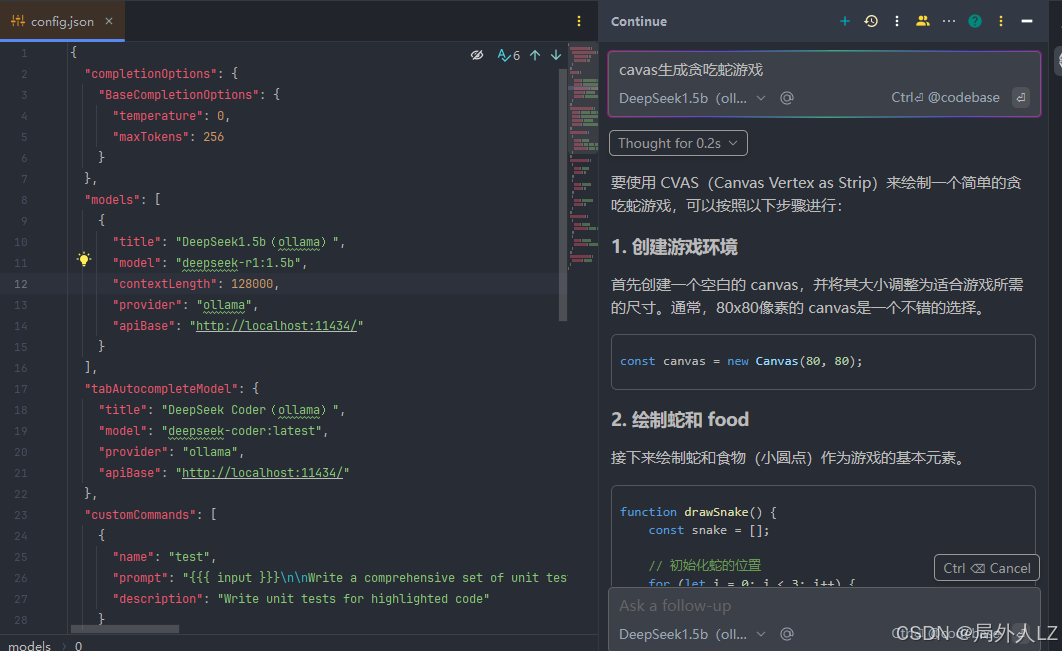
五、continue线上模型配置
1.访问deepseek官网https://www.deepseek.com/,找到开放平台,创建API key
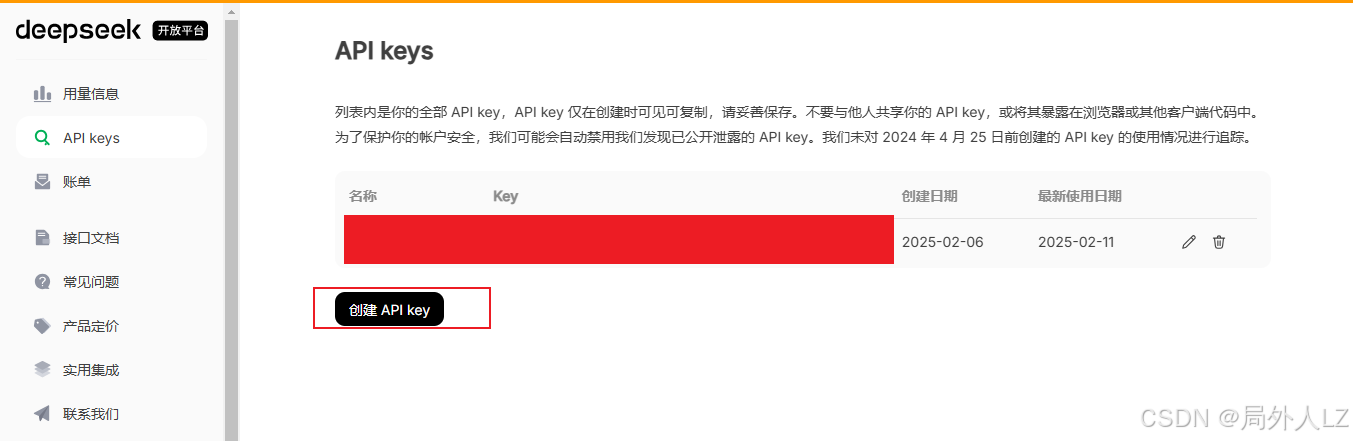
2.配置文件相关配置替换为下面即可
"models": [
{
"title": "DeepSeek",
"model": "deepseek-chat",
"contextLength": 128000,
"apiKey": "apiKey",
"provider": "deepseek",
"apiBase": "https://api.deepseek.com/beta"
}
],
"tabAutocompleteModel": {
"title": "DeepSeek Coder",
"model": "deepseek-coder",
"apiKey": "apiKey",
"provider": "deepseek",
"apiBase": "https://api.deepseek.com/beta"
}
3.输入canvas生成贪吃蛇游戏,可以看出已经生成代码;说明模型配置成功
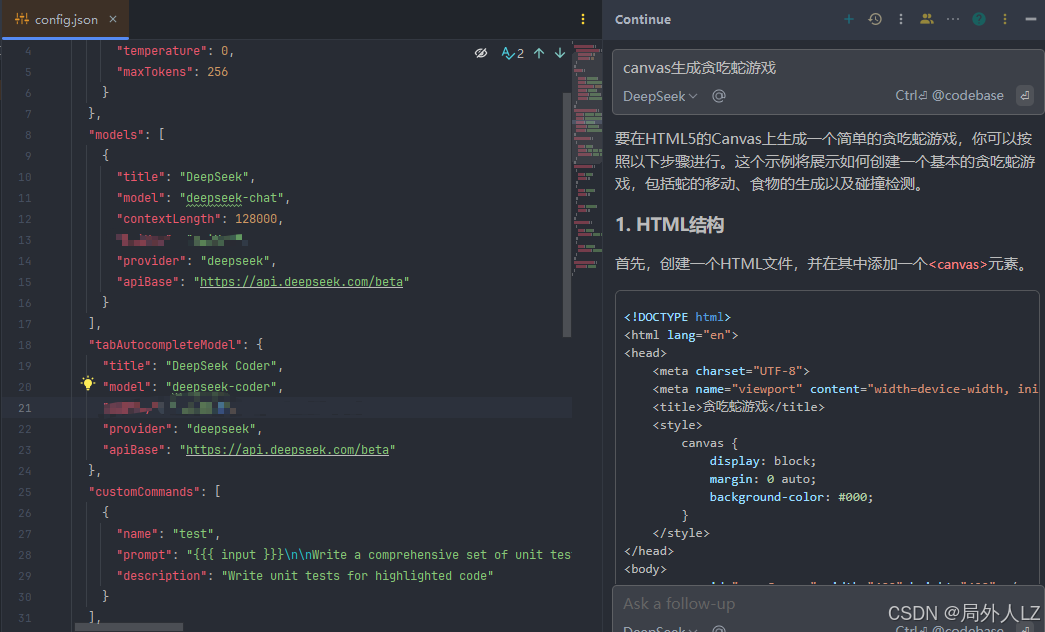
六、continue基本配置
1.completionOptions:控制文本生成和完成设置行为的参数,可被models.completionOptions覆盖
- stream:是否对LLM响应进行流式处理。目前仅受到 anthropic 和 ollama 提供者的尊重;其他提供商将始终流式传输 (默认值:true)。
- temperature:控制完成的随机性。值越高,输出越多样化。
- topP:细胞核采样的累积概率。较低的值将对最大概率质量数内的标记的响应限制为响应。
- topK:每个步骤中考虑的最大 Token 数量。将生成的文本限制为此概率内的标记。
- presencePenalty:阻止模型生成已出现在输出中的标记。
- frequencePenalty:根据标记在文本中的频率惩罚标记,从而减少重复。
- mirostat:启用 Mirostat 采样,它控制文本生成过程中的困惑。受 Ollama、LM Studio 和 llama.cpp 提供商支持(默认值:0,其中 0 = 禁用,1 = Mirostat,2 = Mirostat 2.0)。
- stop:一个 stop 令牌数组,遇到该数组时,将终止完成。允许指定多个结束条件。
- maxTokens:完成时要生成的最大令牌数(默认值:2048)。
- numThreads:生成过程中使用的线程数。仅适用于 Ollama 的 num_thread。
- keepAlive:对于 Ollama,此参数设置在最后一个请求后保持模型加载状态的秒数,如果处于非活动状态,则从内存中卸载模型(默认值:1800 秒或 30 分钟)。
- useMmap:对于 Ollama,此参数允许将模型映射到内存中。如果禁用,则可以缩短低端设备的响应时间,但会减慢流的速度。
2.requestOptions:HTTP 请求选项,可被models.requestOptions覆盖 - timeout:每个请求的超时LLM时间(默认值:7200 秒)。
- verifySsl: 是否验证请求的 SSL 证书。
- caBundlePath:HTTP 请求的自定义 CA 捆绑包的路径 - .pem 文件(或路径数组)的路径
- proxy:用于 HTTP 请求的代理 URL。
- headers:HTTP 请求的自定义标头。
- extraBodyProperties:要与 HTTP 请求正文合并的其他属性。
- noProxy:应绕过指定代理的主机名列表。
- clientCertificate:HTTP 请求的客户端证书。
- clientCertificate.cert: Path to the client certificate file.
- clientCertificate.cert:客户端证书文件的路径。
- clientCertificate.key:客户端证书密钥文件的路径。
- clientCertificate.passphrase:客户端证书密钥文件的可选密码。
3.models:模型配置 - title:分配给模型的标题,显示在下拉列表等
- provider:模型的提供者,它决定了模型的类型和交互方式。选项包括 openai、ollama、xAI 等
- model:模型的名称,用于提示模板自动检测。使用 AUTODETECT 特殊名称获取所有可用模型
- apiKey:OpenAI、Anthropic、Cohere 和 xAI 等提供商所需的 API 密钥
- apiBase:LLMAPI 的基 URL。
- contextLength:模型的最大上下文长度,通常以 tokens 为单位(默认值:2048)。
- maxStopWords:允许的最大停用词数,以避免出现大量列表的 API 错误。
- template:用于格式化消息的聊天模板。对于大多数模型,会自动检测,但可以覆盖。
- promptTemplates:提示模板名称(例如,edit)到模板字符串的映射
- completionOptions:特定于模型的补全选项,格式与顶级 completionOptions 相同,它们会覆盖它。
- systemMessage:一条系统消息,将位于来自 LLM.
- requestOptions:特定于模型的 HTTP 请求选项,格式与顶级 requestOptions 相同,它们会覆盖这些选项。
- apiType:指定 API 的类型(openai 或 azure)。
- apiVersion:Azure API 版本(例如 2023-07-01-preview)。
- engine:Azure OpenAI 请求的引擎。
- capabilities:覆盖自动检测到的功能:
- capabilities.uploadImage:布尔值,指示模型是否支持图像上传。
4.tabAutocompleteModel:指定 tab 自动完成的一个或多个模型,默认为 Ollama 实例。此属性使用与 models 相同的格式。可以是模型数组,也可以是 1 个模型的对象。
{
"tabAutocompleteModel": {
"title": "My Starcoder",
"provider": "ollama",
"model": "starcoder2:3b"
}
}
5.tabAutocompleteOptions:指定 Tab 键自动完成行为的选项
- disable:如果为 true,则禁用 Tab 键自动完成(默认值:false)。
- maxPromptTokens:提示的最大令牌数(默认值:1024)。
- debounceDelay:触发自动完成之前的延迟(以毫秒为单位)(默认值:350)。
- maxSuffixPercentage:后缀提示的最大百分比(默认值:0.2)。
- prefixPercentage:前缀的输入百分比(默认值:0.3)。
- template:使用 Mustache 模板进行自动完成的模板字符串。您可以使用 {{{ 前缀 }}}、{{{ 后缀 }}}、{{{ 文件名 }}}、{{{ reponame}}} 和 {{{ 语言 }}} 变量。
- onlyMyCode:如果为 true,则仅包含存储库中的代码(默认值:true)。
6.customCommands:边栏中提示快捷方式的自定义命令 - name:自定义命令的名称。
- prompt:命令的文本提示符。
- description:解释命令功能的简要描述
7.slashCommands:通过在边栏中键入 “/” 来启动自定义命令。命令包括预定义的功能,也可以是自己定义的,如:edit - name:命令名称。选项包括 “issue”、“share”、“cmd”、“http”、“commit” 和 “review”。
- description:命令的简要描述。
- params:用于配置命令行为的附加参数
8.contextProviders:在聊天中键入时将显示为选项的预定义上下文提供程序列表,以及它们对 params 的自定义。 - name:上下文提供者的名称,例如 docs 或 web
- params:用于配置上下文行为的 params 的上下文提供程序特定记录
9.reranker:响应排名中使用的 reranker 模型的配置。 - name:Reranker 名称,例如 cohere、voyage、llm、free-trial、huggingface-tei、bedrock
- params:参数
- params.model:型号名称
- params.apiKey:Api 密钥
- params.region:区域(仅适用于 Bedrock)
10.docs:要编入索引的文档站点列表。 - title:文档站点的标题,显示在下拉列表等中。
- startUrl:用于抓取的起始页 - 通常是文档的根页或介绍页
- maxDepth:爬网的最大;链接深度。默认
- favicon:网站图标的 URL(默认值为 /favicon.ico from startUrl)。
- useLocalCrawling:跳过默认爬虫,仅使用本地爬虫进行爬虫。
11.embeddingsProvider:用于@Codebase和@docs的模型。 - provider:指定嵌入提供程序,选项包括 transformers.js、ollama、openai、cohere、free-trial、gemini 等
- model:嵌入的模型名称。
- apiKey:提供商的 API 密钥。
- apiBase:API 请求的基 URL。
- requestOptions:特定于嵌入提供程序的其他 HTTP 请求设置。
- maxChunkSize:每个文档块的最大令牌数。最少 128 个代币。
- maxBatchSize:每个请求的最大块数。最小值为 1 个数据块。
- region:AWS指定托管模型的区域。
- profile:AWS 安全配置文件。
12.userToken:标识用户的可选令牌,主要用于经过身份验证的服务。
13.systemMessage:系统消息,该消息显示在语言模型的每个响应之前,提供指导或上下文
七、codeGPT插件
AI代码助手,支持复杂逻辑生成(如算法生成、脚手架搭建),调用云端api资源占用较大,响应速度慢。需传输代码到云端,私密性较差,且不支持离线使用。可配置多种AI。官网地址:https://www.codegpt.ee/
1.打开开发者工具,这里以webstrom为例,在设置中找到插件管理,搜索codeGPT下载即可,下载后按照提示重启webstrom即可
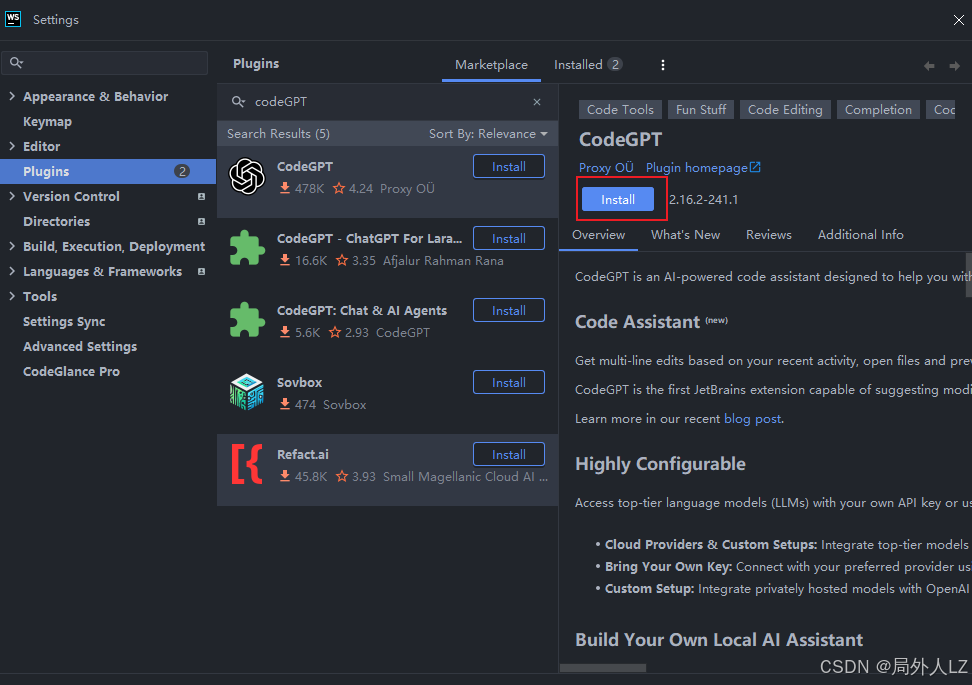
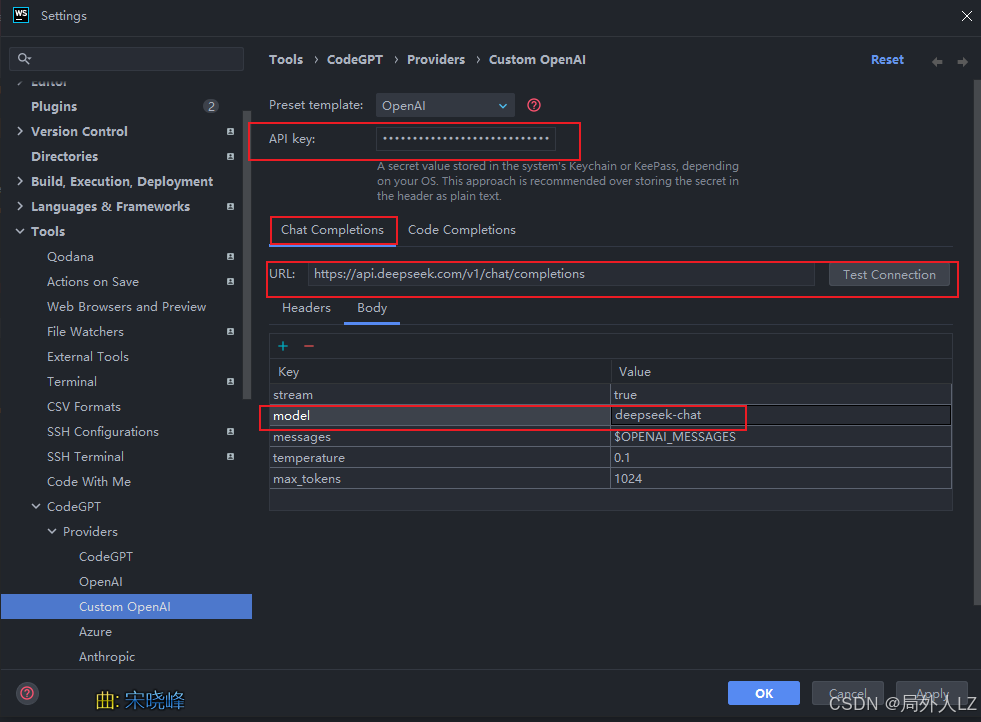
2.打开codeGPT配置,输入已经申请的api key;在chat completions选项填上url:https://api.deepseek.com/v1/chat/completions,切换到body修改model:deepseek-chat
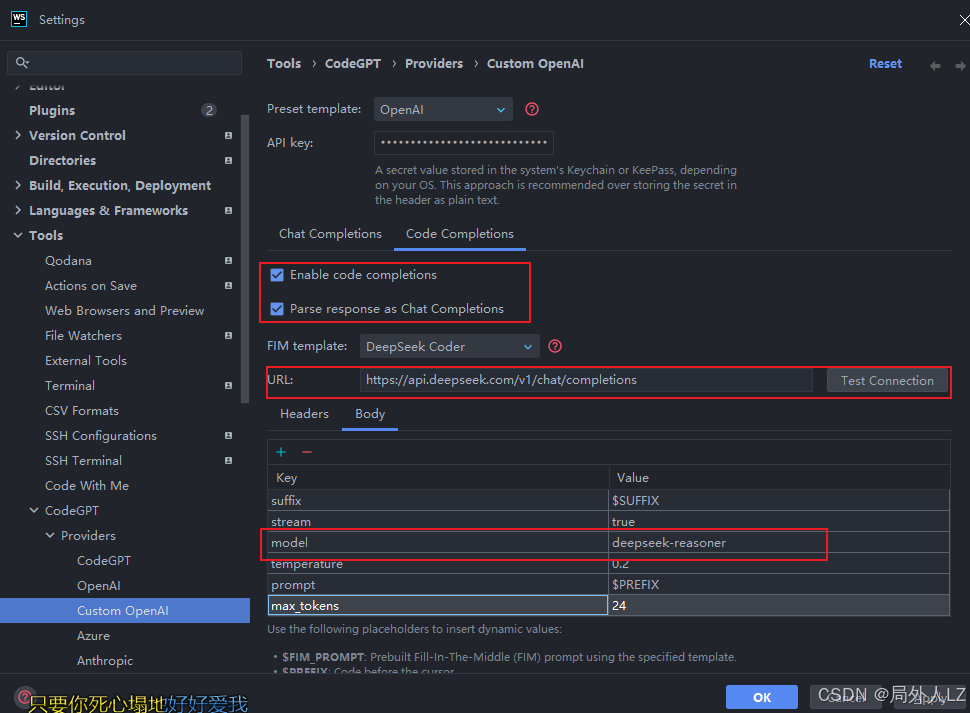
3.在code completions选项填上url:https://api.deepseek.com/v1/chat/completions,切换到body修改model:deepseek-reasoner
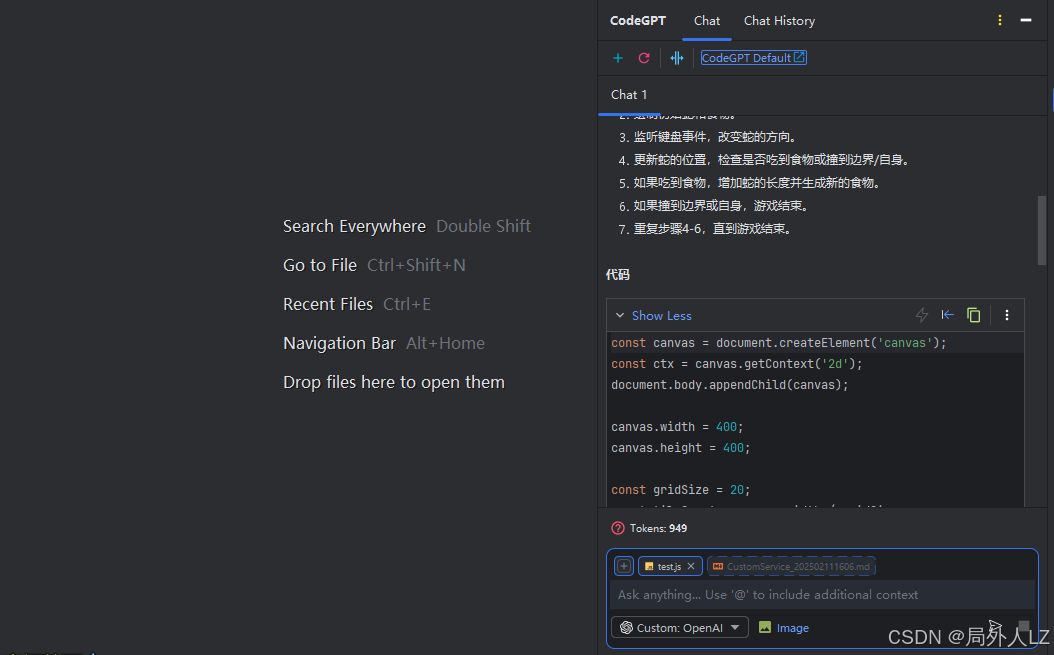
4.选择custom:openao,输入canvas生成贪吃蛇游戏,可以看出已经生成代码;说明模型配置成功



















 6339
6339

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











