









 本文介绍了并发编程的三大特性:可见性、有序性和原子性。通过实例解释了volatile关键字在确保可见性中的作用,以及如何解决缓存一致性问题。此外,还探讨了有序性对多线程执行的影响,以及如何保证原子性以确保数据一致性。最后,文章提到了Java中的synchronized和CAS操作在并发控制中的应用。
本文介绍了并发编程的三大特性:可见性、有序性和原子性。通过实例解释了volatile关键字在确保可见性中的作用,以及如何解决缓存一致性问题。此外,还探讨了有序性对多线程执行的影响,以及如何保证原子性以确保数据一致性。最后,文章提到了Java中的synchronized和CAS操作在并发控制中的应用。
并发编程三大特性
所谓并发编程是指在一台处理器上“同时”处理多个任务。并发是在同一实体上的多个事件。多个事件在同一时间间隔发生。
可见性(visibility)
有序性 (ordering)
原子性(atomicity)
可见性:
首先看一个小程序
public class T01 {
private static boolean running = true;
private static void m(){
System.out.println("m start");
while (running){
System.out.println("hello");
}
System.out.println("m end!");
}
public static void main(String[] args) {
new Thread(T01::m,"t1").start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
running = false;
}
}结果就是只有m start输出 一直没有后面的东西了
因为running 的值是被copy了一份到另一个线程 在缓存里 如果这个线程不重新读取 他就会一直是true
你只是修改了主线程的running 而没有修改另一个线程的running 一个线程基本上看不到另一个线程的值
这时候怎么办呢?只有把runnig值加关键字volatile修饰才可以
volatile: 保持线程的可见性
对于他任意的修改
被volatile修饰的内存都会去主内存读取一次
所以变成下面
public class T01 {
private static volatile boolean running = true;
private static void m(){
System.out.println("m start");
while (running){
// System.out.println("hello");
}
System.out.println("m end!");
}
public static void main(String[] args) {
new Thread(T01::m,"t1").start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
running = false;
}
}但是有人会发现 在里面加了一个sout 输出一个hello 本来应该是一直持续下去的 但是却执行了一会儿 就结束了进程
/**
* Prints a String and then terminate the line. This method behaves as
* though it invokes <code>{@link #print(String)}</code> and then
* <code>{@link #println()}</code>.
*
* @param x The <code>String</code> to be printed.
*/
public void println(String x) {
synchronized (this) {
print(x);
newLine();
}
}那是因为println方法的底层是一个锁 也可以理解为保证了可见性
所以有些语句 (指令)是可以触发本地线程缓存和主线程之间的一个刷新和同步 但是这些都不是不可用的方法 上锁也意味着效率变低 所以该加volatile 就用 volatile
volatile 引用类型(包括数组)只能保证引用本身的可见性,不能保证内部字段的可见性
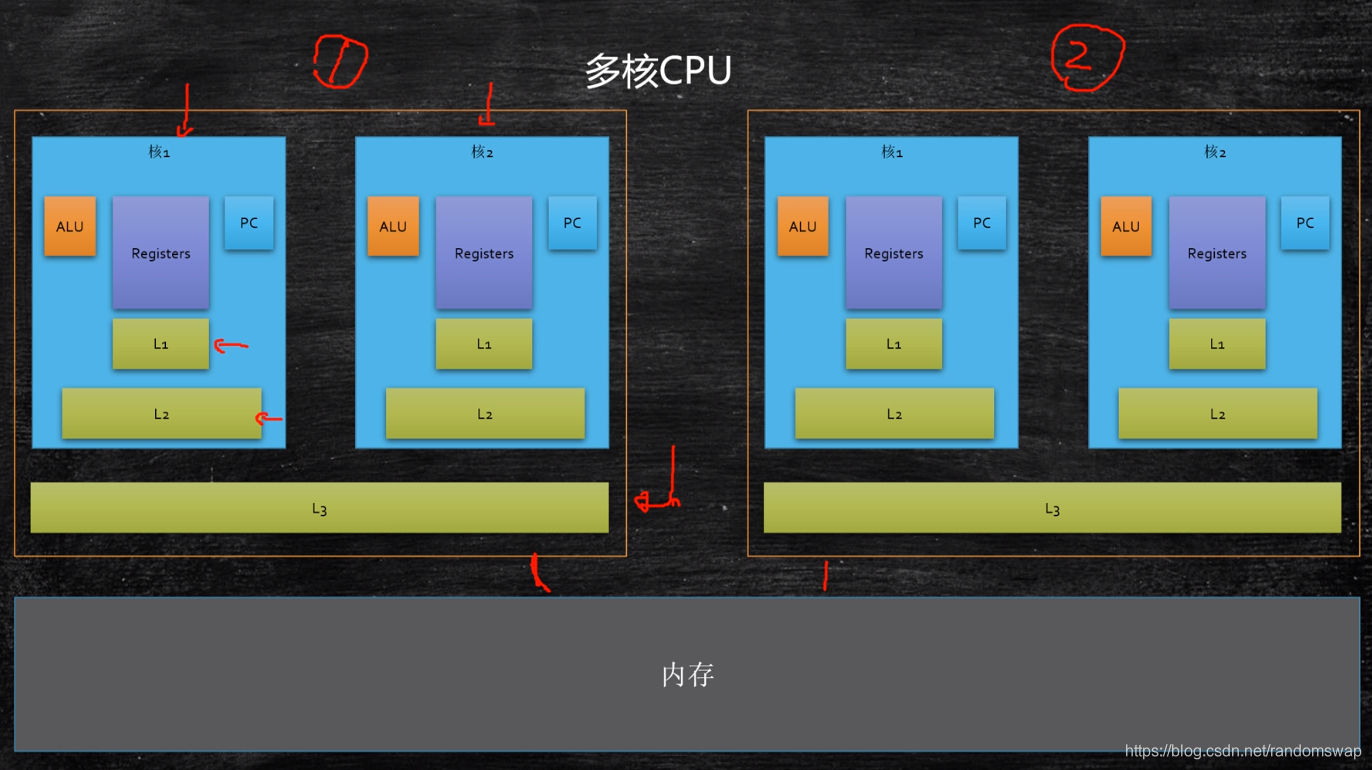
缓存行
按块读取 运用局部性原理 可以提高效率
局部性原理 :充分发挥总线cpu针脚等一次性读取更多数据的能力
每一块数据专业名词就是缓存行cache line 一个缓存行有64个字节byte
byte 1字节
int 4字节
short 2字节
long 8字节
float 4字节
double 8字节
Boolean 1位
char 2字节
1字节表示8位
long占8个字节
缓存一致性协议 在不同cpu缓存里相同缓存行 会导致修改缓慢
这里提一下案例 jdk1.7的源码 在linked blocking queue
或者另一个框架 disruptor
Disruptor是英国外汇交易公司LMAX开发的一个高性能队列,研发的初衷是解决内存队列的延迟问题(在性能测试中发现竟然与I/O操作处于同样的数量级)。基于Disruptor开发的系统单线程能支撑每秒600万订单,2010年在QCon演讲后,获得了业界关注。2011年,企业应用软件专家Martin Fowler专门撰写长文介绍。同年它还获得了Oracle官方的Duke大奖。
也是现在很多国内大厂里项目都会运用到的一个框架
可以参考下美团内部对这个框架的介绍 更加详细https://tech.meituan.com/2016/11/18/disruptor.html
你可以maven 依赖一下这个框架然后看下源码
public final class RingBuffer<E> extends RingBufferFields<E> implements Cursored, EventSequencer<E>, EventSink<E> {
public static final long INITIAL_CURSOR_VALUE = -1L;
protected long p1;
protected long p2;
protected long p3;
protected long p4;
protected long p5;
protected long p6;
protected long p7;你会发现他很很多什么p1 p2 p3 p4 p5 ..等等 因为他是64byte 的原因 所以他才填补了7个long 给促成的一个64byte 造成不同的缓存行 所以不会触发缓存一致性 骨灰级的优化 精确到每一次cpu读取的数据 所以这个框架才会很厉害 当然现实中的项目大部分是不需要这样的优化 但是这样一来有
那么一个问题
缓存行是固定64byte ,如果哪天变了 变成128字节了,那么显然7个long无法促成缓存行不齐了
所以jdk1.8的时候加了一个注解 这个注解保证被注解的数据不会和其他数据处于同一行
sun.misc.Contended @Contended
需要jvm加个指标打开
![]() -XX:-RestrictContended;
-XX:-RestrictContended;
这个注解jdk1.9以后也不起作用了 只有jdk1.8可以用
缓存一致性协议 有msi mesi mosi
mesi 缓存一致性协议 是因特尔Intel设计的 所以是最有名的一个
所谓的mesi是缓存行的4种状态
Modified Exclusive Shared Invalid
被修改 独享 分享 失效
mesi和volatile 无关
补充一点
为什么缓存行是64个字节?
缓存行越大,局部性空间效率越高,但读取速度慢,
缓存行越小,局部性空间效率越低,但读取速度快。
取了一个中间值,目前多用 64字节 是一次次实验中得到的数值
有序性:
程序真的是按“顺序”执行的吗?
未必
public class T01 {
private static int x,y,a,b;
public static void main(String[] args) throws InterruptedException {
for (long i = 0; i < Long.MAX_VALUE; i++) {
x = 0;
y = 0;
a = 0;
b = 0;
CountDownLatch latch = new CountDownLatch(2);
Thread one = new Thread(new Runnable() {
@Override
public void run() {
a = 1;
x = b;
latch.countDown();//将count值减1
}
});
Thread two = new Thread(new Runnable() {
@Override
public void run() {
b = 1;
y = a;
latch.countDown();//将count值减1
}
});
one.start();
two.start();
latch.await(); //调用await()方法的线程会被挂起,它会等待直到count值为0才继续执行
String result = "第" + i +"次(x="+x+",y="+y+")";
if (x == 0 && y ==0){
System.out.println(result);
break;
}
}
}
}你可以copy这段代码 在你的程序里执行
我的是 第26140次(x=0,y=0) 可能很多人都看不出来有什么问题

意思就是有俩个线程 每个线程有俩句指令。在分别执行。
大家都知道 多线程的执行是不确定 有可能你先执行过后 我再执行接下来的 然后你再继续执行 这都是不确定 或者说 有可能的。
只有出现a=1 和b=1出现换顺序的情况下 也就是最后一种 才能达成x=0 y=0 只有一种可能 但也会发生,出现的概率并不高,但可以从这看出 乱序是真真实实存在的 虽然几率不高
为什么会这样的呢?简单来说 为了提高效率

在第一条指令等待的时候 完全可以执行第二条执行 微观角度来讲 可能第二条指令就会优先执行完第一条指令 这是cpu里的一个优化机制 当然也不是随随便便 哪俩条语句都可以换的 前后两条语句没有依赖关系 这条语句有可能会换顺序
乱序不影响单线程的最终一致性,as if serial,前提是单线程 好像是一步一步执行 实际当中可能是换顺序的,只要不影响单线程的最终一致性
x=1 y=1这俩个怎么换都没有问题,因为不会造成任何影响结果的不一样
x=1 x++ 后面这个++依赖前面的 就永远不会进行替换顺序 因为会造成结果不一样
但是在多线程的乱序可能会造成影响
除了上面那个小程序外,再来个简单一点的小程序
public class T02 {
private static boolean ready = false;
private static int number;
private static class Reader extends Thread{
@Override
public void run() {
while (!ready){
Thread.yield();
}
System.out.println(number);
}
}
public static void main(String[] args) throws InterruptedException {
Thread t = new Reader();
t.start();
number = 42;
ready = true;
t.join();
}
}你懂了有序性过后 你可以了解到一些有趣现象。
这个是《java并发实践》这本书里的一个案例。
这个程序有两个问题。
第一个就是可见性。
设置为true过后可能不会马上停止 Thread.yield的同步刷新 都有可能ready=true的情况下马上被见到。
所以你也能见到输出 加个volatile 保证可见性。
第二个就是有序性。
最后输出可能为0。
number = 42 和ready = true 没有依赖性 完全可能换顺序 当然这只是一种可能 你做成千上万次实验可能也不成功
第三大特性
原子性
public class T0 {
private static long n = 0L;
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[100];
CountDownLatch latch = new CountDownLatch(threads.length);
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j=0;j<10000;j++){
n++;
}
latch.countDown();
});
}
for (Thread thread : threads) {
thread.start();
}
latch.await();
System.out.println(n);
}
}
这个小程序大概的意思就是起了100个线程,每个线程给n都加1w,所以理想下最后n是100w
但是你执行后发现 每一次的结果都是不一样的 原因大概都知道 就是因为每个线程赋值的时候没有读到最新的
第一个线程把0改成1 第二个线程也都成0 然后改成1 所以最后显示上去是1 其实应该是2 就是这种问题。
出这种问题的原因是什么呢?
多线程访问共同数据会产生竞争 这种竞争我们叫 race condition =>竞争条件
数据的不一致性(unconsistency),并发访问之下产生的不期望的结果 比如说理想是100w 但实际会少很多这种情况
如何保障数据一致呢?
答案是线程同步(也就是线程执行的顺序安排好)
具体的话。就是n++的时候不被其他线程给打断 我一个线程一读一写这俩个操作不被打断 不能我这个线程正在写的时候 另一个线程就来读,那么只会读到原来的值。这么一操作 如果不被打断那么后面的线程读到的都是最新的 后面的数据就可以保障是一致的。
这个操作就叫做原子性。
什么样的语句(指令)具备原子性?
不管什么语言 什么java、c、 c++等等 高级的 低级的。 最后都会转成cpu识别的汇编语言 asm
即使是asm汇编指令都有可能被其他线程打断,更何况其他语言。
cpu级别汇编 需要查汇编手册
java里8大原子操作 (了解就可以,无需记忆)
虚拟机级别的操作
- lock:主内存,标识变量为线程独占
- unlock:主内存,解锁线程独占变量
- read:主内存,读取内存到线程缓存(工作内存)
- load:工作内存,read后的值放入线程本地变量副本
- use:工作内存,传值给执行引擎
- assign:工作内存,执行引擎结果赋值给线程本地变量
- store:工作内存,存值到主内存给write备用
- write:主内存,写变量值
在你不确定的某一个操作是否是原子性的时候 又需要对数据进行同步的时候
这时候就需要一个机制 保证我们的操作具有原子性
保证原子性的操作其实大家都知道,就是上锁。
synchronized 锁定这个对象
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j=0;j<10000;j++){
synchronized (T0.class){
n++;
}
}
latch.countDown();
});
}那么执行最后的结果就是理想的100w
首先java代码的n++的一句代码 翻译成汇编码大概有4句再翻译成机器语言说不定就10多句。必须保证这10几句不被打断。那么就是上锁。
那么上锁的本质是什么呢?
把原来的并发操作编程了序列化操作。synchronized也保证了可见性和原子性,但没有保证有序性。
当然你上锁过后效率一定会变低
注意序列化并非其他程序一直没机会执行,而是有可能会被调度,但是抢不到锁,又回到blocked或者waiting状态(synchronized锁升级知识)一定是锁定同一把锁(即同一个对象)
同步的基本概念
monitor(管程)--> 锁的对象
critical section --> 临界区 大括号包围的区域
如果临界区执行时间长,语句多,叫做锁的粒度比较粗,锁了很多语句。反之,就是锁的粒度比较细
不是说锁的粒度越粗越好,也不是说锁的粒度越细越好,而是越合适越好,执行的时间和操作数量都有关系
具体:保障操作的原子性(Atomicity)
- 悲观的认为这个操作会被别的线程打断也叫做悲观锁synchronized
- 乐观的认为这个做不会被别的线程打断也叫做乐观锁 (自旋锁 无锁)
CAS操作 compare and swap 对比和交换 也有 compare and set 或者 compare and exchange 都是这个意思
CAS :读取值并改值 但在改值的过程中如果发现原来的值是一样的那么就改 如果不一样那么就重新读取值改值再进行对比。直到对比原来的值是一样的。就算完成进行改值
这样就会涉及到一个ABA问题,也就是其他线程修改数次最后值和原值相同
虽然很多情况下是可以忽视
但是极少情况下会在意。解决办法 加一个version
CAS除了ABA问题还有一个问题,CAS的前提必须是保障原子性,这时候就有一个Atomic类 来实现cas原理的表现
public class T0 {
private static AtomicInteger n = new AtomicInteger(0);
public static void main(String[] args) throws InterruptedException {
Thread[] threads = new Thread[100];
CountDownLatch latch = new CountDownLatch(threads.length);
for (int i = 0; i < threads.length; i++) {
threads[i] = new Thread(()->{
for (int j=0;j<10000;j++){
n.incrementAndGet();
}
latch.countDown();
});
}
for (Thread thread : threads) {
thread.start();
}
latch.await();
System.out.println(n);
}
}注意这里是没有加锁synchronized
.incrementAndGet方法意思就是n++,所以结果也是理所应当的100w。
以上就是并发编程的三大特性。

















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









