







增
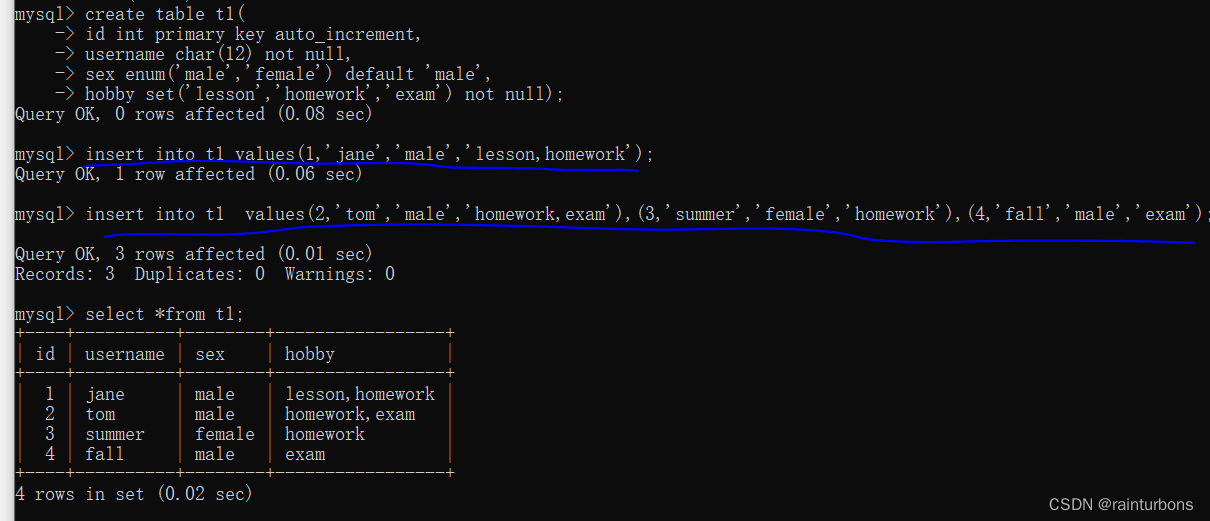

导入数据,拆分表的情况
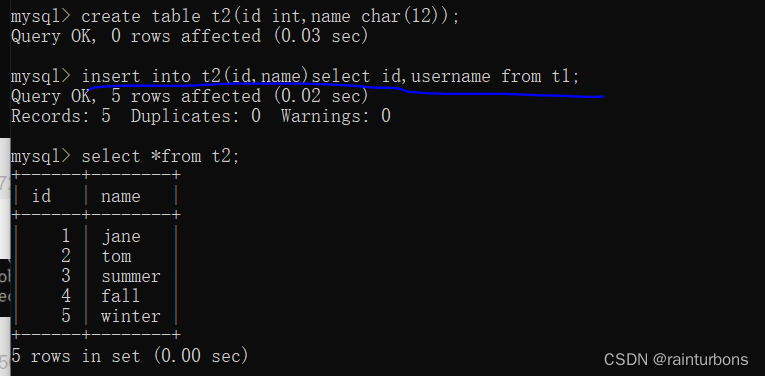
删
delete from 表名(只是删除表中的数据)会清空表,不会清空自增字段的offset值
truncate会清空自增字段的offset(偏移量)
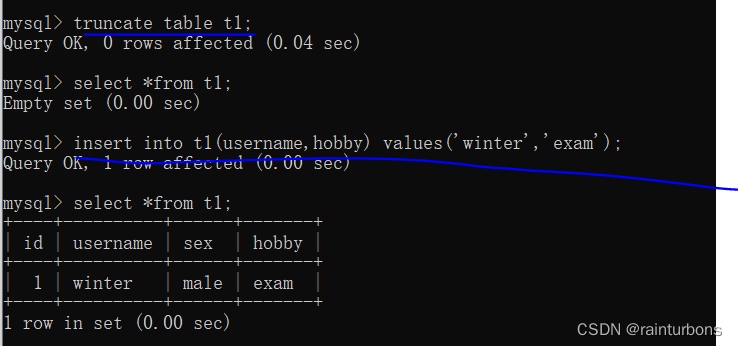
删除某一条数据必须带条件
delete from 表 where 条件;
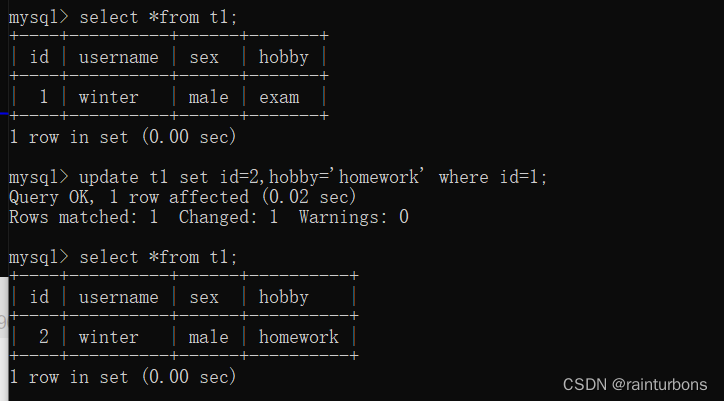
改
update 表名 set 字段=值 where 条件
update 表名 set 字段=值,字段=值 where 条件;
查
单表查询
四则运算计算

函数
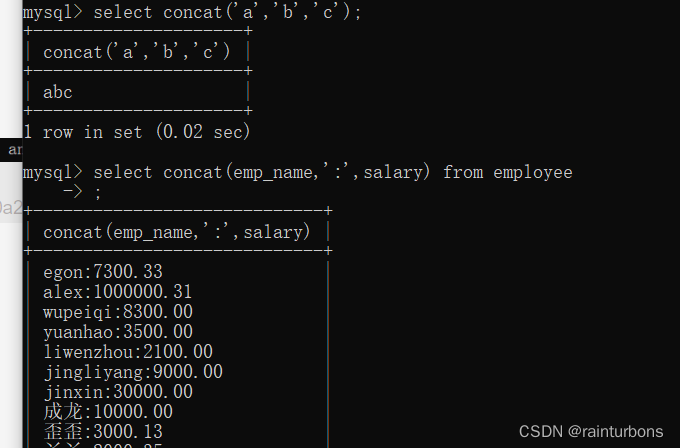
concat
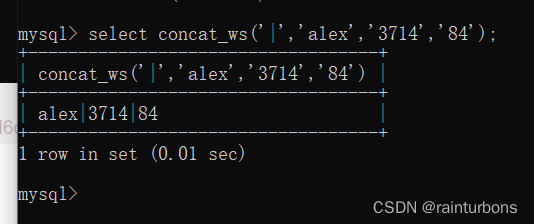
concat_ws
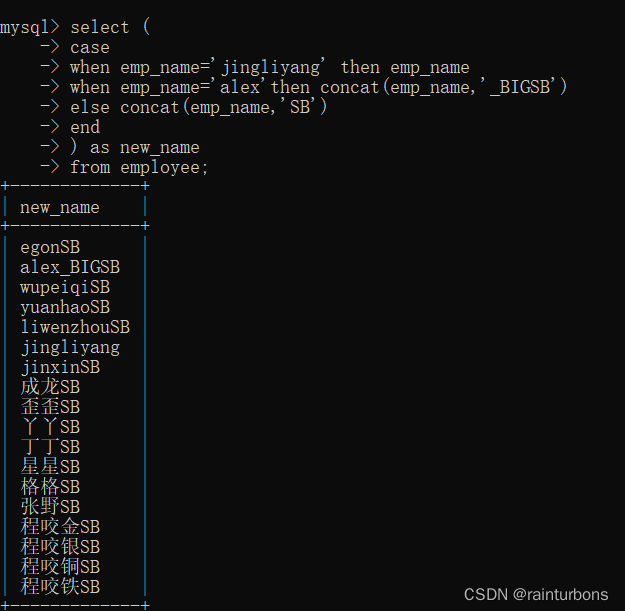
case…when:查出所有数据后,进行小改动,相当于判断。
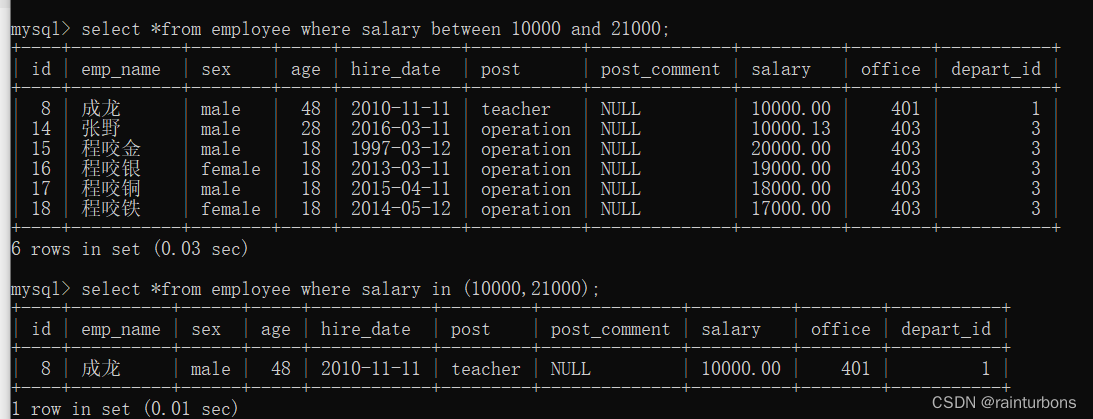
where筛选符合条件的行
1比较运算符> <>= <= <>(不等于) !=
2范围 between and in
in(10000,21000,18000)只要10000或者21000或者18000的
3.模糊匹配 like regexp
%通配符 任意长度任意内容

_一个字符长度的任意内容

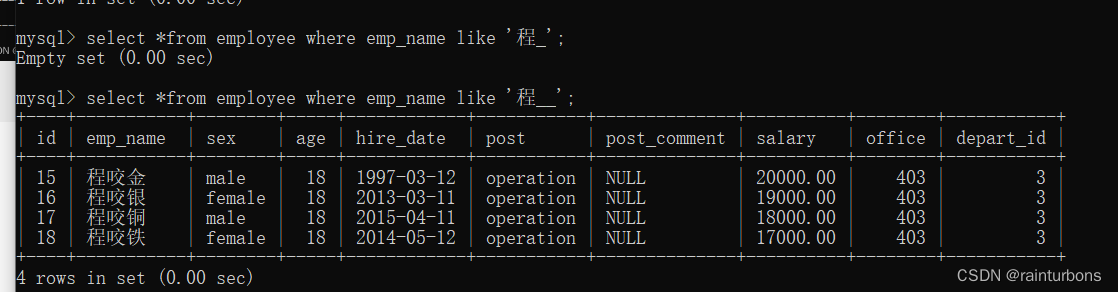
regexp正则匹配
$以什么结尾 ^以什么开头
 4逻辑运算 not and all
4逻辑运算 not and all
分组总是和聚合函数一起使用
聚合函数 count max min sum avg
group by 根据谁分组,可以求这个组的总人数,最大值,最小值,平均值,求和,但是求这出来的值只是和分组字段对应,并不和其他任何字段对应,这个时候查出来的所有其他字段都不生效。
group_concat但是实际编程用不了。只能看
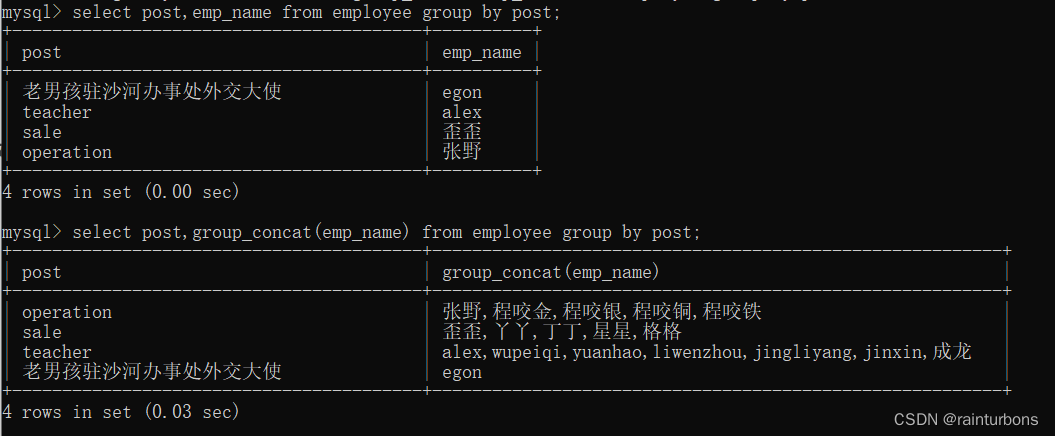
having 过滤语句
having条件中,可以使用聚合函数,在where中不行,
适合去筛选符合条件的某一组数据,而不是某一行数据。
先分组再过滤:求平均薪资大于的部门,求人数大于的性别,求大于**多少人的年龄段有几个
题目:
1 查询各岗位的员工个数小于2的岗位名,岗位内包含员工名字、个数。
2.查询各岗位平均薪资大于10000的岗位名,平均工资。
3.查询各岗位平均薪资大于10000且小于20000的岗位名,平均工资。
order by 默认是升序asc,desc降序
两个字段排,order by age,salary desc
:优先根据age从小到大排,在age相同时,再根据薪资从大到小排
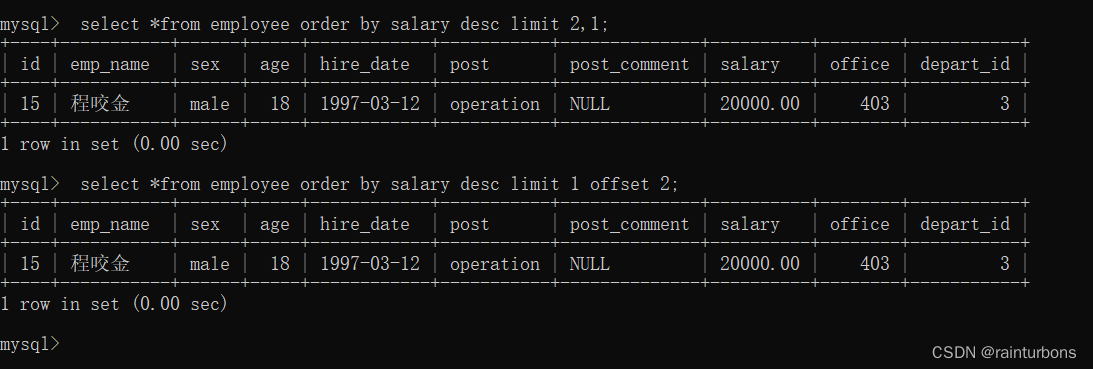
limit
limit m,n 从m+1 项开始,取n项
如果不写m,m默认从0开始
limit n offset m 从m+1 项取n项


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









