



 这篇博客介绍了Kaggle大学的SQL提高课程,内容涵盖JOINs和UNIONS的使用,分析函数的应用,以及如何处理嵌套和重复数据,最后讨论了如何写出更有效率的SQL查询。通过一系列的练习,如计算问题回答时间、查找无回答问题的用户、分析函数在预测出租车需求量中的应用等,深入理解SQL的高级技巧。
这篇博客介绍了Kaggle大学的SQL提高课程,内容涵盖JOINs和UNIONS的使用,分析函数的应用,以及如何处理嵌套和重复数据,最后讨论了如何写出更有效率的SQL查询。通过一系列的练习,如计算问题回答时间、查找无回答问题的用户、分析函数在预测出租车需求量中的应用等,深入理解SQL的高级技巧。
目录
第一节:joins and unions
介绍:使用的素材是两个表,一个是主人信息表,一个是宠物信息表。两个表依靠宠物的id来链接。往常我们使用的是inner join如今我们使用的是left join ,而left join 的意思就是我们的查询表包含左边的表的所有行。如果使用Full join则返回的是包含两个表中所有行的表。
union:垂直连接列,意思就是合并两个表,竖向合并。如果在union all时不想要重复值,可以使用UNION distinct
练习1:每个问题收到回答需要多久
这个教程做的非常好,先给出一个错误实例,看你怎么利用所学知识修改。
SELECT q.id AS q_id,
MIN(TIMESTAMP_DIFF(a.creation_date, q.creation_date, SECOND)) as time_to_answer
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
INNER JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON q.id = a.parent_id
WHERE q.creation_date >= '2018-01-01' and q.creation_date < '2018-02-01'
GROUP BY q_id
ORDER BY time_to_answer这是错误示例
结果是
Percentage of answered questions: 100.0% Number of questions: 134685
应该是差了很多 因为100%失去了查询的意义。所以这个练习说可能是采用的join类型无意中排除了未回答的答案。
结果把INNER改成LEFT就好了,提示是无论回答表中是否存在,应该保留问题表中的所有问题。
练习2:查找提出问题但没有提供答案的客户
我看了一下左边的是问题,右边的是回答,所以肯定要保留全部问题,因为可能有人只提出问题不回答,这也是题目所问的。
练习3:两个join
给的例子是查询主人宠物饲料三个表
主从关系是:主人和宠物都要包括,饲料表里有但是宠物表里没有的宠物视为没有
查询id,第一次创建问题的时间,第一次回答问题的时间
SELECT u.id AS id,
MIN(q.creation_date) AS q_creation_date,
MIN(a.creation_date) AS a_creation_date
FROM `bigquery-public-data.stackoverflow.users` AS u
LEFT JOIN `bigquery-public-data.stackoverflow.posts_questions` AS q
ON q.owner_user_id = u.id
LEFT JOIN `bigquery-public-data.stackoverflow.posts_answers` AS a
ON u.id = a.owner_user_id
WHERE u.creation_date >= '2019-01-01' AND u.creation_date < '2019-02-01'
GROUP BY id这里我第一次不是很理解,主要在这两个从属关系的表的顺序有无先后,后来发现并无,只要索引写对了就行,另外 WHERE也要注意,以谁为主
练习4:查询某日有多少用户发布信息(必须用UNION)
首先题目的条件是不同的客户,因此这里使用UNION DISTINCT
这个题目出的妙啊,把问题表和回答表UNION起来
SELECT q.owner_user_id
FROM `bigquery-public-data.stackoverflow.posts_questions` AS q
WHERE EXTRACT(DATE FROM q.creation_date) = '2019-01-01'
UNION DISTINCT
SELECT a.owner_user_id
FROM `bigquery-public-data.stackoverflow.posts_answers` AS a
WHERE EXTRACT(DATE FROM a.creation_date) = '2019-01-01'这里又用到了EXTRACT
还有一件事情就是,引用表时不能用"一定要用他的那个引号
第二节:分析函数
我一直都以为SQL不需要函数,只要提取出来就行了,但是看了看一些关于求职的帖子,好像SQL是他们主要的工具,要更精通一点,我今天先把这些学了,下一次再好好搞一搞存储过程。
他给的例子是计算一个运动员每天跑100米的时长平均值。

所有分析函数都有一个over子句,它定义了计算中所使用的行集,over子句中一共有三个部分:
PARTITION BY 子句将表的行划分为不同的组。
ORDER BY 子句定义了每个分区内的排序。
最后一个子句(ROWS BETWEEN 1 PRECEDING AND CURRENT ROW)称为窗口框架子句。 它标识每个计算中使用的行集。 我们可以将这组行称为一个窗口。 (其实解析函数有时也被称为解析窗函数或者简称窗函数。
ROWS BETWEEN 1 PRECEDING AND CURRENT ROW - 前一行和当前行。
ROWS BETWEEN 3 PRECEDING AND 1 FOLLOWING - 前 3 行、当前行和下一行。
ROWS BETWEEN UNBOUNDED PRECEDING 和 UNBOUNDED FOLLOWING - 分区中的所有行。
这些是更多的窗口函数。
三种类型:
1.聚合函数
MIN()(或 MAX()) - 返回输入值的最小值(或最大值)
AVG()(或 SUM()) - 返回输入值的平均值(或总和)
COUNT() - 返回输入中的行数
2.导航函数
FIRST_VALUE() (或 LAST_VALUE()) - 返回输入中的第一个(或最后一个)值
LEAD()(和 LAG()) - 返回后续(或前面)行的值
3.编号函数
ROW_NUMBER() - 返回行在输入中出现的顺序(从 1 开始)
RANK() - 排序列中具有相同值的所有行接收相同的排名值,其中下一行接收一个排名值,该值增加具有前一个排名值的行数。
练习1:预测出租车需求量
这个题目的功能就是和excel与python数据分析重复的,可能有他一定的存在的意义吧。
要求想要得到出租车每日的出行次数
可是他很奇怪,并不是直接算次数,而是要输出两列,一列是日期,另一列是平均每日出行次数
WITH trips_by_day AS
(
SELECT DATE(trip_start_timestamp) AS trip_date,
COUNT(*) as num_trips
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE trip_start_timestamp >= '2016-01-01' AND trip_start_timestamp < '2018-01-01'
GROUP BY trip_date
ORDER BY trip_date
)
SELECT trip_date,
AVG(num_trips)
OVER (
ORDER BY trip_date
ROWS BETWEEN 15 PRECEDING AND 15 FOLLOWING
) AS avg_num_trips
FROM trips_by_day说几个注意的点
公共表达式
分析函数求的是平均出行次数
order by 分区
然后ROWS是筛选想要的行
这是公共表达式查询的结果
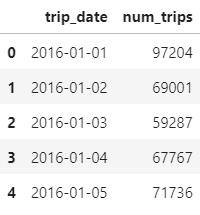
这是整体的结果
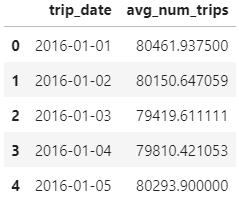
avg_num_trips - 显示在一个窗口内计算的平均每日出行次数,包括当前日期的值,以及前 15 天和后 15 天的值,只要这些天数在两年的时间范围内.例如,在计算此列中 2016 年 1 月 5 日的值时,窗口将包括前 4 天、当前日期和后 15 天的出行次数。
这是教程给的解释
我对这种计算平均值的方法感觉到很迷惑。
练习2:分区
无疑就是加一个条件
SELECT pickup_community_area,
trip_start_timestamp,
trip_end_timestamp,
RANK()
OVER (
PARTITION BY pickup_community_area
ORDER BY trip_start_timestamp
) AS trip_number
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE DATE(trip_start_timestamp) = '2017-05-01'这个地方疑问也很多,over就用来干这个?
练习3:两次旅行之间耗费了多长时间
这里使用了一个求时间差的东西,我还搞不太懂,以后再学学
SELECT taxi_id,
trip_start_timestamp,
trip_end_timestamp,
TIMESTAMP_DIFF(
trip_start_timestamp,
LAG(trip_end_timestamp, 1)
OVER (
PARTITION BY taxi_id
ORDER BY trip_start_timestamp),
MINUTE) as prev_break
FROM `bigquery-public-data.chicago_taxi_trips.taxi_trips`
WHERE DATE(trip_start_timestamp) = '2017-05-01' 第三节:嵌套和重复数据
引入一种新概念,嵌套列,在这一列里有两种不同类型的数据

这个就是嵌套,把这两个表合成一个表会更容易观看
但这明显不是存储数据的形式,会造成资源的极大浪费,而且如果想做这样的事的话,真就excel
谁叫他想做呢?
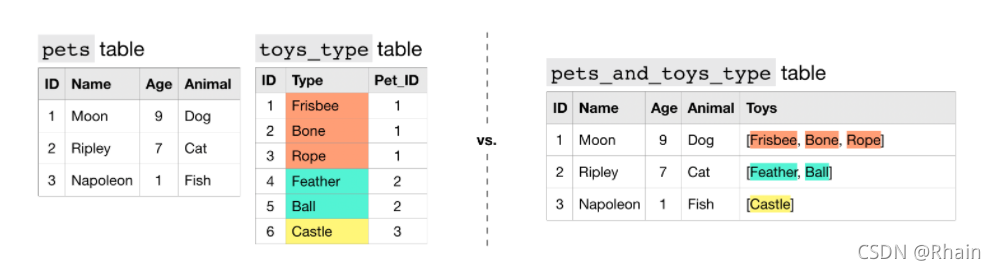
这个叫做重复,表二是很标准的存储格式,但是不够直观,需要进行处理
处理嵌套数据时:
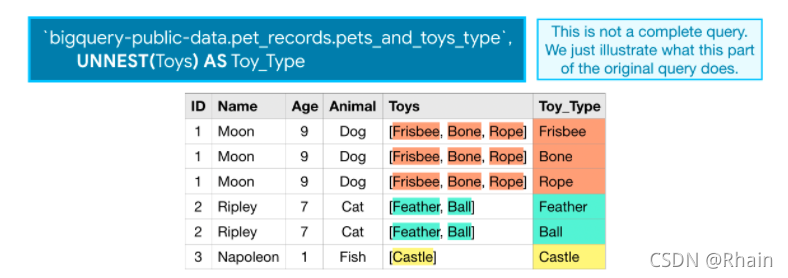
使用一个UNNEST函数,这个函数的大概作用如此。
处理嵌套又重复的数据:

这是另一种问题的处理方法。
练习1:最流行的编程语言是什么?
SELECT l.name as language_name, COUNT(*) as num_repos
FROM `bigquery-public-data.github_repos.languages`,
UNNEST(language) AS l
GROUP BY language_name
ORDER BY num_repos DESC 这里新奇的东西就是 UNNEST AS 1,和案例一样。但是我还是不太懂。
ε=(´ο`*)))唉,我要是在工作就好了,这样会有紧迫感,有压力就会学的快一点。
但是在没有压力时精力充沛的去学习一样东西也是好事。
练习2:存储库中那些语言使用最多?
SELECT l.name, l.bytes
FROM `bigquery-public-data.github_repos.languages`,
UNNEST(language) as l
WHERE repo_name = 'polyrabbit/polyglot'
ORDER BY l.bytes DESC第四节:书写更有效率的sql
首先这个教程引入了两种方法,
show_amount_of_data_scanned() shows the amount of data the query uses.show_time_to_run() prints how long it takes for the query to execute.
接下来引入比较
1.只查询你想要的行而不是所有:*和size 比较当然查询所有信息会占用更多内存。
2.如有可能读取尽可能少的数据:查询姓名与查询id
3.避免N:N的连接:使用公共表达式来改变N:N的情况
练习1:哪个查询最有效率
项目背景,你是一家国际宠物服装公司的员工,现在我们要评估一下哪个查询最有效率
1.一位软件工程师为运输部门编写了一个应用程序,以查看哪些项目需要运输,以及这些项目要去仓库的哪个通道。她想让你写这个问题。它将涉及存储在订单表、装运表和仓库位置表中的数据。运输部门的员工将在平板电脑上启动此应用程序,点击“刷新”,您的查询结果将显示在一个漂亮的界面中,这样他们就可以看到要将哪些服装发送到哪里。
2.首席执行官想要一份所有客户评论和投诉的列表……这些评论和投诉可以方便地存储在一个评论表中。有些评论真的很长…因为人们喜欢你为鹦鹉设计的海盗服装,他们不停地写他们有多可爱。
3.养狗的人比以往任何时候都受到更多的保护。所以你们的工程部门用嵌入式GPS跟踪器和无线通信设备制作了服装。他们每秒向你的数据库发送一次服装坐标。然后你就有了一个网站,主人可以在那里找到他们的狗的位置(或者至少是他们为这些狗准备的服装)。要使此服务正常工作,您需要一个查询,显示给定人员拥有的所有服装的最新位置。这将涉及CustomLocations表和CustomOwners表中的数据。
答案是3
原因3:因为每秒都会发送每个服装的数据,所以这个查询可能涉及最多的数据(到目前为止)。它将定期运行。因此,写这口井可以在反复的基础上获得回报。
为什么不是1:这是要优化的第二个最有价值的查询。它将定期运行,并涉及合并,这通常是一个可以提高查询效率的地方
为什么不呢2:听起来它只会运行一次。所以,这可能并不重要,如果它需要几秒钟额外或成本几美分运行一次。而且,它不涉及连接。虽然数据有文本字段(评论),但这是您需要的数据。因此,您不能在select查询中保留这些内容来保存计算。
可能运行次数最多的应该是最有效率的吧。
练习2:更快更节约
通过服装地址和服装主人的两个表来建立查询
WITH LocationsAndOwners AS
(
SELECT *
FROM CostumeOwners co INNER JOIN CostumeLocations cl
ON co.CostumeID = cl.CostumeID
),
LastSeen AS
(
SELECT CostumeID, MAX(Timestamp)
FROM LocationsAndOwners
GROUP BY CostumeID
)
SELECT lo.CostumeID, Location
FROM LocationsAndOwners lo INNER JOIN LastSeen ls
ON lo.Timestamp = ls.Timestamp AND lo.CostumeID = ls.CostumeID
WHERE OwnerID = MitzieOwnerID这个从服装拥有者和所有服装地址找出所有筛选项。
如何优化
WITH CurrentOwnersCostumes AS
(
SELECT CostumeID
FROM CostumeOwners
WHERE OwnerID = MitzieOwnerID
),
OwnersCostumesLocations AS
(
SELECT cc.CostumeID, Timestamp, Location
FROM CurrentOwnersCostumes cc INNER JOIN CostumeLocations cl
ON cc.CostumeID = cl.CostumeID
),
LastSeen AS
(
SELECT CostumeID, MAX(Timestamp)
FROM OwnersCostumesLocations
GROUP BY CostumeID
)
SELECT ocl.CostumeID, Location
FROM OwnersCostumesLocations ocl INNER JOIN LastSeen ls
ON ocl.timestamp = ls.timestamp AND ocl.CostumeID = ls.costumeID优化就是直接查询Mitzie的服装id
没有太多的感受,下一步我就去牛客网好好练练

















 2921
2921

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









