



视觉无意盲视引导下的道路驾驶安全提升
摘要
近年来,人类视觉注意的计算建模受到广泛关注。在先进的工业应用中,已证明计算视觉注意模型(CVAMs)能够以与人类视觉注意非常相似的方式预测视觉注意力。然而,驾驶员的眼动注视位置(EFL)与计算视觉注意模型预测的眼动注视位置相比,哪一个对实际驾驶更可靠、更有帮助,仍存在争议。为解决这一问题,建立了一个包含日常驾驶中最常见的18种驾驶条件下的视频开放数据库。通过使用该数据库进行的实验发现,仅依赖两种EFL中的一种对驾驶员而言并不充分。基于此发现,提出了一种混合EFL推荐策略,以提升驾驶安全。该推荐方法通过从人类动态视觉中提取视觉特征,展现出在所收集的驾驶任务中的潜在价值。此外,进一步考虑了驾驶视觉舒适性以增强驾驶安全性。通过对108段真实驾驶条件下最常见的18种驾驶视频片段进行实验,结果表明,所提出的EFL推荐策略在驾驶舒适性体验评分中达到了100分中的88.1至92.7分。
索引词 —道路驾驶安全,无意视盲,眼固定。
I. 引言
HUMAN 视觉能够相对轻松地处理复杂的动态场景。这是因为注意系统能够有效选择最相关的线索,尤其是在驾驶等动态场景中[1]。然而,也有报道称,感知盲(如公路催眠)是导致道路交通事故的主要原因之一[2]。因此,在复杂驾驶条件下开发一种CVAM以弥补人类视觉的局限性,可通过提出专家级驾驶员眼动注视位置(EFLs)来辅助驾驶员。基于三名专家驾驶员对是否
手稿收到日期2019年12月6日;2020年7月1日和2020年9月11日修订;2020年12月10日接受。本工作部分由国家自然科学基金项目号 61922064和项目号U2033210资助,部分由浙江省自然科学基金项目号 LR17F030001和项目号LQ19F020005资助,部分由温州市科技计划项目项目号C20170008和项目号ZG2017016资助。本文的副编辑为S. 哈姆达尔。(通讯作者:张小琴。)许佳伟、张小琴和胡杰隶属于中国温州大学计算机科学与人工智能学院,温州 325035(电子邮件: jxulincoln@gmail.com;zhangxiaoqinnan@gmail.com; israel1987@126.com)。朴燮炯隶属于韩国春川韩林大学软件学院, 韩国春川24252(电子邮件:spark@hallym.ac.kr)。数字对象标识符 10.1109/TITS.2020.3044927
驾驶员的EFL或CVAM预测的EFL哪种更适用于驾驶安全,本文提出了一种针对驾驶任务的EFL推荐策略。该策略的最终目标是降低视觉诱发的道路交通事故的发生概率。
从另一个角度来看,考虑到视觉注意的计算建模[3]的快速发展,引入一种先进的视觉注意模型来预测不同驾驶条件下的EFLs可能具有优势。然而,驾驶员视觉注意受到人类视觉多个方面的影响,例如时空规律性、中心偏向、个体差异、响应模式、驾驶疲劳以及其他人为因素[4],[5]。因此,更倾向于引入能够恰当反映这些人为因素的CVAMs。最近在[6]中提出了一种生物启发式视觉注意模型。该模型包含了驾驶员在驾驶过程中涉及的若干代表性人为因素,并已在室内测试环境中验证了其有效性。
驾驶员的EFLs和CVAMs预测的EFLs在实际应用中各有优缺点。在长途高速公路驾驶中,当真实情况存在纯粹主观偏差时(例如,道路催眠现象[2]),驾驶员容易发生碰撞事故。在这种情况下,驾驶员倾向于注视某个静态点,导致人类注意系统容易忽略一些关键的视觉线索。
尽管近期的视觉注意模型(如[3]中所综述)在成功检测关键视觉信息方面表现出优越性,但在模拟人类视觉注意系统的固有特性方面仍存在困难,具体包括:预测性视觉[7],、胜者通吃神经网络[8]以及在自然条件下的自适应深度感知[9],尤其是在驾驶任务中的应用。
驾驶中的人为因素,如个体差异、驾驶经验和其它个人偏见,可能会影响驾驶安全。然而,视觉无意盲视是不同驾驶任务下可能导致潜在危险的常见人为错误之一。重要的是,根据大量车祸研究的报告,视觉无意盲视是导致致命碰撞的关键因素([22]和[43])。因此,文献[10]提出了一种眼跳落点推荐方法,并针对不同驾驶条件推荐了三种类型的眼跳落点,即仅驾驶员的眼动兴趣区域(EFL)、仅CVAM的EFL以及可切换眼跳落点。然而,该方法存在若干局限性。首先,采集的数据库仅包含10种非恶劣天气驾驶条件,有必要纳入更多复杂道路条件。其次,支持向量机 11 在少量数据样本时表现良好,但在大量数据样本时则不尽如人意。因此,通过用更高效的分类器替代支持向量机,可以提升性能。第三,[10]中使用的大多数提取特征并未受到人类视觉注意生物特性的启发。
最近,一种时空CVAM[12]被引入用于计算预测的EFLs。然而,该CVAM缺乏对人为因素的深入考虑,特别是驾驶所需的视觉的人为因素。为了弥补这些不足,本研究提出了一种新的EFL推荐策略,以实现安全舒适的驾驶。驾驶安全推荐策略的贡献可总结如下。
- 通过从视觉的人为因素中提取8种新特征并构建神经网络模型,参考专家真实值选择EFLs或预测的EFLs的准确率可达约95%,为后续实施奠定了坚实基础。
- 推荐的EFL在包含108段驾驶视频片段的驾驶视频数据库中经过充分测试,这些视频片段采集自最常见的18种真实驾驶条件。
- 经过广泛的主观测试,所提出的指南明显提升了驾驶视觉舒适性,极大地促进了安全驾驶目标的实现。
本文的结构如下。在第二节中,简要总结了现有的相关研究。第三节阐述了所提出的策略。第四节详细介绍了适用性分析。最后,第五节给出了结论。
II. 相关研究
本节简要回顾了关于计算视觉注意模型的前期研究,并进一步总结了人类视觉注意的优点与缺点。最后一个小节讨论了驾驶视觉舒适性对于驾驶安全的重要性。
A. 驾驶任务中视觉注意力的计算建模
人类视觉注意的计算建模已从最早的特征整合理论[13], 、自上而下与自下而上的调节[14],和时空计算[15],、受生物启发的仿生注意模型[16],以及受注意机制启发的图像去雾技术[17]等方面得到了广泛发展。然而,尽管这些方法显著提升了图像和视频数据库的准确性,但其中很少有研究深入且充分地解决真实驾驶任务中视觉的人为因素问题。例如,中心偏向、新手与经验丰富的驾驶员之间响应模式的个体差异以及时空规律性,是驾驶过程中人类视觉注意的典型特征。然而,这些关键的人为因素在当前的计算视觉注意模型[3]中并未得到充分反映。作为动态自然场景的固有属性,时空规律性通常被利用
由人类视觉系统有效处理视觉输入。因此,人类能够轻松地关注预期的目标和/或位置,以进行视觉追踪或目标分析,并提高感知敏感性[18],[19],,同时忽略在动态场景中虽具有高物理显著性但不符合时空规律性的物体。最近,提出了一种考虑人类视觉多个代表性因素的时间不可逆视觉注意模型,并在室内外测试中验证了其有效性[6]。鉴于该模型的上述优势及其与人类基准的高度相似性,本研究采用了该模型来获取在某些复杂驾驶条件下预测的EFLs。下一节将提供详细分析。
B. 来自人类视觉注意的生物启发
人类视觉注意经过高度进化,以满足驾驶中的感知负荷需求。由于注意系统的进化能够选择最相关的视觉线索,尤其是在驾驶条件下,经验丰富的驾驶员可以轻松应对复杂的动态场景。研究还证明,经验丰富的驾驶员会专注于主要任务,例如捕捉与任务相关的刺激中的关键视觉特征,并过滤掉其他视觉线索,这表明了人类视觉的优越性。相比之下,当前的计算机视觉技术需要更高的硬件配置要求,例如GPU或CUDA。这证明了人类视觉注意的生物学合理性和其在驾驶任务中的潜在价值。
相反,视觉无意盲视通常在高感知负荷条件下驾驶任务期间的视觉意识中发生[20]。在早期的一项心理学研究中,通过在特定视觉任务下产生额外/更高的感知负荷,例如驾驶过程中存在许多具有挑战性的交通标志和行人,研究发现这些干扰效应会分散视觉注意力并显著降低表现[20]。这可能导致做出错误决策,甚至引发车辆碰撞[21]。
这表明人类感知在驾驶条件下是有限的[22],,这也促使作者引入了此前提到的最新CVAM。此外,当引入视觉刺激的变化而观察者未能察觉时,通常会发生变化盲视[23]。
人类视觉注意的局限性受到多种外部因素的影响,例如亮度、视觉复杂性和个体差异[24]。变化盲视是一种影响驾驶表现的视觉人为因素,已被证实会导致驾驶时分心[25]。
基于这些视觉人因的优缺点,本研究提出了一种安全驾驶策略,以确定在不同驾驶条件下优化的EFLs。
C. 驾驶时眼睛的舒适度
众所周知,驾驶员视觉注意的表现可能因多种因素而下降。其中一个因素是
主要原因是生理或心理疲劳。在之前的一项研究中,驾驶任务的测试时间被限制在1小时内,旨在防止生理和心理疲劳[26]。然而,已证实连续进行驾驶任务可能引发生理或心理疲劳[27]。一项早期的脑电图研究使用了17名经验丰富的驾驶员发现,设置过高的感知负荷会使反应时间和准确率降低约30%[28]。相反,在较为简单的驾驶任务中,尤其是在视觉复杂性较低的情况下(例如乡村高速公路),视觉困倦更易发生[29]。对于人类视觉而言,过高或过低的感知负荷都会对驾驶视觉舒适性产生负面影响[30]。最近的一项研究[31],进一步表明,驾驶视觉舒适性与驾驶安全直接相关且相互影响。换句话说,如果驾驶员由于任何生理、心理或认知原因感到不适,则不安全驾驶的可能性将增加。因此,利用实地测试数据来改善驾驶视觉舒适性至关重要。
III. 驾驶安全建议
本节首先介绍了所提出的驾驶安全建议。进一步分析了驾驶任务过程中可能出现的负面人为因素。为克服人为错误,采用了最新的CVAM用于驾驶任务。最后一小节阐述了所提出的指南,旨在改善驾驶视觉舒适性,以最终实现驾驶安全。在图1中,设计了一个预定义的安全驾驶策略,下一节需要进行适用性分析以修改该预定义策略。
A. 提出的安全驾驶策略
据报道,恶劣天气驾驶条件会对驾驶员的体验产生不良影响[32],[33]。因此,有必要通过CVAMs实现最佳解决方案,以克服这种潜在的人为错误。受此启发,在所提出策略的第一步中,建议在雨、雾或雪天以及夜间驾驶等恶劣天气驾驶条件下使用预测的EFLs。
第二步是确定在非恶劣天气下,驾驶员的EFLs是否位于中心区域。
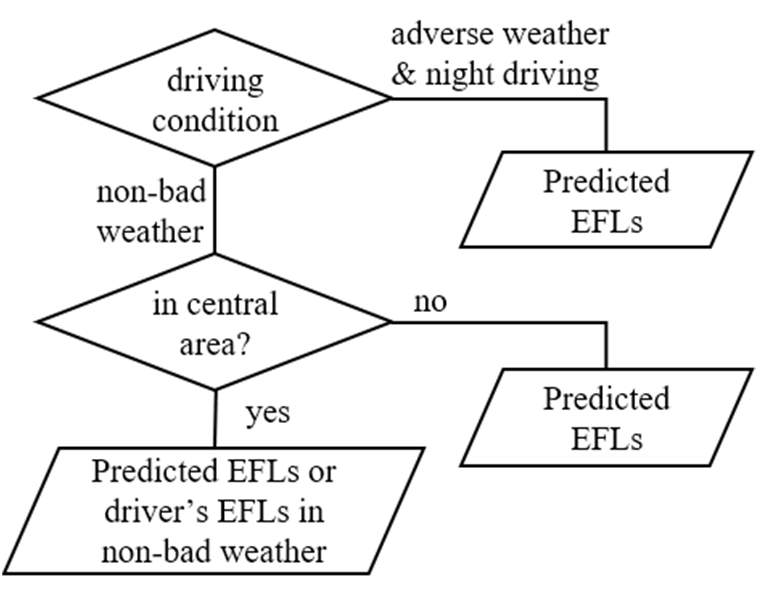
假设输入图像帧为W×H像素,即H行、每行W像素。中心区域定义为一个内部同心矩形图像,其尺寸为 λx H行、每行 λyW像素,其中λx和 λy分别为图像宽度和高度的缩放因子1。如果选定的EFL超出该中心区域,则优先采用预测的EFL;否则,推荐使用驾驶员的眼动兴趣区域(EFL)。
第三步是确定在不同非恶劣驾驶条件下的合适EFLs或预测的EFLs。通过使用驾驶员的眼动兴趣区域(EFL)和预测的EFLs进一步分析其可行性。最后,一旦确定了驾驶员的EFL或预测的EFL,就会处理下一帧,以推荐使用驾驶员的EFL或预测的EFL,相关内容将在下一小节中讨论。
图1展示了所提出的安全驾驶策略的直观结构。
值得一提的是,本研究采用了一种时间不可逆 CVAM,在动态视觉场景下针对视觉的人为因素,测试眼固定及其对应的视觉关注区域[6]。该CVAM在多种具有挑战性的室内视觉刺激条件下已验证其有效性。受其独特优势的启发,本研究将该CVAM应用于预测在16种真实驾驶条件下的EFLs。图2展示了由生物启发的视觉注意模型[6]生成的四个典型结果。红色圆圈表示视觉关注区域,预测的EFL位于每个视觉关注区域的中心点。圆的直径设置为5像素,用以表示作为视觉注意区域的关注区域,即视网膜解剖学黄斑。
B. 视觉无意盲视分析
导致道路交通事故的关键人为错误之一是通过测量16种常见驾驶条件下的视觉无意盲视进行研究的。视觉无意盲视也被称为感知盲视的基本前提,当驾驶员专注于某项特定任务时就会发生。在这种情况下,他们不太可能注意到周围的事件,即使这些视觉刺激是在其视野内的显著物体,例如交通标志。这是可能导致潜在危险或致命碰撞的一个关键因素。另一个相关现象是变化盲视,这表明我们并未像想象中那样编码那么多的细节,因为两个或多个连续帧之间的变化并未改变场景主旨。
1在本文中,λ x 和λ y 通过收集所有参与者的眼固定点来模拟人类中心偏差,被设为0.724。

驾驶任务。基于视觉感知盲区,所提出的策略是根据表I中列出的16种常见驾驶条件下场景主旨的缺失而设计的。换句话说,在驾驶任务下所有显著物体均由三位专家标注,并记录了所有参与者未注意到的视觉物体数量,如表I所示。
所有这些未被注意的视觉物体都被评估为与驾驶任务相关的信息;然而,它们却被驾驶员EFLs所忽略。由此表可得出结论,在恶劣天气下,感知盲区实例的数量最多。
表I显示,在恶劣天气条件下的感知盲区实例数量大于非恶劣天气条件下的数量。这意味着在恶劣天气条件下,依赖驾驶员EFLs并不可取。先前的研究证明了人类驾驶员在此类恶劣天气驾驶条件下的表现较差[34]。然而,在交叉路口、停车和交通信号灯情况下,该数量也相对较大。
C. 驾驶视觉舒适性提升
如第二节所述,驾驶视觉舒适性对驾驶安全具有积极影响。因此,在满足上一小节所讨论的驾驶安全需求后,我们通过制定指南更进一步地提升了驾驶视觉舒适性。通过实地测试来提升驾驶视觉舒适性至关重要。本研究重点关注意了EFLs及预测的EFLs对驾驶员眼睛的视觉舒适度。
理论上,鉴于视觉疲劳、驾驶参与感以及驾驶员压力水平可能成为真实驾驶场景中驾驶体验的三大不利因素,驾驶员EFLs与预测的EFLs之间的过于频繁的切换可能会在所有16种驾驶条件下对视觉舒适度产生负面影响。因此,建议采取以下指南以改善驾驶体验。
- 对于Parking、Traffic light和Junction情况,使用可切换EFL时,任一模式(驾驶员的EFL或预测EFL)应至少持续1秒(30帧),因为驾驶员的EFL与预测EFL之间过于频繁的切换会不利地影响驾驶体验。如果在第一帧选择了任一模式,则该模式将至少持续1秒,之后再切换到另一种模式。
- 在恶劣天气条件下(night、下雨、有雾、下雪、雨夹雪,和 雾霾),由于人为错误似乎是导致事故的致命原因,因此建议采用预测的EFLs。然而,大多数参与者抱怨完全使用预测的EFLs会带来枯燥的驾驶体验,因此在恶劣天气条件下需要轻微干预。通过收集预测的EFLs和驾驶员的EFL,建议在一段30分钟的驾驶过程中插入驾驶员EFL 1分钟(1800帧),其余29分钟使用预测的EFL。这是因为如果人类驾驶员完全失去控制,可能会变得困倦
表I(续) 驾驶员EFLs与预测的EFLs所关注的对象及驾驶员的无意视盲
第一步给出驾驶安全建议。然而,在采用上述两条指南后,针对所有驾驶条件的EFLs和预测的EFLs的选择均得到更新。随后通过户外驾驶测试进一步验证这些所提指南的合理性,详见下节阐述。
IV. 适用性分析
本节首先收集并描述了一个从真实道路驾驶车辆获取的视频片段数据库。此外,进一步进行了适用性分析,以评估所提出建议在实现驾驶安全方面的可行性。视觉舒适度测试在道路驾驶安全的前提下得到了进一步验证。最后一个小节给出了讨论与比较。

A. 实验设置
林肯大学心理学学院批准了本研究。所有相关措施、条件和数据排除情况均已报告,样本量基于作者之前的研究所确定[1]。共有35名成年人(7名女性,28名男性)自愿参与本研究,年龄范围为21至42岁,平均年龄为32.4 ± 0.42(均值 ± SEM)。所有参与者均具有至少一年的驾驶经验(驾驶记录达10000英里)。所有参与者均具有正常或矫正后正常的视力,以及正常色觉(通过石原色盲检测(24板版)验证)。从16种多样化的驾驶条件中采集了96段高清彩色视频片段,并使用安装在汽车挡风玻璃上的数码摄像机进行录制。我们避免了环境条件变化的不平衡,例如在非恶劣天气的高峰时段驾驶或在下雨天的非高峰时段驾驶。为此,数据采集时间为上午8:00至晚上8:00,涵盖了高峰和非高峰时段的驾驶任务。照度水平在非恶劣天气下为7500 lx至10000 lx,夜间驾驶时为50 lx至850 lx,其他驾驶条件下为500 lx至6000 lx。
本研究设计的视频片段由松下HX‐DC3摄像机以每秒30帧、640×480像素的分辨率拍摄。摄像机固定在三脚架上,以确保良好的图像质量。公开可用的自然驾驶数据库包含96个视频片段,分为四种不同类型的修改后的视觉刺激:正常视频、反向视频、抽象帧和随机帧。正常视频表示该片段以其原始的、可预测的顺序播放(从 1st到 90th帧)。反向视频是同一片段以反向运动或时间倒序播放(从90th到 1st帧)。正常图像序列指从视频序列的开始、中间和结束位置分别采样六个静态画面(即 1st、16th、31st、46th、61st和 76th帧),然后按原始顺序呈现,每个静态画面显示500毫秒。随机图像序列是指相同的六个静态画面以随机顺序呈现,每个画面持续500毫秒。图3展示了在恶劣天气驾驶条件下(即雪天和雾天)随机选取的两个帧。该驾驶视频数据库旨在收集驾驶员在现实生活情境中最可能遇到的驾驶任务。所有视频片段均在英国(一个左舵驾驶国家)采集。一半的原始视频在恶劣天气条件下拍摄,即雨天、雾天、雪天和夜间条件,另一半则在非恶劣天气条件下采集。
视觉刺激呈现在一台非隔行扫描的伽马校正彩色显示器上(背景亮度为30 cd/m²,100 Hz 刷新率,三菱 Diamond Pro 2070SB),分辨率为1,024 × 768像素。通过自由观看任务获取人类参与者的眼动兴趣区域(EFLs)。在57 厘米的观看距离下,显示器所占视角为 40 × 30◦。在本眼动追踪研究中,已去除背景声音。当参与者对注视点(FP)注视一秒钟后,完成眼动仪校准。在校准过程结束后,每次试验开始时,屏幕显示区域的四个角会呈现四个注视点(FP)。为了减少观看时的初始中央注视偏差,要求参与者随机选择其中一个注视点进行凝视。当参与者持续视觉凝视该注视点达一秒钟后,注视点消失,随后在屏幕中央显示测试视频片段。在自由观看过程中,参与者被要求以正常方式观看视频片段。所有参与者共观看了30个驾驶视频片段。根据实验结果,将其眼固定点汇总为驾驶员的眼动兴趣区域(EFL)。
B. 所提EFL推荐的适用性分析
根据表I中所有单向驾驶任务下较低的视觉无意盲视发生率(平均1.93),由于驾驶员的眼动兴趣区域(EFL)模式具有人类视觉的生物学合理性,并且相对较少消耗视觉资源,因此建议在单向单车、单向行人、单向跟车、单向对向车流和单向跟随对向车流条件下采用该模式。
然而,即使每个驾驶任务中的视觉无意视盲次数在两到六次之间,由于在高速公路驾驶任务下的长途驾驶可能会增加视觉困倦的可能性,因此在Motorway driving条件下更倾向于选择预测的EFL模式。
考虑到恶劣天气下因人类感知错误导致的汽车碰撞事故数量显著,因此建议在恶劣天气(下雪、有雾、下雨、雨夹雪和雾霾驾驶)以及夜间驾驶的驾驶任务中采用预测的EFL模式。需要注意的是,在实地测试中,夜间驾驶时间设定为下午6:30开始。
此外,从表I中观察到驾驶员视觉无意盲视现象较为显著。在停车、交通信号灯和交叉路口情况下,视觉复杂性水平较高。因此,预测的EFLs与驾驶员EFLs在停车、交通信号灯和交叉路口情况下进行了整合。
根据上述分析,推荐的EFLs分类列于表二。
为了验证该建议,通过考虑真实驾驶任务中视觉的人为因素,提取了以下8个特征。
- 对于一个包含F帧的视频片段,设Tf和Tf−1分别为CVAM m在当前帧f和前一帧f−1中预测的关注对象总数。增加的在第f帧与第(f−1)帧之间检测到的显著物体数量记为Df = Tf − Tf−1,其中Df被用作输入特征。
- 对于由F帧组成的给定视频片段,设(φd1, φd2,···, φdF)和(φ1m, φ2m,···, φmF)分别为驾驶员的EFLs序列和由CVAM m预测的EFLs序列。令(φ1, φ2,···, φF)为优选的EFLs序列,其中 φf = αfφdf + (1−αf)φmf,1 ≤ f ≤ F,且αf是第f帧的真实选择参数,满足αf = 1或αf = 0。驾驶员的EFLs和预测的EFLs在两个连续帧之间的欧几里得距离分别用作两个输入特征。
- 对于视频片段中的第f帧,设S1f和S2f分别表示CVAM m在第f帧中预测的最大和第二大显著物体的尺寸。令r1f = (S1f − S2f)/S1f。如果r1f ≤ 0.2,则说明这两个显著物体在人类视觉感知中几乎同等重要,这将导致人类注意力分配出现困难决策,此时应将驾驶员EFLs和预测的EFLs作为输入特征,通过神经网络进行分类。
- 对于给定的视频片段,设r2f = (S1f − S1f−1)/S1f。如果r2f ≥ 0.2,则推荐使用时间不可逆CVAM预测的EFLs。这是因为后退移动的物体可能不再构成潜在危险,人类视觉注意能够轻松处理这种视觉负担。推荐EFLs的原因在于人类视觉具有节能性且在生物学上更合理。相反,尺寸快速增大的物体可能是潜在危险,会给眼睛带来额外的感知负担。
- 考虑到时空规律性是驾驶任务中视觉的人为因素的关键之一,输入神经网络的特征之一是正常视频序列与反向视频序列在同一帧处EFLs的欧几里得距离。
- 与EFLs类似,另一个特征是正常视频序列和反向视频序列在同一帧处预测的EFLs之间的欧氏距离。
一个神经网络将上述8个特征作为输入,用于推荐在16种驾驶条件下预测的EFLs或驾驶员的EFLs。输入层包含4个输入节点,并构建了2个隐藏层,每层隐藏层均设有6个节点,共12个节点。此外还有1个输出节点,用于指示either the

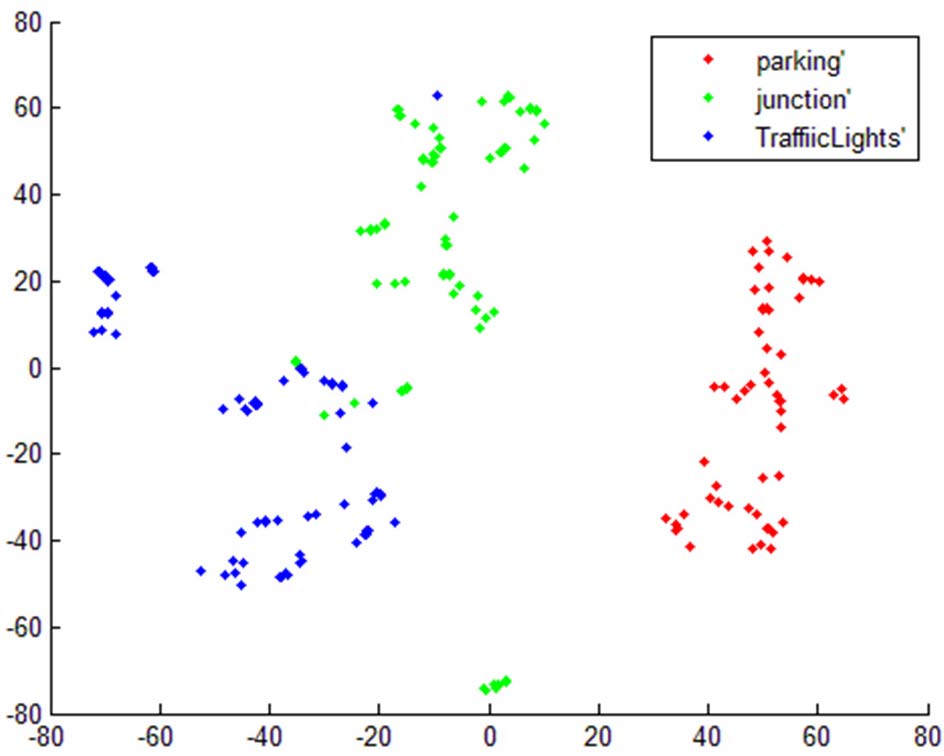
驾驶员的EFL或预测的EFL作为最优选择。整个数据集被均等地划分为10折交叉验证。训练数据集包含每个驾驶视频的前60帧,每种驾驶条件包含6个典型视频片段,因此在三种驾驶条件(停车、交叉路口和Traffic light)下共生成360帧训练数据;测试数据集包含剩余的180帧。学习率为0.02,动量常数设置为0.5,迭代次数为35000,其他参数采用默认值。训练和测试过程在TensorFlow[37]中进行,使用Sigmoid激活函数,因为在尝试其他激活函数(如Relu或Softmax)时,其性能相似,但计算效率相较于其他激活函数最低。图4展示了本研究中所用特征的t‐SNE(T分布随机邻域嵌入)降维结果[38]。如图所示,可交换模式的降维结果被清晰可视化。每个聚类代表一个典型的驾驶任务,该图表明训练和测试数据集均可被清晰分类,用于EFL推荐。
表III和表IV分别比较了所提出的基于神经网络(NN)的分类方法与基于支持向量机(SVM)的分类方法的性能。显然,基于NN的方法性能优于基于SVM的方法。通过统计驾驶员EFLs和预测的EFLs的数量,得出了精确率和召回率的表现。同时统计了所有分类错误帧中驾驶员EFLs与预测的EFLs之间的平均距离(以像素为单位),以确认错误分类不会在实际驾驶中导致决策错误。如最后一列所示,驾驶员EFLs与预测的EFLs之间的平均距离小于5个像素单位。如此小的距离对于驾驶安全而言是可接受的。该偏差不会影响各模式的最终选择,可视为视觉注视的重复出现[39]。
C. 驾驶视觉舒适度的适用性分析
关于改善驾驶视觉舒适性的目的,提出了两条指南以提升驾驶员体验。如上一节所述,1st步骤仍遵循所提出的安全驾驶策略中的驾驶员EFLs和预测的EFLs。为了进一步满足舒适驾驶的目标,针对所有驾驶条件,对驾驶员EFLs与预测的EFLs之间的选择进行了进一步更新。
为验证所提出的指南,将一个摄像头安装在一辆小型SUV(现代ix25)上,通过分类不同的驾驶任务来记录前方视野的驾驶场景。视角为±85◦,如图6所示。此外,默认车速在所有高速公路条件下设定为100公里/小时,偏差为10公里/小时;在其他所有条件下设定为50公里/小时,偏差为5公里/小时。参与者需完成10小时驾驶以进行原始数据采集,期间每次2小时驾驶测试后安排30分钟休息,即休息设置在1st小时和2nd小时之间。参与者还需通过从0到100打分来记录其驾驶视觉舒适性,其中100表示完美体验,反之亦然。测试完成后,立即要求所有参与者提供评分,并汇总所有参与者的平均评分。
对于第一个提出的指南,使用SPSS(统计产品与服务解决方案)通过皮尔逊相关系数验证其性能为|r|=0.72,表明了我们所提出指南的积极效果。对于第二个提出的指南,计算得到的皮尔逊相关系数为|r|=0.68,进一步证明了该指南的合理性。
为进一步验证所提出的推荐策略的性能,本文将我们的数据库与近期公开的数据库(即NUSEF眼动注视数据库[40]、Inria眼动追踪数据库[41]和DOVES眼动数据库[42])进行了性能比较。此外,在两种模式之间频繁切换可能会导致驾驶员视觉和精神疲劳,从而对真实驾驶条件下的驾驶视觉舒适性提升产生不利影响。交叉路口、交通信号灯和停车在实际驾驶中有时高度混合,因此推荐系统至少需要1秒的保障时间。相反,尽管自动驾驶或半自动驾驶是未来的发展趋势,但仍鼓励人类驾驶员对车辆保持控制。在恶劣天气条件下,需要适当参与以协调驾驶操作。为此,适量且适度的驾驶参与有助于提高驾驶视觉舒适性。因此,选择2秒作为驾驶员的眼动兴趣区域(EFL)的时间量,其余时间推荐用于预测的EFLs。从表V列出的指南可以看出,驾驶员的体验得到了有效改善,证明这些指南在提升驾驶视觉舒适性方面具有潜在的实用价值。

D. 讨论
根据欧盟委员会的数据,42%的致命道路交通事故(如追尾碰撞)与车辆有关,21%与行人有关,而单车事故则是由视觉或听觉分心等人为因素引起的[43]。在驾驶条件下,影响安全驾驶的人为因素范围非常广泛且复杂。本文受到视觉无意盲视的启发,这是降低驾驶安全性的常见人为因素之一。
在驾驶条件下,人为因素的范围非常广泛且复杂,涉及安全驾驶的各个方面。本文受到视觉无意盲视的启发,视觉无意盲视是一种降低驾驶安全性的常见人为因素。个体差异、驾驶行为和个人偏好是影响驾驶安全表现的其他人为因素。然而,我们认为克服驾驶员的无意视盲是实现安全驾驶的基本前提。对感知盲视在驾驶中影响的研究涉及多种情境,因此有必要引入先进的CVAM来弥补这种潜在的人为错误。本文针对16种常见驾驶条件设计了一种安全驾驶策略。基于这一优势,本研究采用了时间不可逆CVAM来模拟专家驾驶员EFLs。
最后,考虑到现实生活中的驾驶经常在高速公路和城市区域之间切换,建议将当前的EFL模型延长几秒钟。例如,当驶离高速公路时,通常需要对预测的EFL进行5秒延长期,以便驾驶员为即将到来的驾驶条件做好视觉和心理准备。此外,通过实施所提出的指南,在四个公开可用的数据集上驾驶视觉舒适性已得到有效改善。
V. 结论
总之,本文提出了一种混合EFL推荐方法以提高驾驶安全。通过从人类动态视觉中提取视觉特征,所提出推荐方法的性能证明了其在这些采集的驾驶任务中的潜在价值。此外,进一步解决了驾驶视觉舒适性问题以增强驾驶安全性。根据最常见的18种真实驾驶条件任务的结果,证实了所提出的EFL推荐通过在最新基准数据库中对驾驶舒适度评分进行85.4到92.7分(满分100分)的评定,实现了更好的驾驶体验。


















 90
90

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









