






Shell脚本:
#curl https://tianlong.5000yan.com/ -o tianlong.html
grep "href=" tianlong.html | grep html | awk -F"\"" '{ print $6 }' >> urls.txt
grep "href=" tianlong.html | grep html | awk -F">" '{ print $3 }' | awk -F"<" '{ print $1 }' >>titles.txt
#为啥要从3开始,为啥不用0,1,2
#0,1,2 被系统占了
#
#一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件:
#
#标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。
#标准输出文件(stdout):stdout 的文件描述符为1,Unix程序默认向stdout输出数据。
#标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。
#所以得从3开始
#原文链接:https://blog.youkuaiyun.com/qq_35423190/article/details/112511373
exec 3<urls.txt
exec 4<titles.txt
#-u 后面跟fd,从文件描述符中读入,该文件描述符可以是exec新开启的。
while read -u 3 url && read -u 4 title
do
echo "$title : $url"
curl "$url" -o "${title}.html"
done
下载后的文件:
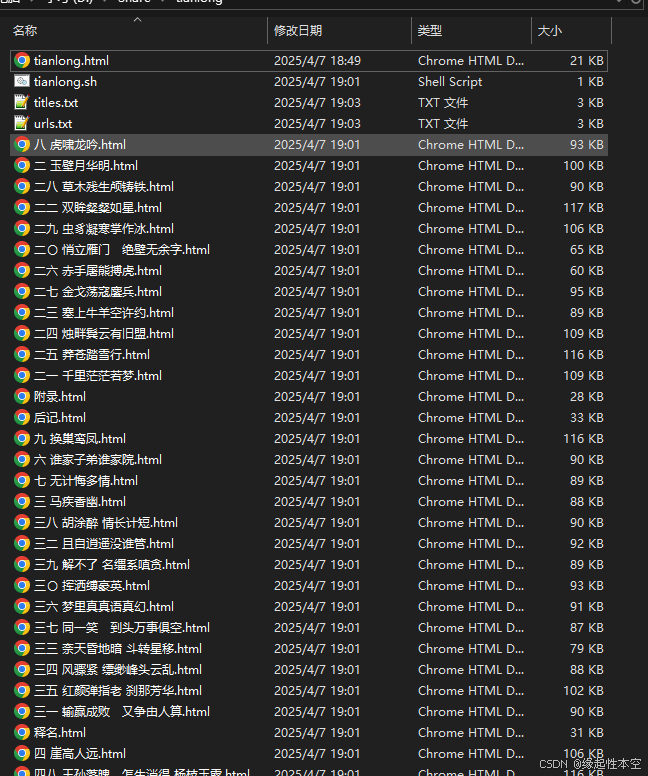
下载后的效果: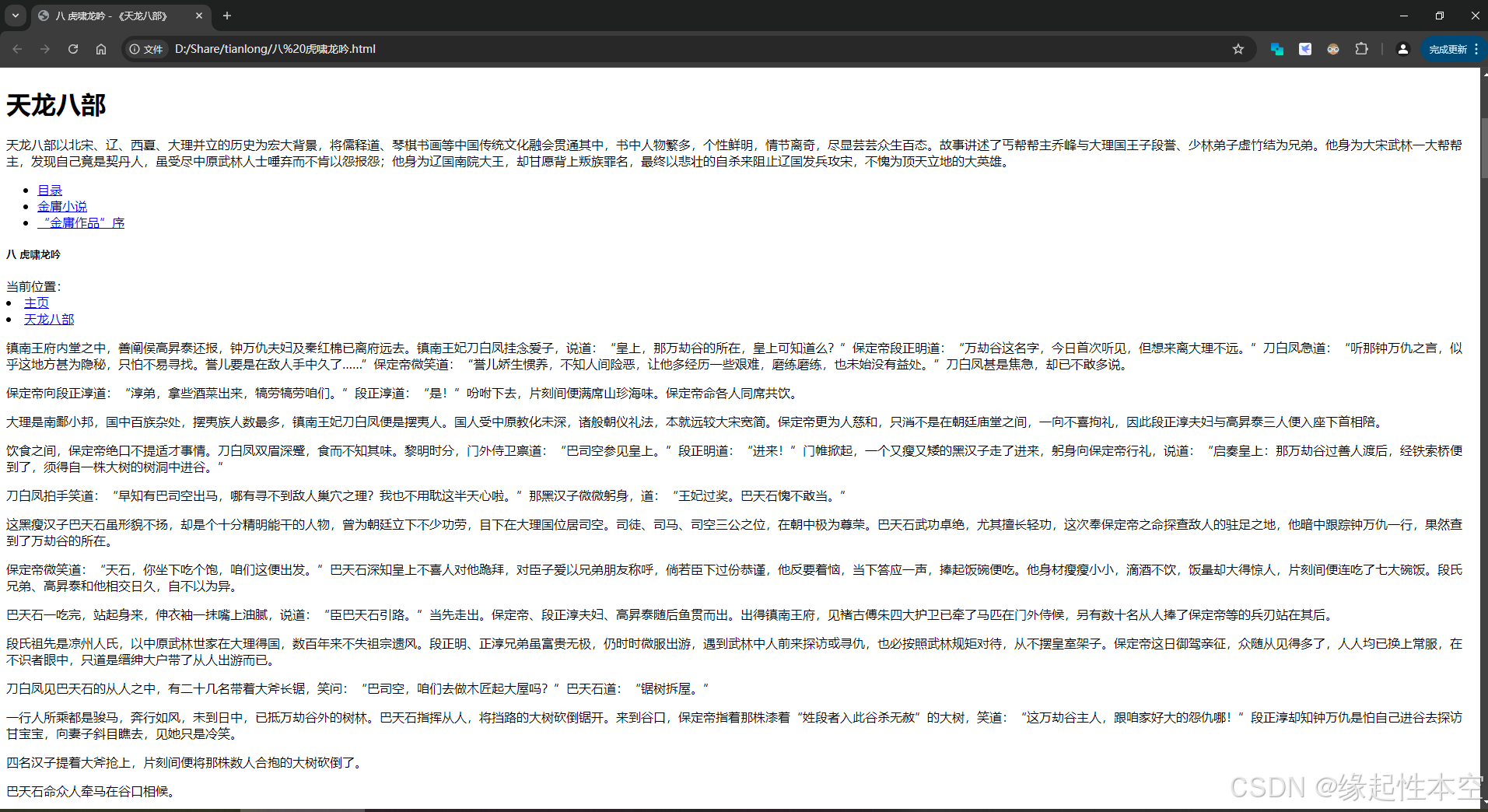


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









