






 本文探讨了CAP理论在分布式系统中的应用,详细介绍了Kafka的复制策略,包括同步与异步复制的区别。重点讲解了Kafka的Replica机制,确保数据一致性与可用性的平衡。内容涵盖ISR(in-sync Replica)的概念,以及何时Commit数据的规则。此外,还讨论了在所有Replica宕机时的Failover策略,以及可能的数据丢失和可用性问题。
本文探讨了CAP理论在分布式系统中的应用,详细介绍了Kafka的复制策略,包括同步与异步复制的区别。重点讲解了Kafka的Replica机制,确保数据一致性与可用性的平衡。内容涵盖ISR(in-sync Replica)的概念,以及何时Commit数据的规则。此外,还讨论了在所有Replica宕机时的Failover策略,以及可能的数据丢失和可用性问题。
CAP理论
- Consistency
- Availability
- Partition tolerance
CAP理论:分布时系统中,一致性,可用性,分区容性,最多值可能满足俩个,一般分错容错性要求由保障,因此很多时候在可用性一致性之间做权衡

一致性的方案
- Master-slave
- RDBMS的读写分离就是典型的Master-slave方案
- 同步复制可以保证强一致性,但是会赢下给可用性
- 异步复制可提供高可用性但会降低一致性
- WNR
- 去中心化P2P,分布式系统中。
- N代表副本数目,W代表每次操作要保证最少写成功的副本书,R代表每次至少读取副本数
- W+R > N,可保证每次读取的数据至少由一个副本具有最新的更新
- 多个写操作的顺序难以保证,可能导致多个副本之间的写的顺序不一致。
- Paxos及其变种
- zookeeper的Zab(Zookeeper 原子广播),RAFT等
Kafka Replica
- 当某个Topic的replication-factor为N且N大于1时,每个Partition都会有N个副本(replica)
- Replica的个数小于等于Broker数,即对每个Partition而言每个Broker上只会有一个Replica,因此可用Broker ID表示Replica
- 所有Partition的所有Replica默认情况都会均匀分布到所有Broker上
Data Replication要解决的问题
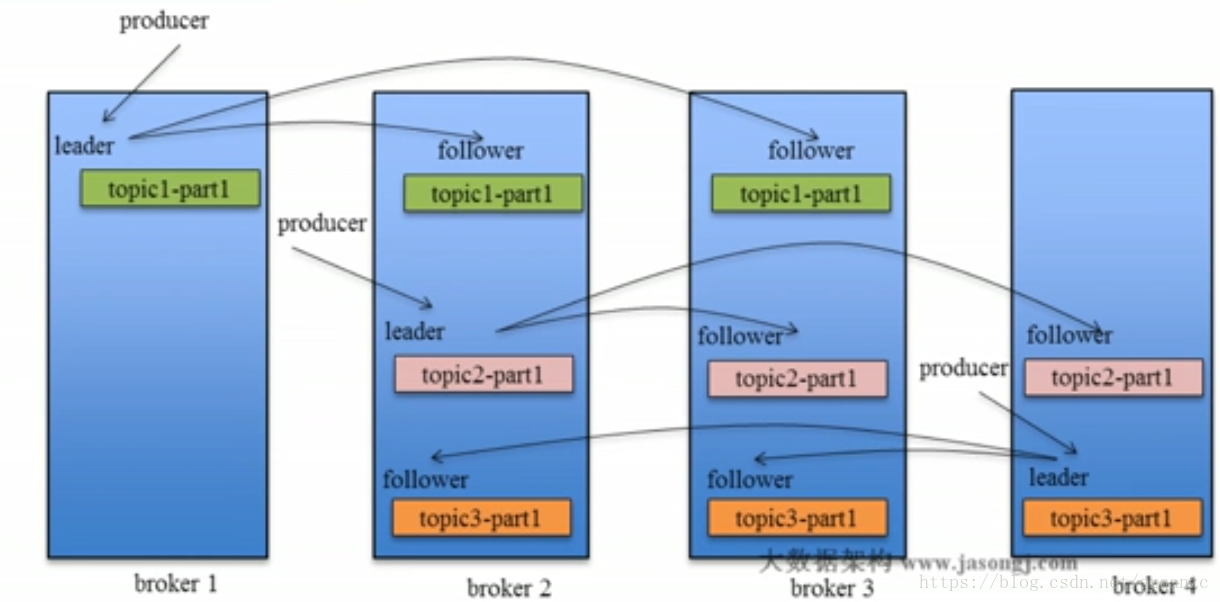
读写都在leader 上进行
什么时候Commit
- ISR
- Leader会维护一个与其保持基本同步的Replica列表,该列表称之为(in-sync Replica)
- 如果一个Follower比Leader落后太多,或者超过一定时间没有发起复制请求,则Leader将其从ISR中移除
- 当ISR中所有Replicat都向Leader发送ACK,Leader即Commit
- Commit策略
- Server 配置
replica.lag.time.max.ms=1000
replica.lag.max.messages=4000 - Topic配置
min.insync.replicas=1 - Producer配置
request.required.acks=0
如何处理Replica全部宕机
- 等待ISR中任一Replica回复,并选它为Leader,并选它为Leader
- 等待时间长,降低可用性
- 或ISR中所有的Replica都无法回复或者数据丢失,则该Partition将永不可用
- 选择第一个恢复的Replica为新的Leader,无论它是否在ISR中
- 并未包含所有已被之前Leader Commit过的消息,因此会导致数据丢失
- 可用性比较高

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









