






 本文详细介绍了Java中几种常见集合类如HashMap、HashSet等的初始容量、扩容方式及最大容量。并通过实例说明了这些集合如何在达到特定条件时进行扩容,并解释了为何最大容量会减去8的原因。
本文详细介绍了Java中几种常见集合类如HashMap、HashSet等的初始容量、扩容方式及最大容量。并通过实例说明了这些集合如何在达到特定条件时进行扩容,并解释了为何最大容量会减去8的原因。
| 类别 | 初始容量 | 扩容方式 | 最大容量 |
|---|---|---|---|
| HashMap | 16 | 达到0.75就乘2 | 2的30次方 |
| HashSet | 16 | 达到0.75就乘2 | 2的30次方 |
| Hashtable | 11 | 达到0.75就乘2+1 | Integer.MAX_VALUE-8 |
| ArrayList | 10 | 满了就乘1.5 | Integer.MAX_VALUE-8 |
| StringBuffer | 16 | 满了就乘2+2 | |
| StringBuilder | 16 | 满了就乘2+2 |
以上扩容机制在JAVA源码中均可以找到,以HashMap为例

这里
DEFAULT_INITIAL_CAPACITY 代表初始容量
MAXIMUM_CAPACITY 代表最大容量
DEFAULT_LOAD_FACTOR 代表装填因子表示达到容量的0.75就扩容
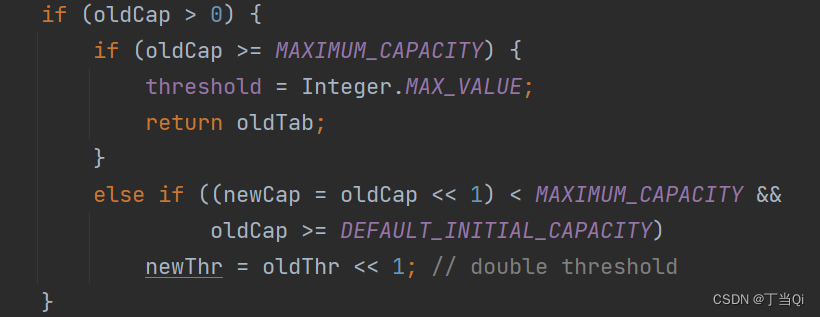
扩容代码 ,新容量变为旧容量的2倍;新阈值变为旧阈值的两倍
(容量:capacity 阈值:threshold)
为什么 -8
因为自己作为数组,除了存储数据本身以外、还需要32 bytes的大小来存储对象头信息。Java中的每个对象都包含了对象头,HotPot虚拟机中对象头的大小不会超过32bytes,所以最大容量减8不会溢出
(1 int = 4 bytes)
小伙伴们,不明白的地方一定要去查源码哦!这样会理解更加深刻!!!

















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









