



再继承Reducer,并重写reduce函数
package org.example.flow;
import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//1继承Reducer //2重写reduce函数 public class FlowReducer extends Reducer<Text,FlowBean,Text,Text> { @Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
//1遍历集合,取出每一个元素,计算上行流量和下行流量的总汇
long upFlowSum = 0L;
long downFlowSum = 0L;
for (FlowBean flowBean : values) {
upFlowSum += flowBean.getUpFlow();
downFlowSum += flowBean.getDownFlow(); }
//2计算总的汇总
long sumFlow = upFlowSum + downFlowSum;
String flowDesc =String.format("总的上行流量是:%d 总的下行流量:%d 总流量是:%d",upFlowSum,downFlowSum,sumFlow);
context.write(key, new Text(flowDesc)); } }
再去提交job和进行关联mapper和reducer进行汇总设置输出类型路径
package org.example.flow;
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
//提交job的类,一共做7件事 public class FlowDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
//1获取配置,得到job对象
Configuration conf=new Configuration();
Job job= Job.getInstance(conf);
//2设置job包路径
job.setJarByClass(FlowDriver.class);
//3关联Mapper和Reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
//4设置Mapper输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
//5设置reducer输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//6设置输入和输出路径
FileInputFormat.setInputPaths(job,new Path("data"));
FileOutputFormat.setOutputPath(job,new Path("output"));//
//7提交job根据返回值设置程序退出code
boolean result=job.waitForCompletion(true);
System.exit(result?0:1);
}
}
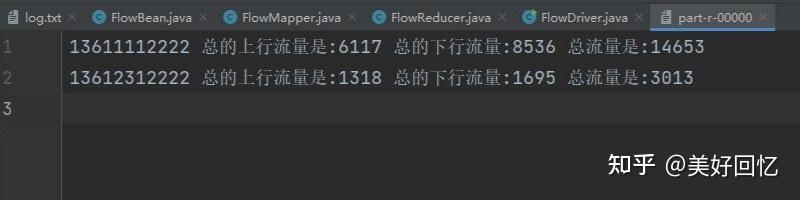
进行运行生成一个output目录 part-r-00000中则会生成结果

















 1427
1427

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









