






1.表间关系
项目开发中,因为业务之间相互关联,所以实体与实体之间存在联系,故而表跟表之间也存在着各种联系
我们把这种能够表示表间关系的数据库称为关系型数据库(RDBMS),表关系分为三种:一对多、多对多、一对一;
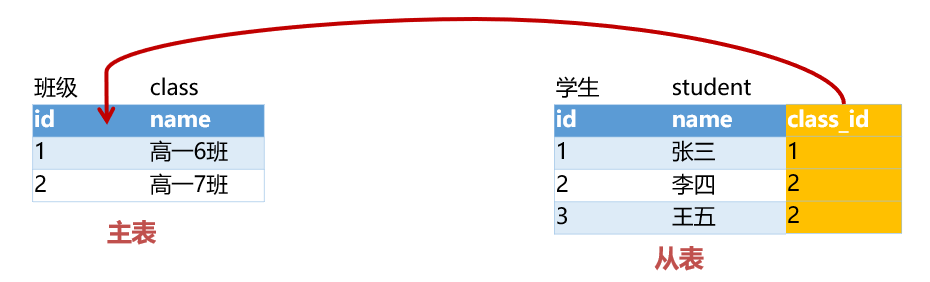
1.1 一对多
应用场景:班级和学生、部门和员工
建表原则:
- 在表设计时,我们把一的一方称为主表,多的一方称为从表
- 在从表中添加一列指向主表的主键列,新加列名字一般是(主表名_主键名)
- 将新建的这一列称为外键列,它的作用是为了建立当前表和其他表的关联关系,一张表中,允许有多个外键列
1.2 多对多
应用场景:学生和课程
建表原则:
- 新建一张中间表,作为两张主表的从表存在
- 在中间表中创建两个外键,分别指向两张主表的主键
- 多对多一个关系本质上是由两个一对多拼接而成

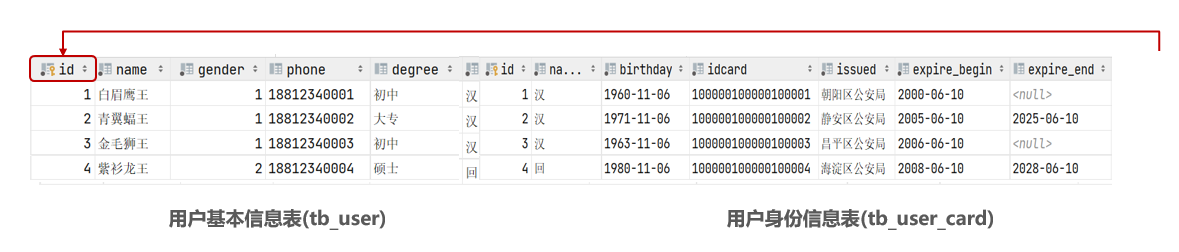
1.3 一对一
应用场景:用户与身份证信息的关系,多用于单表拆分,提高效率
用户 与 身份证信息 的关系实现: 在任意一方加入外键,关联另外一方的主键,并且设置外键为唯一的(UNIQUE)

2.多表查询
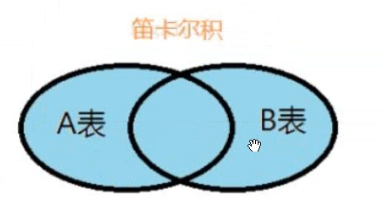
2.1 交叉查询
解释: 使用左表中的每一条数据分别去连接右表中的每一条数据, 将所有的连接结果都展示出来
语法: select 字段列表 from 左表,右表
-- 1. 查询员工表和部门表中所有信息(交叉连接) select * from emp,dept;
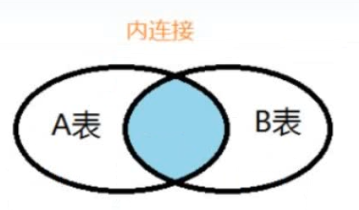
2.2 内连接
解释: 使用左表中的每一条数据分别去连接右表中的每一条数据, 仅仅显示出匹配成功的那部分
语法: 隐式内连接: select 字段列表 from 左表 , 右表 where 条件 ...
显示内连接: select 字段列表 from 左表 [ inner ] join 右表 on 连接条件 ...
-- 2. 查询员工和部门信息, 仅显示两表中全部符合的数据(内连接) -- 隐式内连接: select 字段列表 from 左表 , 右表 where 条件 ... select * from emp e ,dept d where e.dept_id = d.id; -- 显示内连接select 字段列表 from 左表 [ inner ] join 右表 on 连接条件 ... select * from emp e inner join dept d on e.dept_id = d.id;
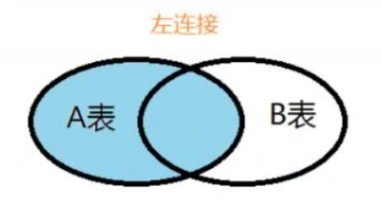
2.3 左外连接
解释: 首先要显示出左表的全部,然后使用连接条件匹配右表,能匹配中的就显示,匹配不中的显示为null
语法: select 字段列表 from 左表 left [ outer ] join 右表 on 连接条件
-- 3. 查询员工和部门信息, 显示所有员工, 员工部门不存在的使用null补齐(左外连接) select * from emp e left join dept d on e.dept_id = d.id;
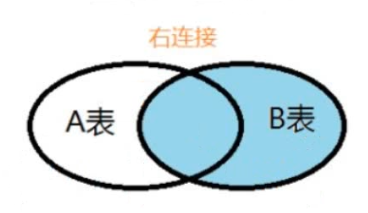
2.4 右外连接
解释: 首先要显示出右表的全部,然后使用连接条件匹配左表,能匹配中的就显示,匹配不中的显示为null
语法: select 字段列表 from 左表 right [ outer ] join 右表 on 连接条件
-- 4. 查询员工和部门信息, 显示所有部门, 部门中没有员工的使用null补齐(右外连接) select * from emp e right join dept d on e.dept_id = d.id;
2.5 子查询
- 介绍:SQL语句中嵌套select语句,称为嵌套查询,又称子查询。
- 形式:select * from t1 where column1 = ( select column1 from t2 … );
- 子查询外部的语句可以是insert / update / delete / select 的任何一个,最常见的是 select。
标量子查询:子查询返回的结果为单个值
- 子查询返回的结果是单个值(数字、字符串、日期等),最简单的形式
- 常用的操作符:= > < 等 select 字段列表 from 表 where 字段名 = (子查询)
-- 1: 查询工资小于平均工资的员工有哪些?(子查询结果为一个值 标量子查询) -- 1.1 查询平均工资 select avg(salary) from emp; -- 1.2查询工资小于平均工资的员工有哪些 select * from emp where salary<(select avg(salary) from emp);列子查询:子查询返回的结果为一列
- 子查询返回的结果是一列(可以是多行)
- 常用的操作符:in 、not in等 select 字段列表 from 表 where 字段名 in (子查询)
-- 2: 查询工资大于5000的员工,所在部门的名字 (子查询结果为多个值 列子查询) -- 2.1查询工资大于5000的员工 select dept_id from emp where salary>5000; -- 2.2查询工资大于5000的员工,所在部门的名字 select * from dept where id in(select dept_id from emp where salary>5000);表子查询:子查询返回的结果为一张表
- 子查询返回的结果是多行多列,常作为临时表
- 常用的操作符:as 临时表 select 字段列表 from (子查询) as 临时表 join 表 on 条件
-- 3: 查询出2011年以后入职的员工信息,包括部门信息 (子查询结果为一张表 表子查询) -- 3.1查询出2011年以后入职的员工信息 select * from emp where join_date >'2011.1.1'; -- 3.2查询出2011年以后入职的员工信息,包括部门信息 select * from (select * from emp where join_date >'2011.1.1') e left join dept on e.dept_id =dept.id;
3.多表查询一般步骤
-- * 多表查询的一般步骤 * -- 1. 确定使用哪几张表 -- 2. 确定表之间的连接点,然后连接查询 -- 3. 确定业务条件 -- 4. 确定显示字段 -- 1. 查询所有价格在 10元(含)到50元(含)之间 且 状态为'起售'的菜品名称、价格 及其 菜品的分类名称 -- (即使菜品没有分类, 也需要将菜品查询出来). -- 1.1 两张表dish category,连接条件 d.category_id = c.id select * from dish d left join category c on d.category_id = c.id; -- 1.2 确定业务条件 10<price<50 and status = 1, select * from dish d left join category c on d.category_id = c.id where price between 10 and 50 and d.status =1; -- 1.3确定显示字段菜品名称、价格 及其 菜品的分类名称 select d.name,d.price,c.name from dish d left join category c on d.category_id = c.id where price between 10 and 50 and d.status =1; -- 2. 查询出 "商务套餐A" 中包含了哪些菜品 (展示出套餐名称、价格, 包含的菜品名称、价格、份数) -- 2.1两张表dish setmeal ,中间表 select * from setmeal s inner join setmeal_dish sd inner join dish d; -- 2.2连接条件 select * from setmeal s inner join setmeal_dish sd inner join dish d on s.id = sd.setmeal_id and d.id = sd.dish_id; -- 2.3业务条件 查询出 "商务套餐A" 中包含了哪些菜品 (展示出套餐名称、价格, 包含的菜品名称、价格、份数) select s.name,s.price,d.name,d.price,sd.copies from setmeal s inner join setmeal_dish sd inner join dish d on s.id = sd.setmeal_id and d.id = sd.dish_id where s.name = '商务套餐A'; -- 5. 查询每个分类下最贵的菜品, 展示出分类的名称、最贵的菜品的价格 -- 5.1 三张表 dish category select * from dish d inner join category c; -- 5.2 连接条件 select * from dish d inner join category c on d.category_id = c.id; -- 5.3业务条件,***对谁分组就查谁*** select c.name,max(d.price) from dish d inner join category c on d.category_id = c.id group by c.name having max(d.price); -- 6. 查询各个分类下状态为'起售' , 并且该分类下菜品总数量大于等于3的分类名称 -- 6.1 两张表category dish select * from category c inner join dish d; -- 6.2 连接条件 select * from category c inner join dish d on d.category_id = c.id; -- 6.3 业务条件 select c.name,c.status,count(*) num from category c inner join dish d on d.category_id = c.id where c.status = 1 group by c.name having num >= 3;
4.MySQL事务
1.1 什么是事务
事务 就是把所有的SQL语句作为一个整体,一起向系统提交或撤销操作请求,即这些操作 要么同时成功,要么同时失败。
1.2 事务怎么用
默认MySQL的事务是自动提交的,也就是说当执行一条DML语句,MySQL会立即隐式的提交事务。所以需要手动开启提交事务。
- 开启事务:start transaction; 或 begin ;
- 提交事务:commit;
- 回滚事务:rollback;
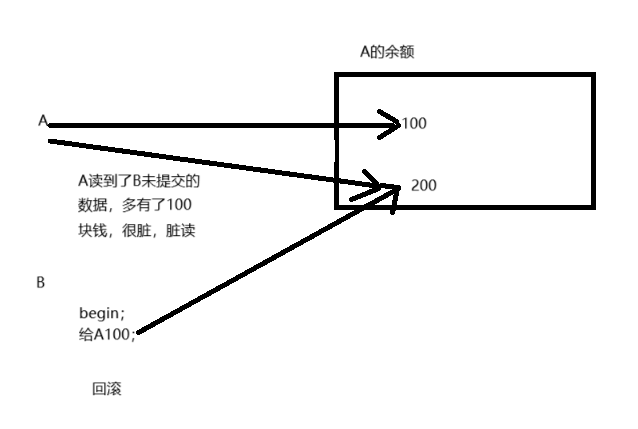
-- 创建账户表,并且添加两条测试数据 CREATE TABLE account ( id INT PRIMARY KEY AUTO_INCREMENT, NAME VARCHAR(32), money DOUBLE ); INSERT INTO account (NAME, money) VALUES ('A', 1000), ('B', 1000); -- 事务就是把一些SQL语句看成一个整体执行,同时成功或者同时失败 =============================执行成功=========================== begin ; -- 开启手动控制事务 -- 将A账户减去10元 update account set money=money-10 where name = 'A'; -- 只是在内存里记录,并未操作数据库 -- 将B账户加上10元 update account set money=money+10 where name = 'B'; commit; -- 提交事务 --进行数据库修改 =============================执行失败=========================== begin ; -- 开启手动控制事务 -- 将A账户减去10元 update account set money=money-10 where name = 'A'; -- 执行成功 -- 机器故障 -- 将B账户加上10元 update account set money=money+10 where name = 'B'; -- 遇到问题,执行失败了 rollback; -- 回滚事务1.3 事务的三个问题:
- 四大特性(ACID)
- 原子性:atomicity 事务是不可分割的最小单元,要么全部成功,要么全部失败
- 一致性:consistency 一个事务执行前后,数据库的状态是一致的
- 隔离性:isolation 当多个事务同时执行的时候,互相是不会产生影响的
- 持久性:durability 事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
- 隔离性产生的问题?
- 脏读:一个事务读取到了另外一个事务没有提交的数据,脏读
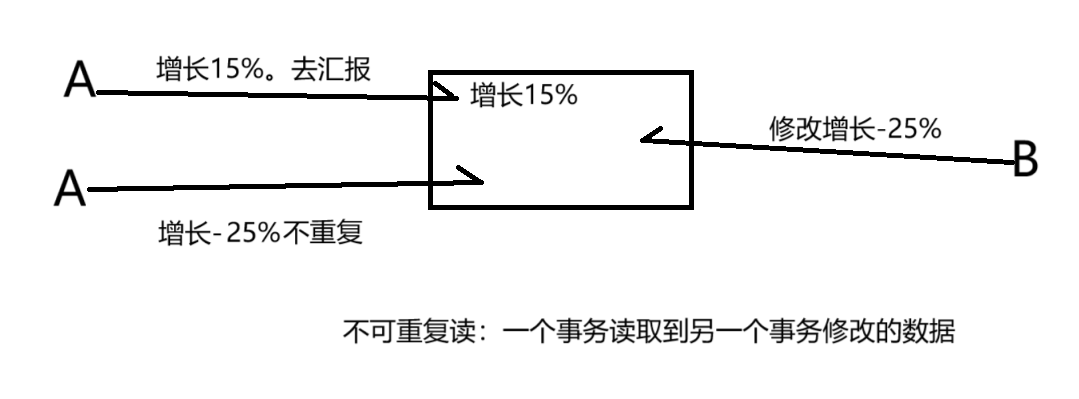
- 不可重复读:一个事务读取到了另外一个事务修改的数据(修改)
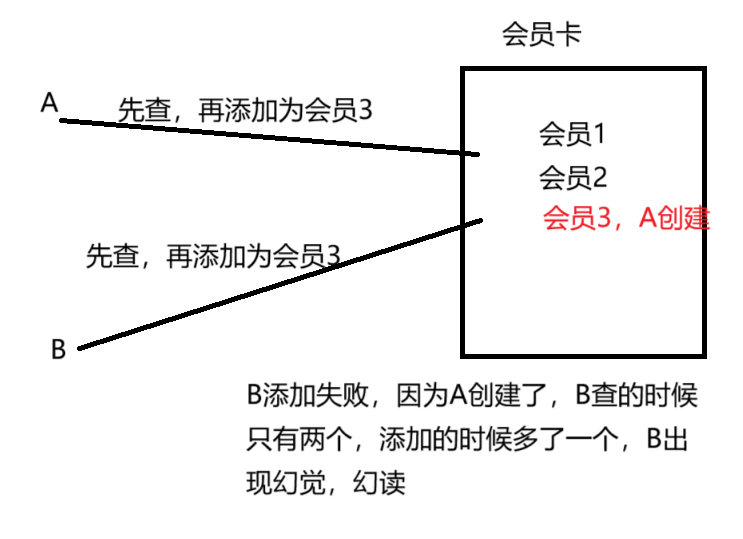
- 幻读(虚读):一个事务读取到了另外一个事务新增的数据(新增)
- 怎么去解决这些问题?
级别 名字 隔离级别 脏读 不可重复读 幻读 数据库默认隔离级别 1 读未提交 read uncommitted 是 是 是 2 读已提交 read committed 否 是 是 Oracle 3 可重复读 repeatable read 否 否 是 MySQL 4 串行化 serializable 否 否 否 安全:4>3>2>1
性能:1>2>3>4
综合:2 or 3 所以Oracle默认读已提交,MySQL默认可重复读


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









