







 本文介绍了Hadoop生态系统的多个核心组件,包括MapReduce、HDFS、HBase、Hive、Pig、Zookeeper和Mahout。详细阐述了各组件的功能、来源及应用场景,如HDFS的分布式文件存储能力,Hive的SQL-like数据查询,以及Zookeeper在协调大型分布式系统中的作用。
本文介绍了Hadoop生态系统的多个核心组件,包括MapReduce、HDFS、HBase、Hive、Pig、Zookeeper和Mahout。详细阐述了各组件的功能、来源及应用场景,如HDFS的分布式文件存储能力,Hive的SQL-like数据查询,以及Zookeeper在协调大型分布式系统中的作用。
Hadoop生态系统组件主要包括:MapReduce|HDFS|HBase|Hive|Pig|Zookeeper|Mahout
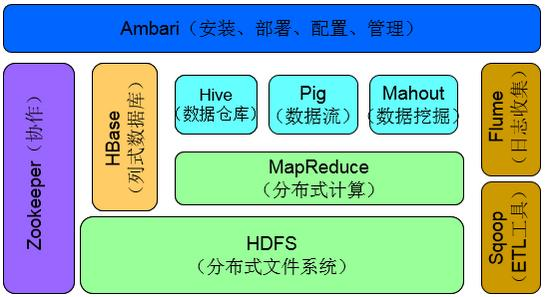
MapReduce
主要由Google Reduce而来,它简化了大型数据的处理,是一个并行的,分布式处理的编程模型。
hadoop2.0它是基于YARN框架构建的。YARN的全称是Yet-Another-Resource-Negotiator。Yarn可以运用在S3|Spark等上。
HDFS
它是由Google File System而来,全称是Hadoop Distributed File System,是Hadoop的分布式文件系统,有许多机器组成的,可以存储大型数据文件。
它是由NameNode和DataNode组成,NameNode可以配置成HA(高可用),避免单点故障。一般用Zookeeper来处理。两个NameNode是同步的。
Hive
它是Hadoop的数据仓库(DW),它可以用类似SQL的语言HSQL来操作数据,很是方便,主要用来联机分析处理OLAP(On-Line Analytical Processing),进行数据汇总|查询|分析。
HBase
它是由Google BigTable而来。是Hadoop的数据库。HBase底层还是利用的Hadoop的HDFS作为文件存储系统,可以利用Hadoop的MR来处理HBase的数据,它也通常用Zookeeper来做协同服务。
Zookeeper
它是一个针对大型分布式系统的可靠协调系统,在Hadoop|HBase|Strom等都有用到,它的目的就是封装好复杂易出错的关键服务,提供给用户一个简单|可靠|高效|稳定的系统。提供配置维护|分布式同步|名字服务等功能,Zookeeper主要是通过lead选举来维护HA或同步操作等
Pig
它提供一个引擎在Hadoop并行执行数据流。它包含了一般的数据操作如join|sort|filter等,它也是使用MR来处理数据。
Mahout
它是机器学习库。提供一些可扩展的机器学习领域经典算法的实现,目的是帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐算法等。

















 335
335

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









