







文章目录
主要讲解在虚拟机中安装Hadoop的方法
在本示例中,使用VBOX模拟3台Centos系统,分别是1台master和2台slaver。IP分别是:
- 192.168.56.3
- 192.168.56.4
- 192.168.56.5
每台均安装下面章节安装。
1 VBOX安装CentOS7
1.1 安装VBOX软件
(略)
1.2 下载CentOS7镜像文件
从阿里镜像网站下载镜像文件
1.3 初始化VBOX虚拟盘
(略)
1.4 CentOS7网络配置
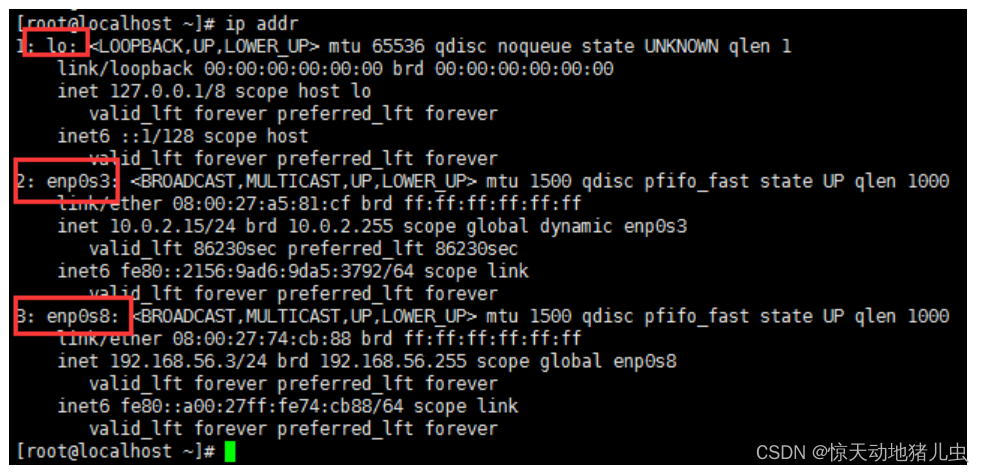
ip addr检查网卡信息,显示有两个网卡eno0s3和enp0s8,如下图:
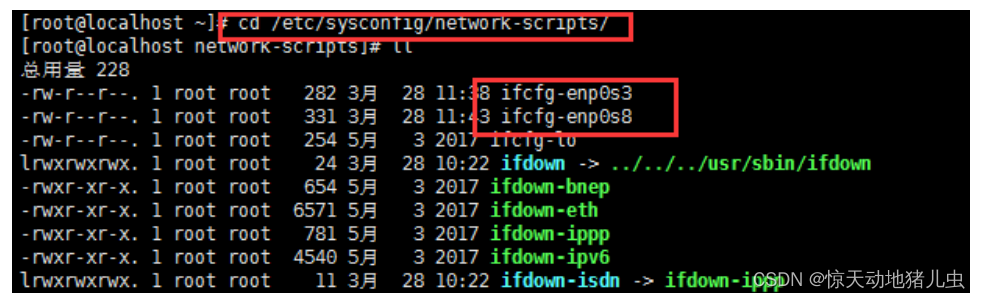
cd /etc/sysconfig/network-scripts/修改对应ifcfg-enp0s3和ifcfg-enp0s8文件,如下图:
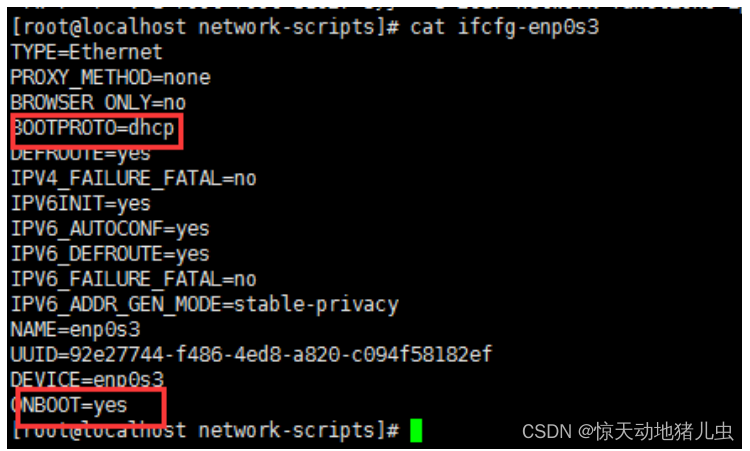
- enp0s3对应VBOX网卡1 NET方式取动态获取IP,如下图:
- enp0s8对应VBOX网卡2 仅主机(Host-only)网络,配置静态IP,与宿主机windows中VBOX网卡对应,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2YPx5Q2K-1669260284248)(https://note.youdao.com/yws/res/42776/WEBRESOURCE81eefe33d76e53be9d234618c1ee55bf)]](https://i-blog.csdnimg.cn/blog_migrate/3bd7f33afd1d01d02479b48036b91ef1.png)
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-iW7Yo9ux-1669260284248)(https://note.youdao.com/yws/res/42778/WEBRESOURCEeba4c2021e38431f5600979807043701)]](https://i-blog.csdnimg.cn/blog_migrate/ee79b7d987210fa79fcdcfae89dfed96.png)
service network restart重启网络后,在xshell中配置静态IP即可访问,如下图:
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-plJrGkvI-1669260284249)(https://note.youdao.com/yws/res/42781/WEBRESOURCEbbda0207fd7fbcfcd59c4e412233ff31)]](https://i-blog.csdnimg.cn/blog_migrate/e509ea818f6d729d76b8bbe3a69cec28.png)
1.5 CentOS7 yum源配置
访问阿里镜像网站,点击centos右侧帮助按钮
# 备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
# 下载新的CentOS-Base.repo 到/etc/yum.repos.d/
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
# 运行yum makecache生成缓存
安装一些基础工具
yum install -y lrzsz
1.6 CentOS7 一般配置
1.6.1关闭防火墙
- CentOS7之前(不含CentOS7)
| 命令 | 备注 |
|---|---|
| service iptable status | 查看防火墙状态 |
| service iptables stop | 临时关闭防火墙 |
| chkconfig iptables off | 永久关闭防火墙 |
- CentOS7之后(含CentOS7)
| 命令 | 备注 |
|---|---|
| firewall-cmd --state | 查看防火墙状态(关闭后显示notrunning,开启后显示running) |
| systemctl list-unit-files|grep firewalld.service 或 systemctl status firewalld.service | 从centos7开始使用systemctl来管理服务和程序,包括了service和chkconfig |
| systemctl stop firewalld.service | 停止firewall |
| systemctl disable firewalld.service | 禁止firewall开机启动 |
| systemctl start firewalld.service | 启动一个服务 |
| systemctl stop firewalld.service | 关闭一个服务 |
| systemctl restart firewalld.service | 重启一个服务 |
| systemctl status firewalld.service | 显示一个服务的状态 |
| systemctl enable firewalld.service | 在开机时启用一个服务 |
| systemctl disable firewalld.service | 在开机时禁用一个服务 |
| systemctl is-enabled firewalld.service | 查看服务是否开机启动 |
| systemctl list-unit-files|grep enabled | 查看已启动的服务列表 |
1.6.2 修改hostname
| 临时修改 hostname | |
|---|---|
| hostname bigdata01 | 这种修改方式,系统重启后就会失效 |
| 永久修改 hostname | |
|---|---|
| 想永久修改,应该修改配置文件 | 写入以下内容: |
| vi /etc/hosts | 修改 127.0.0.1这行中的 localhost.localdomain为 bigdata01 |
| vi /etc/hostname | 删除文件中的所有文字,在第一行添加slave3 |
| 重启并验证 | #>reboot -f |
1.6.3 配置DNS绑定
将所有主机的vi /etc/hosts都配置如下:
192.168.56.3 bigdata01
192.168.56.4 bigdata02
192.168.56.5 bigdata03
1.6.4 关闭selinux
vi /etc/sysconfig/selinux
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uOjpP5Dg-1669260284249)(https://note.youdao.com/yws/res/42810/WEBRESOURCE610af9cc5f8ae9d71570c726a419c9b9)]](https://i-blog.csdnimg.cn/blog_migrate/62f9536e9b970e6ae67cfcf418af1f12.png)
修改为
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WcuCnxZS-1669260284249)(https://note.youdao.com/yws/res/42812/WEBRESOURCE15934cb1d8c8d97654616a97369f6ecd)]](https://i-blog.csdnimg.cn/blog_migrate/06790cd0d9ed950827ca4ef7dd96efdc.png)
2 JDK等基础安装配置
2.1 安装JDK前检查
检查是否已经安装了JDK
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-4KayjXws-1669260284250)(https://note.youdao.com/yws/res/42817/WEBRESOURCE3b824036dc012be7a6bdf29ddf2d5a1f)]](https://i-blog.csdnimg.cn/blog_migrate/1ed3d2ebdf3be74ea2fda001d7026495.png)
注意: Hadoop机器上的JDK, 最好是Oracle的JavaJDK, 不然会有一些问题,比如可能没有 JPS 命令。如果安装了其他版本的JDK, 卸载掉。
删除自带 java
[root@server media]# rpm -qa |grep java
tzdata-java-2014g-1.el6.noarch
java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el6_5.x86_64
java-1.6.0-openjdk-1.6.0.0-11.1.13.4.el6.x86_64
[root@server media]# rpm -e java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el6_5.x86_64
[root@server media]# rpm -e java-1.6.0-openjdk-1.6.0.0-11.1.13.4.el6.x86_64 --nodeps
[root@server media]# rpm -qa|grep java
tzdata-java-2014g-1.el6.noarch
2.2 安装tar格式JDK
上传tar.gz包只安装目录
# 将jdk-7u67-linux-x64.tar.gz解压到/opt/modules目录下
[root@bigdata-senior01 /]# tar -zxvf jdk-7u67-linux-x64.tar.gz -C /opt/modules
添加环境变量
# 设置JDK的环境变量JAVA_HOME。需要修改配置文件/etc/profile,追加
export JAVA_HOME="/opt/modules/jdk1.7.0_67"
export PATH=$JAVA_HOME/bin:$PATH
# 修改完毕后,执行 source /etc/profile
2.3 安装rpm格式JDK
rpm -ivh jdk-8u261-linux-x64.rpm
添加环境变量
vi /etc/profile
export JAVA\_HOME="/usr/java/jdk1.7.0\_80"
export PATH=`$JAVA_HOME/bin:$`PATH
# 修改完毕后,执行 source /etc/profile
2.4 配置SSH互信
- 首先是安装SSH(安全外壳协议),这里推荐安装OpenSSH
- 安装expect,使用expect建立主机间的互信
yum -y install expect
[root@bigdata01 ~]# which expect
/usr/bin/expect
- 编写节点文件hadoop_hosts.txt如下:
bigdata01
bigdata02
bigdata03
# 这里使用hostname,是因为之前的步骤在主机已经配置了hosts文件。也可以直接使用IP
- 编写并上传sshkey.sh,执行
# cat sshkey.sh
#!/bin/bash
# 这里替换为真实密码
password=mage
#2.keys
ssh-keygen -t rsa -P "" -f /root/.ssh/id_rsa &> /dev/null
#3.install expect
rpm -q expect &> /dev/null || yum install expect -y &> /dev/null
#4.send key
while read ip;do
expect << EOF
set timeout 20
spawn ssh-copy-id -i /root/.ssh/id_rsa.pub root@$ip
expect {
"yes/no" { send "yes\n";exp_continue }
"password" { send "$password\n" }
}
expect eof
EOF
done < /tmp/hadoop_hosts.txt
- 在每台机器上测试互信
(略)
2.5 配置NTP时钟同步
bigdata01 ntpd服务器,用于与外部公共ntpd同步标准时间
bigdata02 ntpd客户端,用于与ntpd同步时间
bigdata03 ntpd客户端,用于与ntpd同步时间
- 使用rpm检查ntp包是否安装
rpm -q ntp
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qpUNL6uV-1669260284250)(https://note.youdao.com/yws/res/43619/WEBRESOURCE24657ed075c7af7d93b5663cb2a4341e)]](https://i-blog.csdnimg.cn/blog_migrate/a556d0d4800eeca60b93594c8d3a268f.png)
- 使用yum进行安装,并设置系统开机自动启动并启动服务
yum -y install ntp
systemctl enable ntpd
systemctl start ntpd
- 配置前先使用命令:
ntpdate -u cn.pool.ntp.org,同步服务器
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SVsFhRMn-1669260284250)(https://note.youdao.com/yws/res/43622/WEBRESOURCE63b960aab8a9b169f602969cf30bf93c)]](https://i-blog.csdnimg.cn/blog_migrate/fff1fb8c64fe14316d35d621551c0dd3.png)
- 修改
vi /etc/ntp.conf文件,红色字体是修改的内容
# For more information about this file, see the man pages
# ntp.conf(5), ntp_acc(5), ntp_auth(5), ntp_clock(5), ntp_misc(5), ntp_mon(5).
driftfile /var/lib/ntp/drift
# Permit time synchronization with our time source, but do not
# permit the source to query or modify the service on this system.
restrict default nomodify notrap nopeer noquery
# Permit all access over the loopback interface. This could
# be tightened as well, but to do so would effect some of
# the administrative functions.
restrict 127.0.0.1
restrict ::1
# Hosts on local network are less restricted.
#restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
restrict 192.168.56.0 mask 255.255.255.0 nomodify notrap
#允许内网其他机器同步时间,如果不添加该约束默认允许所有IP访问本机同步服务
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
#server 0.centos.pool.ntp.org iburst
#server 101.201.72.121 # 中国国家授时中心
#server 133.100.11.8 #日本[福冈大学]
#server 3.cn.pool.ntp.org
#server 1.asia.pool.ntp.org
#server 3.asia.pool.ntp.org
#配置和上游标准时间同步,时间服务器的域名,如不需要连接互联网,就将他们注释掉
#broadcast 192.168.1.255 autokey # broadcast server
#broadcastclient # broadcast client
#broadcast 224.0.1.1 autokey # multicast server
#multicastclient 224.0.1.1 # multicast client
#manycastserver 239.255.254.254 # manycast server
#manycastclient 239.255.254.254 autokey # manycast client
#配置允许上游时间服务器主动修改本机(内网ntp Server)的时间
#restrict 101.201.72.121 nomodify notrap noquery
#restrict 133.100.11.8 nomodify notrap noquery
#restrict 3.cn.pool.ntp.org nomodify notrap noquery
#restrict 1.asia.pool.ntp.org nomodify notrap noquery
#restrict 3.asia.pool.ntp.org nomodify notrap noquery
#确保localhost有足够权限,使用没有任何限制关键词的语法。
#外部时间服务器不可用时,以本地时间作为时间服务。
#注意:这里不能改,必须使用127.127.1.0,否则会导致无法!
#在ntp客户端运行ntpdate serverIP,出现no server suitable for synchronization found的错误。
#在ntp客户端用ntpdate –d serverIP查看,发现有“Server dropped: strata too high”的错误,并且显示“stratum 16”。而正常情况下stratum这个值得范围是“0~15”。
#这是因为NTP server还没有和其自身或者它的server同步上。
#以下的定义是让NTP Server和其自身保持同步,如果在ntp.conf中定义的server都不可用时,将使用local时间作为ntp服务提供给ntp客户端。
server 127.127.1.0 # local clock
fudge 127.127.1.0 stratum 8
# Enable public key cryptography.
#crypto
includefile /etc/ntp/crypto/pw
# Key file containing the keys and key identifiers used when operating
# with symmetric key cryptography.
keys /etc/ntp/keys
# Specify the key identifiers which are trusted.
#trustedkey 4 8 42
# Specify the key identifier to use with the ntpdc utility.
#requestkey 8
# Specify the key identifier to use with the ntpq utility.
#controlkey 8
# Enable writing of statistics records.
#statistics clockstats cryptostats loopstats peerstats
# Disable the monitoring facility to prevent amplification attacks using ntpdc
# monlist command when default restrict does not include the noquery flag. See
# CVE-2013-5211 for more details.
# Note: Monitoring will not be disabled with the limited restriction flag.
disable monitor
- 重启ntp服务
systemctl restart ntpd
- 启动后,查看同步情况
ntpq -p
ntpstat
- 检查是否启动ntp服务
lsof -i:123
- ntp客户机/etc/ntp.conf按照如下配置,并启动ntp服务
#配置上游时间服务器为本地的ntpd Server服务器
server 192.168.56.3
# 配置允许上游时间服务器主动修改本机的时间
restrict 192.168.56.3 nomodify notrap noquery
server 127.127.1.0
fudge 127.127.1.0 stratum 10
3 Hadoop安装
3.1 Hadoop 1.x伪分布式
伪分布式模式,只需要使用一台主机,以bigdata01为例。其即作为master也作为slaver使用。
3.1.1 上传hadoop-1.2.1-bin.tar.gz至/opt目录
tar -zxvf hadoop-1.2.1-bin.tar.gz
ln -s hadoop-1.2.1 hadoop
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GHJOHIAX-1669260284251)(https://note.youdao.com/yws/res/43665/WEBRESOURCEfc36e2011fbbb84df351b23a56e6adfb)]](https://i-blog.csdnimg.cn/blog_migrate/338f1a0f1379ca517241800af013cce5.png)
3.1.2 配置环境变量
如下图配置/etc/profile,并source生效
其中export HADOOP_HOME_WARN_SUPPRESS=1配置后是为了解决Hadoop1.2.1出现==Warning: $HADOOP_HOME is deprecated.==的问题
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-zMGfacj8-1669260284251)(https://note.youdao.com/yws/res/43669/WEBRESOURCEa2007c44b8ff0fe063e4e2accc7e8c7f)]](https://i-blog.csdnimg.cn/blog_migrate/fc08917eba5c14b28c137073ea32805c.png)
3.1.3 修改Hadoop配置文件
- conf/hadoop-env.sh
# The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
export JAVA_HOME=/usr/java/jdk1.7.0_80
- conf/core-site.xml
</xml version="1.0"/>
</xml-stylesheet type="text/xsl" href="configuration.xsl"/>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://bigdata01:9000</value>
<description>用于dfs命令模块中指定默认的文件系统协议</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop1xlocalm</value>
<description>临时目录,其他临时目录的父目录</description>
</property>
</configuration>
- conf/hdfs-site.xml
</xml version="1.0"/>
</xml-stylesheet type="text/xsl" href="configuration.xsl"/>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/1x/localm/hdfs/name</value>
<description>name node的元数据,以,号隔开,hdfs会把元数据冗余复制到这些目录,一般这些目录是不同的块设备,不存在的目录会被忽略掉</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/1x/localm/hdfs/data</value>
<description>data node的数据目录,以,号隔开,hdfs会把数据存在这些目录下,一般这些目录是不同的块设备,不存在的目录会被忽略掉</description>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
<description>文件复制的副本数,如果创建时不指定这个参数,就使用这个默认值作为复制的副本数</description>
</property>
</configuration>
- conf/mapred-site.xml
</xml version="1.0"/>
</xml-stylesheet type="text/xsl" href="configuration.xsl"/>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>bigdata01:9001</value>
<description>job tracker交互端口</description>
</property>
</configuration>
- conf/masters
bigdata01
- conf/slaves
bigdata01
3.1.4 启动Hadoop
- 格式化工作空间
hadoop namenode –format
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TDKloNQ0-1669260284252)(https://note.youdao.com/yws/res/43736/WEBRESOURCE4c67498d4a491877f237a30619d28d32)]](https://i-blog.csdnimg.cn/blog_migrate/57c06caada448d174272cdbfde9ed142.png)
- 启动hdfs
# 启动所有的Hadoop守护。包括namenode, datanode, jobtracker, tasktrack
start-all.sh
# 停止所有的Hadoop
stop-all.sh
# 启动Map/Reduce守护。包括Jobtracker和Tasktrack
start-mapred.sh
# 停止Map/Reduce守护
stop-mapred.sh
# 启动Hadoop DFS守护Namenode和Datanode
start-dfs.sh
# 停止DFS守护
stop-dfs.sh
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KT3OQPyQ-1669260284252)(https://note.youdao.com/yws/res/43742/WEBRESOURCE58844ec5f58e0f8e309dac406346dc4b)]](https://i-blog.csdnimg.cn/blog_migrate/da806a68b28112a5a42c4c80885aef3f.png)
3.1.5 使用jps命令查看结果
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-0vONVWun-1669260284252)(Img50.png)][外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZmJni7Jt-1669260284252)(https://note.youdao.com/yws/res/43746/WEBRESOURCE1e45b9664b526dbee7da547fcd728480)]](https://i-blog.csdnimg.cn/blog_migrate/a63024729531a3d4208e33f941325d5c.png)
3.1.6 查看Web界面
- NameNode
http://192.168.56.3:50070/dfshealth.jsp
- JobTracker
http://192.168.56.3:50030/jobtracker.jsp
3.2 Hadoop1.x完全分布式
安装部署完全分布式集群,现有3台机器,分别规划为
- bigdata01 : namenode,secondarynamenode,jobtracker
- bigdata02 : datanode,tasktracker
- bigdata03 : datanode,tasktracker
3.2.1 hadoop1.x配置
- conf/hadoop-env.sh
# The java implementation to use. Required.
# export JAVA_HOME=/usr/lib/j2sdk1.5-sun
export JAVA_HOME=/usr/java/jdk1.7.0_80
- conf/core-site.xml
</xml version="1.0"/>
</xml-stylesheet type="text/xsl" href="configuration.xsl"/>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://bigdata01:9000</value>
<description>用于dfs命令模块中指定默认的文件系统协议</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/tmp/hadoop1xclusterm</value>
<description>临时目录,其他临时目录的父目录</description>
</property>
</configuration>
- conf/hdfs-site.xml
</xml version="1.0"/>
</xml-stylesheet type="text/xsl" href="configuration.xsl"/>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>dfs.name.dir</name>
<value>/hadoop/1x/clusterm/hdfs/name</value>
<description>name node的元数据,以,号隔开,hdfs会把元数据冗余复制到这些目录,一般这些目录是不同的块设备,不存在的目录会被忽略掉</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/hadoop/1x/clusterm/hdfs/data</value>
<description>data node的数据目录,以,号隔开,hdfs会把数据存在这些目录下,一般这些目录是不同的块设备,不存在的目录会被忽略掉</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>文件复制的副本数,如果创建时不指定这个参数,就使用这个默认值作为复制的副本数</description>
</property>
</configuration>
- conf/mapred-site.xml
</xml version="1.0"/>
</xml-stylesheet type="text/xsl" href="configuration.xsl"/>
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>bigdata01:9001</value>
<description>job tracker交互端口</description>
</property>
</configuration>
- conf/masters
bigdata01
- conf/slaves
bigdata02
bigdata03
3.2.2 复制hadoop1.2.1的安装包至其他两个机器
- 在bigdata01上传两个安装脚本到/usr/local/bin目录下,方便后续集群间拷贝文件和执行命令。
cluster_copy_all_nodes 用来集群间同步拷贝文件:
#!/bin/bash
SELF=`hostname`
if [ -z "$NODE_LIST" ]; then
echo
echo Error: NODE_LIST environment variable must be set in .bash_profile
exit 1
fi
for i in $NODE_LIST; do
if [ ! $i = $SELF ]; then
if [ $1 = "-r" ]; then
scp -oStrictHostKeyChecking=no -r $2 $i:$3
else
scp -oStrictHostKeyChecking=no $1 $i:$2
fi
fi
done
wait
cluster_run_all_nodes 用来集群间同步运行命令:
#!/bin/bash
if [ -z "$NODE_LIST" ]; then
echo
echo Error: NODE_LIST environment variable must be set in .bash_profile
exit 1
fi
if [[ $1 = '--background' ]]; then
shift
for i in $NODE_LIST; do
ssh -oStrictHostKeyChecking=no -n $i "$@" &
done
else
for i in $NODE_LIST; do
ssh -oStrictHostKeyChecking=no $i "$@"
done
fi
wait
授予两个脚本的可执行权限:
chmod +x /usr/local/bin/cluster_*
- 压缩hadoop-1.2.1目录,并scp至bigdata02,bigdata03
tar -zcvf hadoop-1.2.1.tar.gz hadoop-1.2.1
cluster_copy_all_nodes.sh "bigdata02 bigdata03" /opt/hadoop-1.2.1.tar.gz /opt/hadoop-1.2.1.tar.gz
- 解压缩,并创建软连接
cluster_run_all_nodes.sh "bigdata02 bigdata03" "tar -zxvf /opt/hadoop-1.2.1.tar.gz"
cluster_run_all_nodes.sh "bigdata02 bigdata03" "cd /opt;ln -s hadoop-1.2.1 hadoop"
3.2.3 格式化启动
hadoop namenode -format
start-all.sh
3.2.4 验证
在各台机器上执行jps
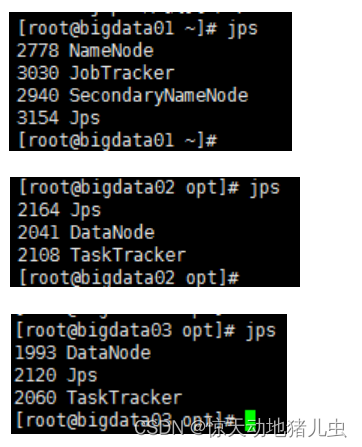
3.3 Hadoop2.X伪分布式
(略)
3.4 Hadoop2.X完全分布式
3.4.1 服务器功能规划
| BigData01 | BigData02 | BigData03 |
|---|---|---|
| NameNode | ResourceManager | |
| DataNode | DataNode | DataNode |
| NodeManager | NodeManager | NodeManager |
| HistoryServer | SecondaryNameNode |
3.4.2 BigData01安装
- 解压Hadoop目录
mkdir -p /opt/modules/app/
tar -zxf /root/hadoop-2.6.5.tar.gz -C /opt/modules/app/
- 配置环境变量(每台都配置)
/etc/profile
JAVA_HOME=/usr/java/jdk1.7.0_80
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
export HADOOP_HOME=/opt/modules/app/hadoop-2.6.5
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$JAVA_HOME/bin
- 配置Hadoop JDK路径
# 进入Hadoop目录
cd /opt/modules/app/hadoop-2.6.5/etc/hadoop
# 修改 hadoop-env.sh、 mapred-env.sh、 yarn-env.sh 文件中的JDK路径,必须写绝对路径,不能写环境变量
# The java implementation to use.
export JAVA_HOME="/usr/java/jdk1.7.0_80"
# 最后加上
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
- 配置文件修改
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://BigData01:8020</value>
<description>NameNode的地址</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/modules/app/hadoop-2.6.5/data/tmp</value>
<description>hadoop临时目录的地址,默认情况下,NameNode和DataNode的数据文件都会存在这个目录下的对应子目录下.应该保证此目录是存在的,如果不存在,先创建</description>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/name</value>
<description>NameNode的目录,该目录必须手动创建,不然启动报错</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/dfs/data</value>
<description>DataNode的目录,该目录可以由程序自动创建</description>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>BigData03:50090</value>
<description>secondaryNameNode的http访问地址和端口号</description>
</property>
</configuration>
slaves:slaves文件是指定HDFS上有哪些DataNode节点
BigData01
BigData02
BigData03
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>附属服务AuxiliaryService是由YARN中节点管理器NM启动的通用服务</description>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>BigData02</value>
<description>resourcemanager服务器</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>配置是否启用日志聚集功能</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
<description>配置聚集的日志在HDFS上最多保存多长时间</description>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>设置mapreduce任务运行在yarn</description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>BigData01:10020</value>
<description>设置mapreduce的历史服务器</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>BigData01:19888</value>
<description>设置历史服务器的web页面地址和端口号</description>
</property>
</configuration>
3.4.3 拷贝目录至其他机器
mkdir -p /opt/modules/app
scp -r /opt/modules/app/hadoop-2.6.5/ BigData02:/opt/modules/app
scp -r /opt/modules/app/hadoop-2.6.5/ BigData03:/opt/modules/app
3.4.4 格式 NameNode
在NameNode机器上执行格式化:
/opt/modules/app/hadoop-2.6.5/bin/hdfs namenode -format
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qyF5yQu9-1669260284257)(https://note.youdao.com/yws/res/43852/WEBRESOURCE9fab1b204a28ddf6b5d2e502b4949244)]](https://i-blog.csdnimg.cn/blog_migrate/7ae9b9b5acdd4c99d25626db5d99efb0.png)
3.4.5 启动集群
-
启动 HDFS 在BigData01主机上执行:
start-dfs.sh -
启动YARN 在BigData01主机执行
start-yarn.sh -
启动ResourceManager 在BigData02主机执行
yarn-daemon.sh start resourcemanager -
启动日志服务器 在BigData03主机执行
mr-jobhistory-daemon.sh start historyserver -
检查进程

-
直接启动,无需执行上面多个命令
start-all.sh -
查看 HDFS Web 页面
-
查看 YARN Web 页面
3.5 Hadoop3.X完全分布式
此处未做测试,可以参考文章:最新Hadoop3.2.1完全分布式集群安装教程
3.6 Docker安装Hadoop
通过Docker可以更方便的安装Hadoop集群,而无需配置如此多的机器。具体安装方法,请参见:Docker章节。
4 问题
4.1 当把配置resourcemanager到BigData02时,start-all.sh启动报错
2018-08-09 11:06:46,081 INFO org.apache.hadoop.service.AbstractService: Service ResourceManager failed in state STARTED; cause: org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.net.BindException: Problem binding to [BigData02:8031] java.net.BindException: 无法指定被请求的地址; For more details see: http://wiki.apache.org/hadoop/BindException
org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.net.BindException: Problem binding to [BigData02:8031] java.net.BindException: 无法指定被请求的地址; For more details see: http://wiki.apache.org/hadoop/BindException
at org.apache.hadoop.yarn.factories.impl.pb.RpcServerFactoryPBImpl.getServer(RpcServerFactoryPBImpl.java:139)
at org.apache.hadoop.yarn.ipc.HadoopYarnProtoRPC.getServer(HadoopYarnProtoRPC.java:65)
at org.apache.hadoop.yarn.ipc.YarnRPC.getServer(YarnRPC.java:54)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceTrackerService.serviceStart(ResourceTrackerService.java:162)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:193)
at org.apache.hadoop.service.CompositeService.serviceStart(CompositeService.java:120)
yarn-site.xml 按照以下配置也不行
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>附属服务AuxiliaryService是由YARN中节点管理器NM启动的通用服务</description>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>192.168.137.12:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>192.168.137.12:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>192.168.137.12:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>192.168.137.12:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>192.168.137.12:8088</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>配置是否启用日志聚集功能</description>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
<description>配置聚集的日志在HDFS上最多保存多长时间</description>
</property>
</configuration>
原因暂未找到
4.2 执行命令后提示WARN
[root@bigdata01 ~]# hadoop fs -ls /
18/09/13 10:45:34 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
drwxr-xr-x - root supergroup 0 2018-09-13 10:36 /input
[root@bigdata01 ~]#
问题处理参见:
util.NativeCodeLoader: Unable to load native-hadoop library for your platform


















 3476
3476

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









