




背景
基于 LangChain 0.3集成 Milvus 2.5向量数据库构建的 NFRA(National Financial Regulatory Administration,国家金融监督管理总局)政策法规智能问答系统,第一个版本的检索召回率是 79.52%,尚未达到良好、甚至是优秀的水平,有待优化、提升。
目标
检索召回率 >= 85%
实现方法
本次探究:把文件按法条逐条分块,不考虑块的大小,能否会提高分块文本的检索召回率。而本次探究实现的方法,则对应于 RAG系统整体优化思路图(见下图)的“文档分块”。
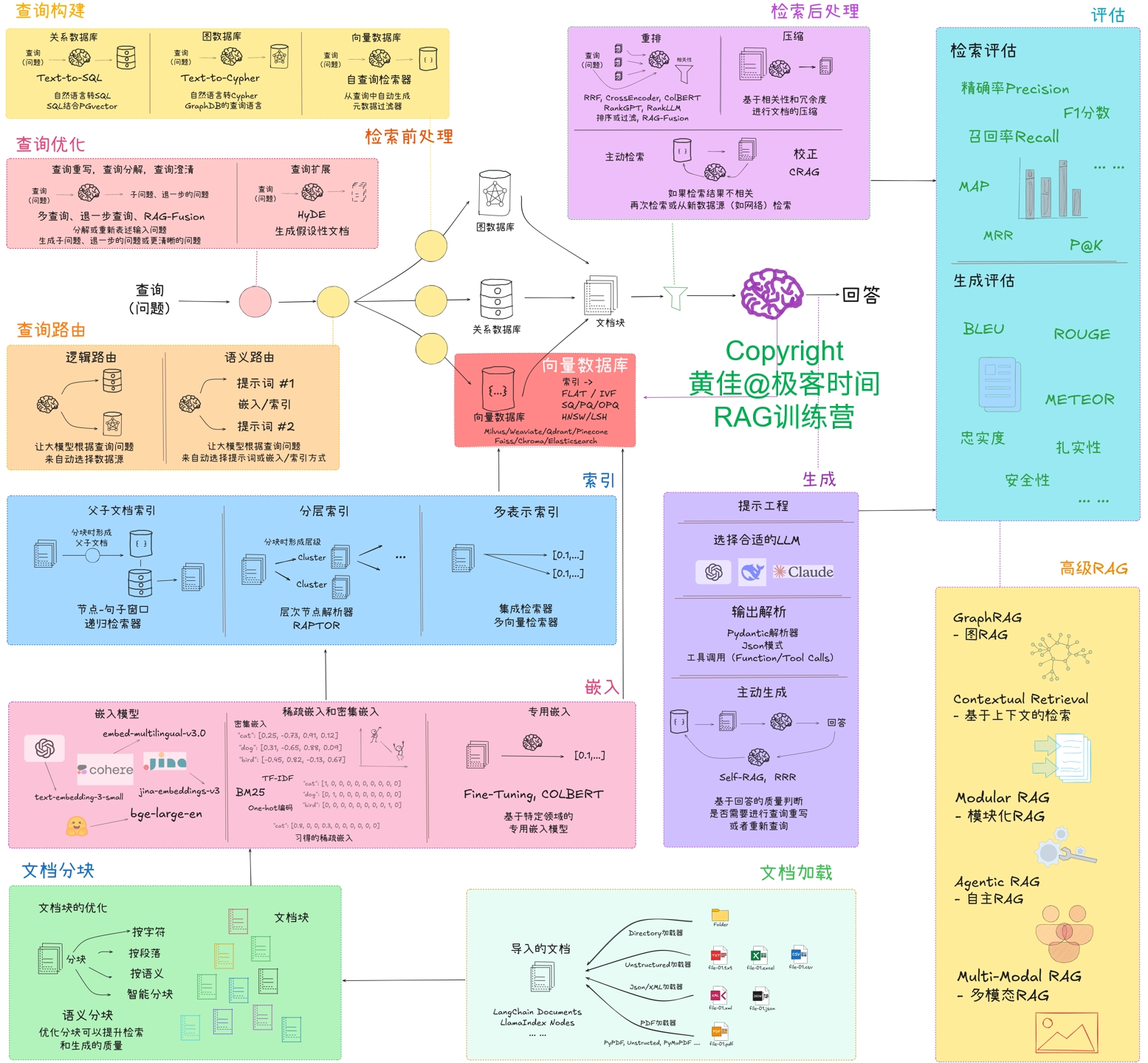
RAG系统整体优化思路图
实现思路:
- 了解 LangChain 的文本切分器是否支持不考虑块的大小,且使用正则表达式来分块的;
- 若上述方法行不通,就考虑不使用 LangChain 的切分器,通过常规的 Python编码来实现文件内容的分块。
执行过程
LangChain 文本切分器
一开始,尝试看官网的文档,发现它也不像平常看过的 Java帮助文档那样,具体介绍每一个类以及类中的方法等,它写的更加简单与实用。见下图:
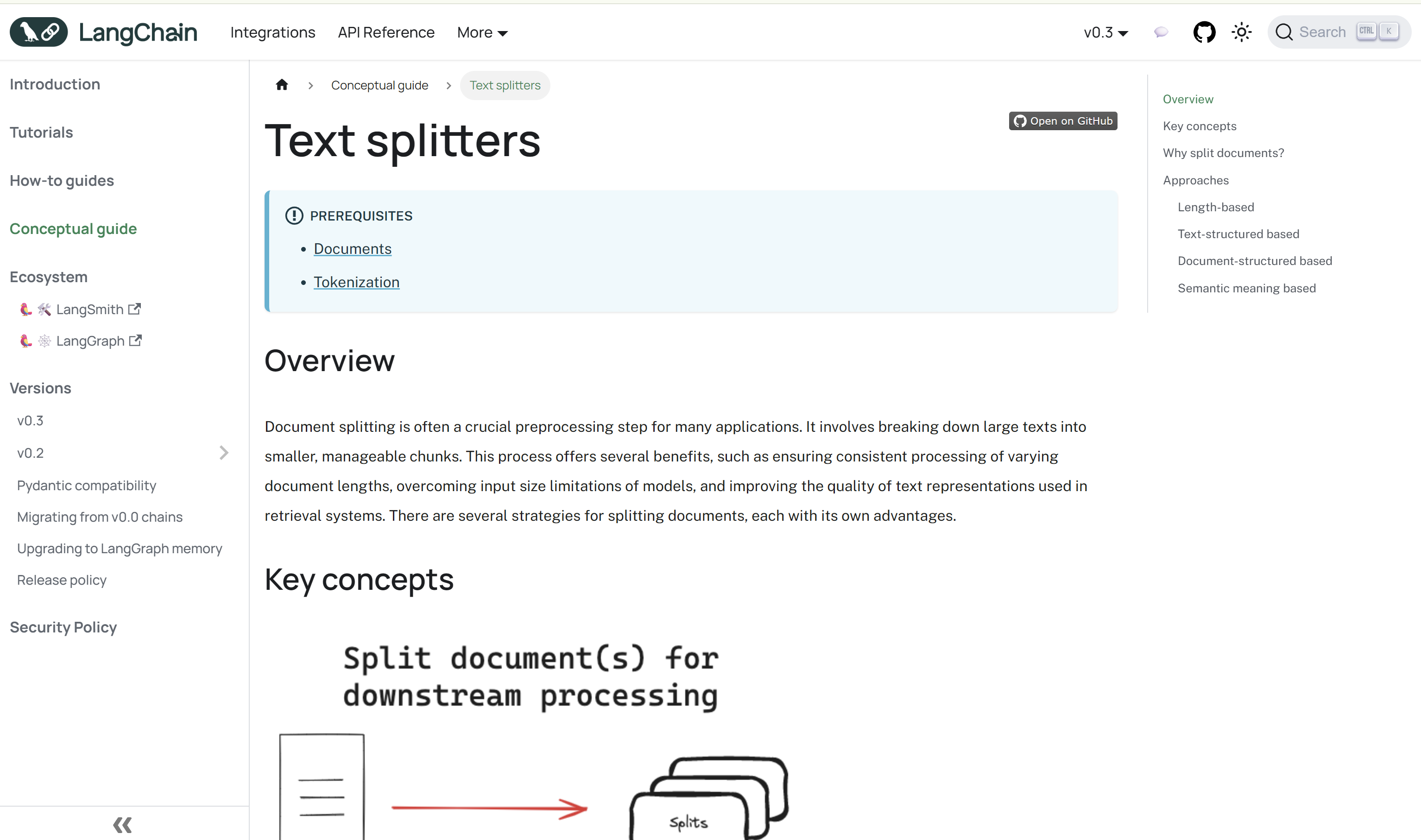
图片来源:Text splitters | 🦜️🔗 LangChain
从图中的右侧可知,LangChain 文本切分器的实现分类有:
- 基于长度的切分;
- 基于文本结构的切分;
- 基于文件结构的切分;
- 基于语义的切分。
从上述分类来看,第一类基于长度,就不用考虑了;基于文本结构的切分,是可以考虑的,这类应该就有关于正则表达式。而至于其他两类,显然不符合本次探究的内容,也是不用考虑的。
而进一步了解基于文本结构切分实现,可见下图:
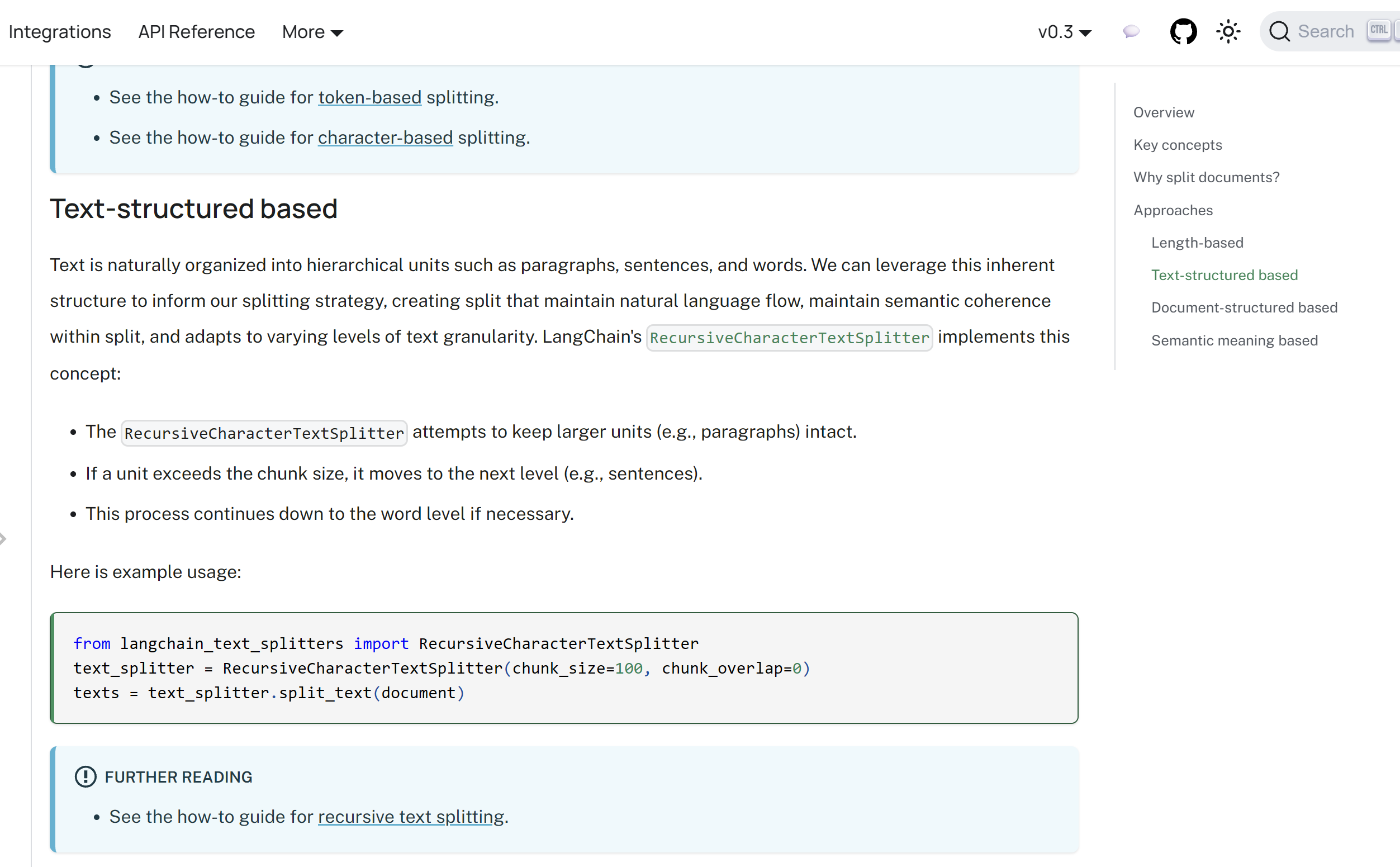
图片来源:Text splitters | 🦜️🔗 LangChain
(大家看这种英文技术文档,不要畏惧,刚开始不熟悉时,可以使用浏览器翻译插件来辅助,等熟悉其中的关键内容
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









