




背景
基于 LangChain 0.3 集成 Milvus 2.5 向量数据库构建的 NFRA(National Financial Regulatory Administration,国家金融监督管理总局)政策法规智能问答系统。(具体代码版本,可见)
在此之前,进行了通过查询重写、查询分解结合RRF重排技术来实现召回率提升的探究,最终结果是未能实现召回率提升到 85%以上的目标。为此,继续。
目标
检索召回率 >= 85%
实现方法
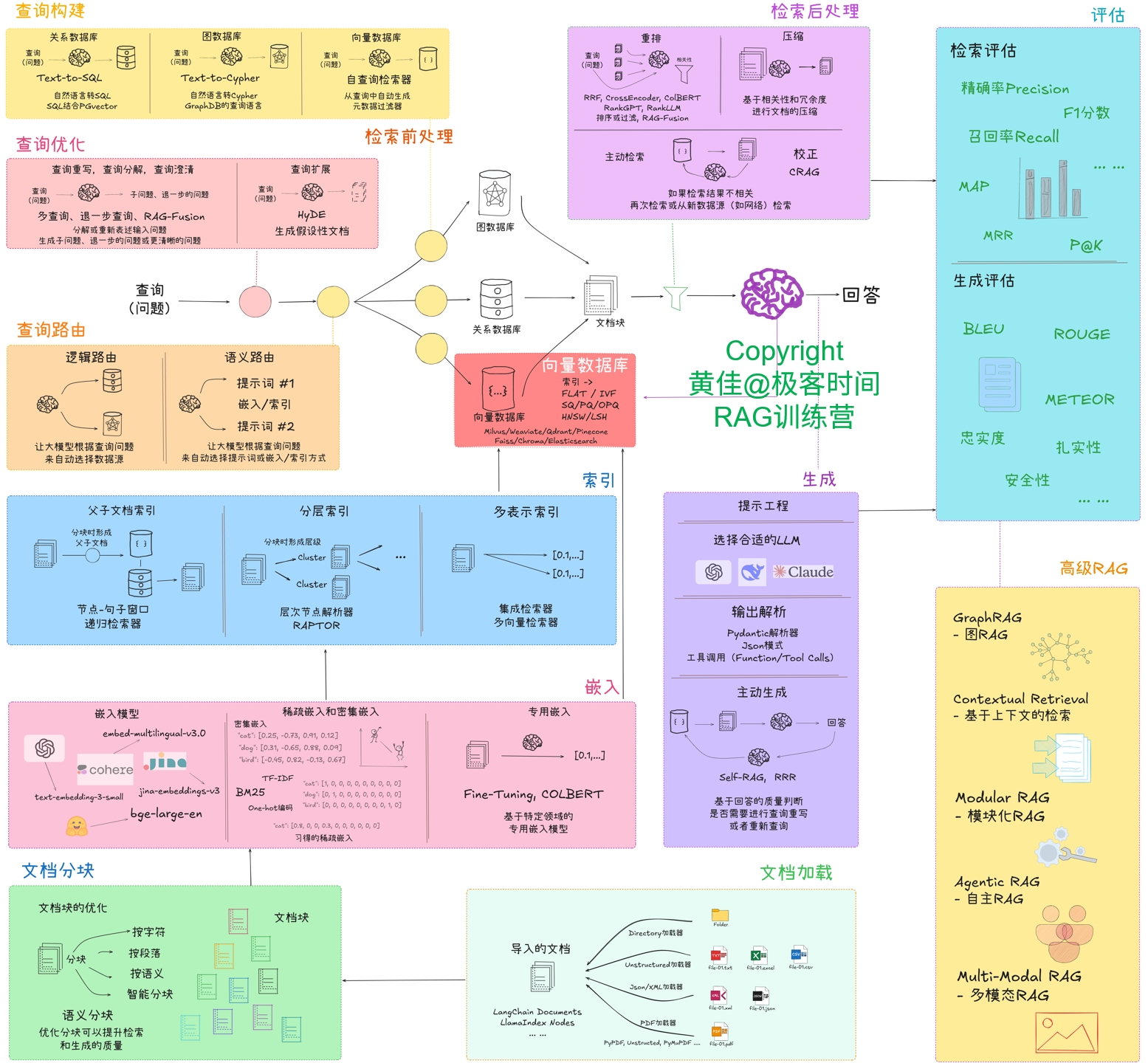
本次探究:在检索前进行查询问题重写来提升检索的质量,从而提升检索召回率。重点是使用 LangChain 提供的工具类:langchain.retrievers.re_phraser.RePhraseQueryRetriever。这个对应于 RAG系统整体优化思路图(见下图)的“检索前处理-查询优化”。
执行过程
上一次探究也有使用 RePhraseQueryRetriever,只不过关注的是先实现,未能处理好细节问题,比如大语言模型的选择等。
RePhraseQueryRetriever 在检索文档的实现与 MultiQueryRetriever 不同,前者是将重写的结果作为参数传递给成员变量 retriever,在调用的时候若是自定义了 retriever,那么最终执行检索的是自定义的检索类;而 MultiQueryRetriever 它是生成不同的查询变体,因此它是遍历了不同的查询变体来检索,所以才会有把结果去重合并这个步骤。它们相关的处理源码如下:
RePhraseQueryRetriever:
def _get_relevant_documents(
self,
query: str,
*,
run_manager: CallbackManagerForRetrieverRun,
) -> List[Document]:
"""Get relevant documents given a user question.
Args:
query: user question
Returns:
Relevant documents for re-phrased question
"""
re_phrased_question = self.llm_chain.invoke(
query, {"callbacks": run_manager.get_child()}
)
logger.info(f"Re-phrased question: {re_phrased_question}")
docs = self.retriever.invoke(
re_phrased_question, config={"callbacks": run_manager.get_child()}
)
return docsMultiQueryRetriever:
def _get_relevant_documents(
self,
query: str,
*,
run_manager: CallbackManagerForRetrieverRun,
) -> List[Document]:
"""Get relevant documents given a user query.
Args:
query: user query
Returns:
Unique union of relevant documents from all generated queries
"""
queries = self.generate_queries(query, run_manager)
if self.include_original:
queries.append(query)
documents = self.retrieve_documents(queries, run_manager)
return self.unique_union(documents)
def generate_queries(
self, question: str, run_manager: CallbackManagerForRetrieverRun
) -> List[str]:
"""Generate queries based upon user input.
Args:
question: user query
Returns:
List of LLM generated queries that are similar to the user input
"""
response = self.llm_chain.invoke(
{"question": question}, config={"callbacks": run_manager.get_child()}
)
if isinstance(self.llm_chain, LLMChain):
lines = response["text"]
else:
lines = response
if self.verbose:
logger.info(f"Generated queries: {lines}")
return lines
def retrieve_documents(
self, queries: List[str], run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
"""Run all LLM generated queries.
Args:
queries: query list
Returns:
List of retrieved Documents
"""
documents = []
for query in queries:
docs = self.retriever.invoke(
query, config={"callbacks": run_manager.get_child()}
)
documents.extend(docs)
return documents在源头搞清楚了 RePhraseQueryRetriever,接下来就是实现了,此次实现不单是使用了它,也借鉴了 MultiQueryRetriever 的实现思路。实现的检索过程如下图:( 相关图和代码已更新到项目中,可查看 )
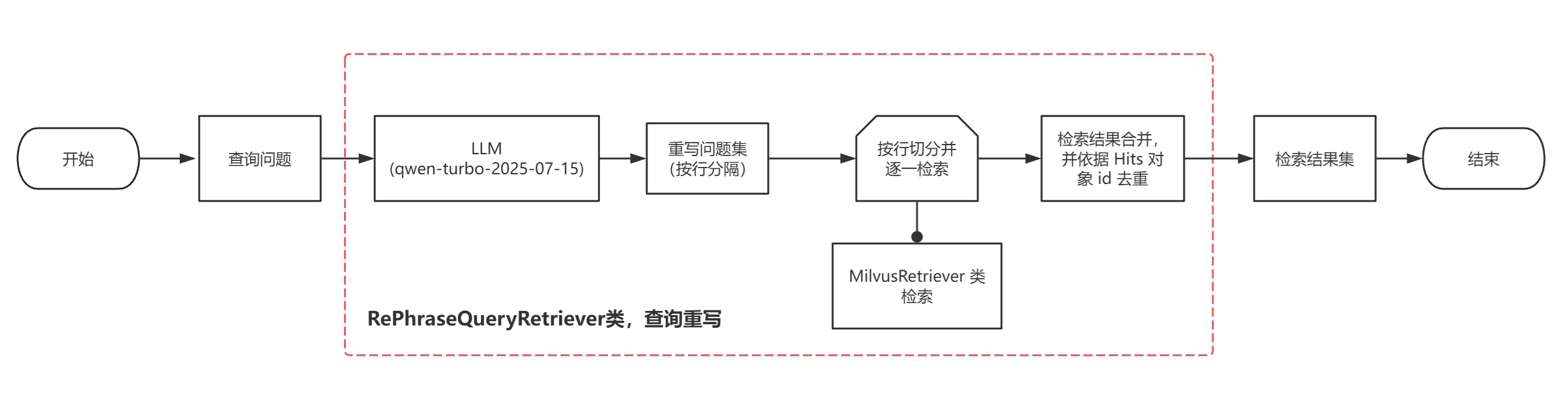
关键处理:根据 LLM 输出的重写问题集(具体个数就体现在 prompt 上)进行切割,然后逐一执行检索。
代码实现如下:
- 查询重写检索器:
def query_rewrite_retriever(retriever: BaseRetriever, model: BaseModel) -> BaseRetriever:
retriever_from_llm = RePhraseQueryRetriever.from_llm(
retriever=retriever,
llm=model,
prompt=RE_QUERY_PROMPT_TEMPLATE
)
return retriever_from_llm- 大语言模型:
def get_qwen_model(
model: str = "qwen-turbo-2025-07-15",
streaming: bool = True,
callbacks: Callbacks = None):
"""获取通义千问模型实例
- model: 模型名称,默认为 "qwen-turbo-2025-07-15"
- streaming: 是否启用流式输出,默认为 True
- callbacks: 回调函数列表,默认为 None
"""
model = ChatTongyi(model=model, streaming=streaming, callbacks=callbacks)
return model- 提示词:
re_query_prompt_template = """您是 AI 语言模型助手。您的任务是生成给定问题的3个不同问法,用来从矢量数据库中检索相关文档。
通过对问题生成多个不同的问法,来克服基于内积(IP)的相似性检索的一些限制。提供这些用换行符分隔的替代问题,不要给出多余的回答。
问题:{question}"""
RE_QUERY_PROMPT_TEMPLATE = PromptTemplate(
template=re_query_prompt_template, input_variables=["question"]
)检索评估(召回率)
RAG 相关处理说明
切分策略:分块大小: 500; 分块重叠大小: 100; 使用正则表达式,[r"第\S*条 "]
嵌入模型:模型名称: BAAI/bge-base-zh-v1.5 (使用归一化)
向量存储:向量索引类型:IVF_FLAT (倒排文件索引+精确搜索);向量度量标准类型:IP(内积); 聚类数目: 100; 存储数据库: Milvus
向量检索:查询时聚类数目: 10; 检索返回最相似向量数目: N
评估数据集说明
此次使用新的评估数据集,问答对增加到了 100个,既是增加了问答对使评估结果更加可信,也是为了方便计算召回率。
检索返回最相似向量数目:N = 2
检索结果如下两表:
表1:执行时段分为上午、下午、晚上,比较分散
| 评估组别 | 重写 LLM | 执行时段 | 问题总数 | 召回总数 | 召回率 |
| 1 | qwen-turbo-2025-07-15 | 上午10-12点 | 100 | 80 | 80.00% |
| 2 | qwen-turbo-2025-07-15 | 上午10-12点 | 100 | 82 | 82.00% |
| 3 | qwen-turbo-2025-07-15 | 下午17-19点 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









