




URL编码和反编码
class URLParser{
public static void main(String[] args) throws IOException {
String s = "c++";
String r = URLEncoder.encode(s,"UTF-8");
System.out.println(r);
//反编码
s = URLDecoder.decode(r,"UTF-8");
System.out.println(s);
}
}
c%2B%2B
c++
class SimpleHttpClient{
//GET http://www.baidu.com 1.0
public static void main(String[] args) {
StringBuilder request = new StringBuilder();
request.append("GET / HTTP/1.0\r\n");
request.append("Host:www.baidu.com\r\n");
request.append("\r\n");//代表是空行
System.out.println(request.toString());
}
}
发送请求收到响应把他打印出来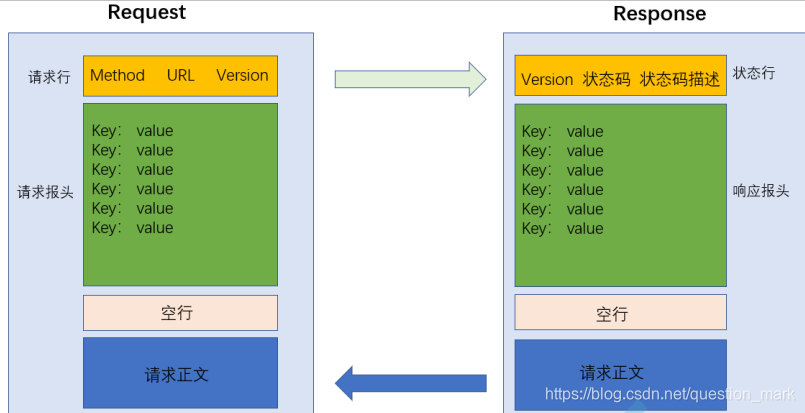
class SimpleHttpClient{
//GET http://www.baidu.com 1.0
public static void main(String[] args) throws IOException {
StringBuilder request = new StringBuilder();
request.append("GET / HTTP/1.0\r\n");
request.append("Host:www.baidu.com\r\n");
request.append("\r\n");//代表是空行
System.out.println(request.toString());
//以上部分就是Request
Socket socket = new Socket("www.baidu.com",80);
socket.getOutputStream().write(request.toString().getBytes("UTF-8"));
socket.getOutputStream().flush();
socket.shutdownOutput();
byte[] buffer = new byte[4096];
int len = socket.getInputStream().read(buffer);
socket.close();
String response = new String(buffer,0,len,"UTF-8");
System.out.println(response);
//接
}
}
class SimpleHttpClient{
//GET http://www.baidu.com 1.0
public static void main(String[] args) throws IOException {
StringBuilder request = new StringBuilder();
request.append("GET / HTTP/1.0\r\n");
request.append("Host:www.baidu.com\r\n");
request.append("\r\n");//代表是空行
System.out.println(request.toString());
Socket socket = new Socket("www.baidu.com",80);
socket.getOutputStream().write(request.toString().getBytes("UTF-8"));
socket.getOutputStream().flush();
socket.shutdownOutput();
//1解析响应
//2把响应体 保存到一个文件,百度.html
byte[] buffer = new byte[4096];
int len = socket.getInputStream().read(buffer);
// String response = new String(buffer,0,len,"UTF-8");
// System.out.println(response);
//假设已经把状态行+所有状态头+空行都读到了
int index = -1;
for (int i = 0; i < len ; i++) {
if (buffer[i] == '\r' && buffer[i + 1] == '\n'
&& buffer[i + 2] == '\r' && buffer[i + 3] == '\n'){
index = i;
break;
}
}
System.out.println(index);
int 已经读到的正文长度 = len - index - 4;
ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(buffer,0,index + 4);
Scanner scanner = new Scanner(byteArrayInputStream,"UTF-8");
String statusLine = scanner.nextLine();
System.out.println("状态行" + statusLine);
String line;
int contenetLength = -1;
while ((line = scanner.nextLine()).length() != 0){
//line 是空行
String[] kv = line.split(":");
String key = kv[0].trim();
String value = kv[1].trim();
System.out.println("响应头: " + key + " = " + value);
if (key.equalsIgnoreCase("Content-Length")){
contenetLength = Integer.parseInt(value);//代表正文长度,有了正文长度就可以把所有正文读出来
}
}
int 还需要读的正文的长度 = contenetLength - 已经读到的正文长度;
byte[] body = new byte[contenetLength];
System.arraycopy(buffer,index+4,
body,
0,已经读到的正文长度);
int 实际又读到的长度 = socket.getInputStream().read(body,已经读到的正文长度,还需要读的正文的长度);
System.out.println(contenetLength);
System.out.println(已经读到的正文长度);
System.out.println(还需要读的正文的长度);
System.out.println(实际又读到的长度);
FileOutputStream os = new FileOutputStream("百度.html");
os.write(body);
os.close();
}
}
http状态码
StringBuilder request = new StringBuilder();
request.append("GET /no_such_path HTTP/1.0\r\n");
request.append("Host:www.baidu.com\r\n");
request.append("\r\n");//代表是空行
System.out.println(request.toString());
Socket socket = new Socket("www.baidu.com",80);
socket.getOutputStream().write(request.toString().getBytes("UTF-8"));
socket.getOutputStream().flush();
socket.shutdownOutput();
//1解析响应
//2把响应体 保存到一个文件,百度.html
byte[] buffer = new byte[4096];
int len = socket.getInputStream().read(buffer);
String response = new String(buffer,0,len,"UTF-8");
System.out.println(response);
System.exit(0);
GET /no_such_path HTTP/1.0
Host:www.baidu.com
HTTP/1.0 302 Found
Cache-Control: max-age=86400
Content-Length: 222
Content-Type: text/html; charset=iso-8859-1
Date: Fri, 27 Dec 2019 08:52:28 GMT
Expires: Sat, 28 Dec 2019 08:52:28 GMT
Location: https://www.baidu.com/search/error.html
Server: Apache
<!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN">
<html><head>
<title>302 Found</title>
</head><body>
<h1>Found</h1>
<p>The document has moved <a href="http://www.baidu.com/search/error.html">here</a>.</p>
</body></html>



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









