







 文章详细介绍了Wayland客户端如何通过申请graphicbuffer进行渲染,并将其提交给Waylandcompositor进行合成与输出的过程。涉及到buffer的类型、内存管理、OpenGL渲染以及服务器端的合成策略。
文章详细介绍了Wayland客户端如何通过申请graphicbuffer进行渲染,并将其提交给Waylandcompositor进行合成与输出的过程。涉及到buffer的类型、内存管理、OpenGL渲染以及服务器端的合成策略。
渲染流水线
一个Wayland client要将内存渲染到屏幕上,首先要申请一个graphic buffer,绘制完后传给Wayland compositor并通知其重绘。Wayland compositor收集所有Wayland client的请求,然后以一定周期把所有提交的graphic buffer进行合成。合成完后进行输出。本质上,client需要将窗口内容绘制到一个和compositor共享的buffer上。这个buffer可以是普通共享内存,也可以是DRM中的GBM或是gralloc提供的可供硬件(如GPU)操作的graphic buffer,当然你也可以直接调用ion的接口去创建buffer。在大多数移动平台上,没有专门的显存,因此它们最终都来自系统内存,区别在于图形加速硬件一般会要求物理连续且符合对齐要求的内存。如果是普通共享内存,一般是物理不连续的,多数情况用软件渲染。有些图形驱动也支持用物理不连续内存做硬件加速,但效率相对会低一些。根据buffer类型的不同,client可以选择自己绘制,或是通过Cairo,OpenGL绘制,或是更高层的如Qt,GTK+这些widget库等绘制。绘制完后client将buffer的handle传给server,以及需要重绘的区域。在server端,compositor将该buffer转为纹理,最后将其与其它的窗口内容进行合成。下面是抽象的流程图:
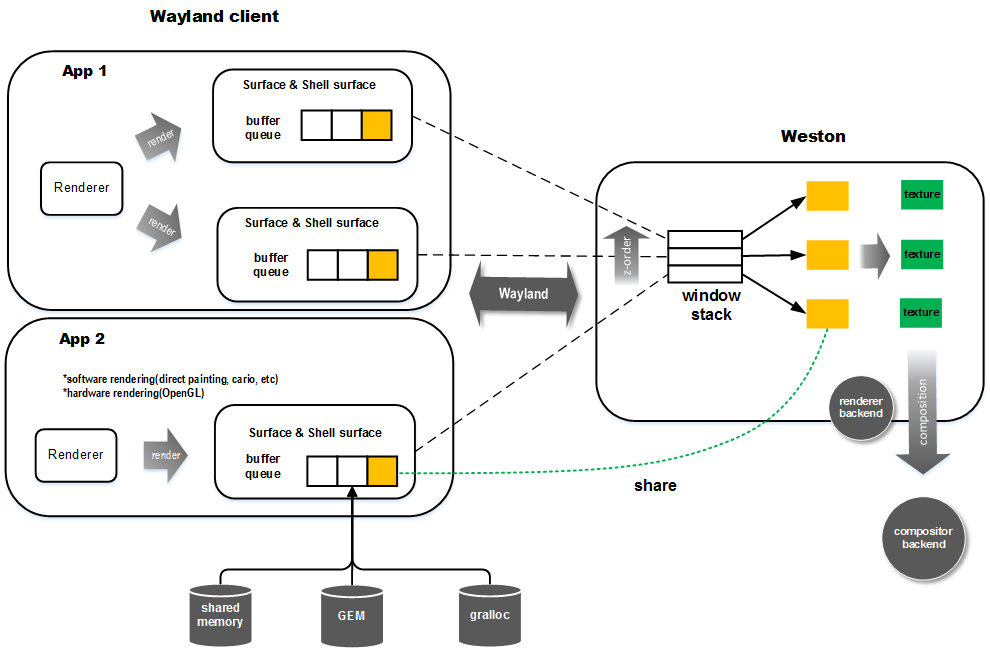
shm类型的window渲染显示的流程
1.attach
根据client端的surface resource在server端分配buffer,给pending state作为pending中的buffer,下面的操作对象均是pending中的buffer。
2.damage
新旧damage区域融合得到新的damage区域。
3.commit
3.1 opengl渲染前的准备
根据shm buffer的类型、大小,设置对应的gl参数。保存到gl_surface_state结构体中。如果纹理和之前存在的不匹配,会手动生成一个合适的新纹理。
3.2 正式渲染显示
weston_output_repaint使用opengl渲染surface并将framebuffer写入drm设备。repaint_flush应用pending state。渲染步骤在repaint循环中。
buffer
weston-simple-shm::create_shm_buffer
用户空间:
struct buffer {
struct wl_buffer *buffer;
void *shm_data;
int busy;
};
fd = os_create_anonymous_file(size);
用户空间创建size大小文件,取得fd。
data = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
将fd用户空间buffer映射到进程内核空间。
pool = wl_shm_create_pool(display->shm, fd, size);
这个地方创建一个pool。这个pool可以很大,然后后续wl_shm_pool_create_buffer再从这个pool中分出来一部分用作绘画
对应的server端操作: wayland/src/wayland-shm.c::shm_create_pool
struct wl_shm_pool *pool;
pool->data = mmap(NULL, size, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);[server]
创建pool。映射同一个fd;此时client与weston达成共享内存。
也通过server端的操作,为client端的wl_shm_pool赋值。并最终将pool传给client
wl_resource_set_implementation(pool->resource,
&shm_pool_interface,
pool, destroy_pool);
需要明确,buffer是用户端创建的,用户端和server端通过传递fd实现buffer共享。
用户空间:
buffer->buffer = wl_shm_pool_create_buffer(pool, 0, width, height, stride, format);
这个buffer->buffer对应的是wl_buffer结构体。从pool中取出一部分,套上一个wl_buffer
对应的server端操作: wayland/src/wayalnd-shm.c::shm_pool_create_buffer
创建wl_shm_buffer结构体,并赋值,width/height/format/stride/offset;将之前创建的pool结构体付给buffer。
buffer->pool = pool;
通过pool获取wl_buffer,对用户空间的buffer进行赋值。注意是将wl_shm_buffer赋给wl_buffer
wl_resource_set_implementation(buffer->resource,
&shm_buffer_interface,
buffer, destroy_buffer);
用户空间:
wl_shm_pool_destroy(pool);
对应的server端操作: wayland/src/wayalnd-shm.c::shm_pool_destroy,随后调用wl_resource_destroy
内部计数器-1,如果pool的计数为0[destroy pool且destroy buffer之后],则销毁pool的所有资源
最终用户空间将mmap的地址给了buffer->shm_data //也就是对应weston:server的pool->data
buffer->shm_data = data;
提供给client的绘画地址。随即client会对buffer->shm_data空间执行绘画;
client和sever分别通过wl_buffer以及wl_shm_buffer对实际的绘画部分内容进行管理,他俩应该是等价的。
Server端是wl_shm_buffer->wl_shm_pool->data;
1.buffer本质上只有一块,是用户空间创建以后用来创建pool用到的buffer。
2.pool的本质是可以对这个buffer进行分割以及管理,分割通过offset的方式。
3.weston_buffer.release是由wl_buffer_send_release实现的通知。weston_buffer结构体本身有一个busy_count的计数器,在weston_buffer_reference或者其他函数调用的时候,如果发现busy_count为0,就会调用wl_buffer_send_release发送信号
surface_attach
attach函数拿到client端的buffer,并传给surface->pending state结构体。
static void
surface_attach(struct wl_client *client,
struct wl_resource *resource,
struct wl_resource *buffer_resource, int32_t sx, int32_t sy)
{
struct weston_surface *surface = wl_resource_get_user_data(resource);
struct weston_buffer *buffer = NULL;
if (buffer_resource) {
//核心功能:根据client端的resource在server分配buffer
buffer = weston_buffer_from_resource(buffer_resource);
if (buffer == NULL) {
wl_client_post_no_memory(client);
return;
}
}
//将分配的buffer设置为pending,待更新到current
weston_surface_state_set_buffer(&surface->pending, buffer);
surface->pending.sx = sx;
surface->pending.sy = sy;
surface->pending.newly_attached = 1;
}attach将wl_buffer设置为pending wl_buffer而不是currect。
本质上是需要window->surface与buffer->buffer 绑定;把用户空间的buffer管理起来,赋值到weston里面的weston_buffer结构体中,并且将weston_buffer与他的weston_surface->pending结构体关联起来。
在这里,client端的wl_buffer和server端的weston_buffer应该是等价的。
做完这一步,那么weston_surface->pending->buffer也就有了对应的weston-buffer
surface_damage
static void
surface_damage(struct wl_client *client,
struct wl_resource *resource,
int32_t x, int32_t y, int32_t width, int32_t height)
{
struct weston_surface *surface = wl_resource_get_user_data(resource);
if (width <= 0 || height <= 0)
return;
pixman_region32_union_rect(&surface->pending.damage_surface,
&surface->pending.damage_surface,
x, y, width, height);
}pixman_region32_union_rect将原有的damage区域与新的damage区域进行组合,得到新的damage区域。
surface_commit
先对pending中的buffer进行缩放、旋转、长宽有效性等一系列验证,然后weston_surface_commit函数将surface提交给opengl渲染并合成显示。下面会详细讲解surface的渲染显示过程。
->surface_commit
->1. weston_surface_is_pending_viewport_source_valid//对pending buffer进行缩放、旋转等数据校验操作
->2. weston_surface_is_pending_viewport_dst_size_int//校验surface长宽的有效性
->3. surface->pending.acquire_fence_fd//fence_fd有效
->wl_shm_buffer_get(surface->pending.buffer->resource)//检查shm buffer
->4.weston_surface_commit(surface)//commit surface
->4.1 weston_surface_commit_state(surface, &surface->pending)//重点函数
->4.2 weston_surface_commit_subsurface_order(surface)
->4.3 weston_surface_schedule_repaint//重绘定时器
->5. weston_subsurface_commit(surface)//subsurface commitweston_surface_commit_state
先将pending中的buffer提取到surface中。attach的时候需要判断weston_buffer的类型,shm、egl、dmabuf三种类型对应了三种gl render attach函数。
weston_surface_commit_state(操作的是pending buffer)
1.->weston_surface_attach(surface, state->buffer)
weston_buffer_reference(&surface->buffer_ref, buffer)//关联weston_surface和weston_buffer
surface->compositor->renderer->attach(surface, buffer)//使用合成器里的渲染器gl_renderer_attach
gl_renderer_attach_shm//
gl_renderer_attach_egl//创建对应surface buffer的egl_image,激活绑定纹理。
gl_renderer_attach_dmabuf//使用dmabuf时的函数
2.//渲染结束清理pending buffer
3.-> weston_surface_build_buffer_matrix(surface, &surface->surface_to_buffer_matrix)//对surface进行旋转,裁剪,缩放等矩阵操作
4.->weston_surface_update_size(surface)//设置surface大小
5.->surface->committed(surface, state->sx, state->sy)
//若desktop,则surface.c:: weston_desktop_surface_committed, 看上去是设置surface在屏幕上的位置,也就是显示位置,窗口管理一部分;主要是update了size,需要做对应的改动
6.->apply_damage_buffer//dmage 区域合并
7.->wl_surface.set_input_region
8.->wl_surface.frame//插入frame_callbake_list链表
9.->wl_signal_emit(&surface->commit_signal, surface)
//!最后发出commit_signal,将output从pending list移除掉并添加进合成器的output_list这里以shm为例进行深入分析。在repaint之前gl_renderer_attach_shm需要为渲染做一些准备,获取shm buffer,绑定到传入的surface buffer,根据shm buffer的参数设置gl相关的参数(像素格式、大小),纹理不匹配时ensure_textures生成新纹理,gl_surface_state表示这个surface的渲染状态。
static void
gl_renderer_attach_shm(struct weston_surface *es, struct weston_buffer *buffer,
struct wl_shm_buffer *shm_buffer)
{
struct weston_compositor *ec = es->compositor;
struct gl_renderer *gr = get_renderer(ec);
struct gl_surface_state *gs = get_surface_state(es);
GLenum gl_format[3] = {0, 0, 0};
GLenum gl_pixel_type;
int pitch;
int num_planes;
buffer->shm_buffer = shm_buffer;
buffer->width = wl_shm_buffer_get_width(shm_buffer);
buffer->height = wl_shm_buffer_get_height(shm_buffer);
num_planes = 1;
gs->offset[0] = 0;
gs->hsub[0] = 1;
gs->vsub[0] = 1;
switch (wl_shm_buffer_get_format(shm_buffer)) {
case WL_SHM_FORMAT_XRGB8888:
...
case WL_SHM_FORMAT_ARGB8888:
gs->shader_variant = SHADER_VARIANT_RGBA;
pitch = wl_shm_buffer_get_stride(shm_buffer) / 4;
gl_format[0] = GL_BGRA_EXT;
gl_pixel_type = GL_UNSIGNED_BYTE;
es->is_opaque = false;
break;
case WL_SHM_FORMAT_RGB565:
...
case WL_SHM_FORMAT_YUV420:
...
case WL_SHM_FORMAT_NV12:
...
case WL_SHM_FORMAT_YUYV:
...
default:
weston_log("warning: unknown shm buffer format: %08x\n",
wl_shm_buffer_get_format(shm_buffer));
return;
}
//纹理不匹配的时候,生成新纹理
if (pitch != gs->pitch ||
buffer->height != gs->height ||
gl_format[0] != gs->gl_format[0] ||
gl_format[1] != gs->gl_format[1] ||
gl_format[2] != gs->gl_format[2] ||
gl_pixel_type != gs->gl_pixel_type ||
gs->buffer_type != BUFFER_TYPE_SHM) {
...
...
ensure_textures(gs, GL_TEXTURE_2D, num_planes);
}
}weston_surface_schedule_repaint(surface)
渲染前的准备工作完成之后,下面就是渲染并显示这个surface,这里才开始真正调用到opengl和drm。
weston_output_schedule_repaint
->idle_repaint
->start_repaint_loop
->drm_output_start_repaint_loop//libweston/backend-drm/drm.c
drmVBlank vbl = {
.request.type = DRM_VBLANK_RELATIVE,
.request.sequence = 0,
.request.signal = 0,
};
//设置用于输出的vblank同步的类型,传入crtc的pipeline,返回当前的显示器是主显示器,还是
//副显示器
vbl.request.type |= drm_waitvblank_pipe(output->crtc);
//等待vblank事件触发,成功则返回0
ret = drmWaitVBlank(backend->drm.fd, &vbl);
/* Error ret or zero timestamp means failure to get valid timestamp */
if ((ret == 0) && (vbl.reply.tval_sec > 0 || vbl.reply.tval_usec > 0)) {
//屏幕刷新率计算
weston_compositor_read_presentation_clock(backend->compositor,
&tnow);
drm_output_update_msc(output, vbl.reply.sequence);
weston_output_finish_frame(output_base, &ts,
WP_PRESENTATION_FEEDBACK_INVALID);
}
//第一次启动不会走到这里,在weston_output_finish_frame中启动repaint循环,repaint得到数据后才会走到这里。
pending_state = drm_pending_state_alloc(backend);
//复制pending state到current state
drm_output_state_duplicate(output->state_cur, pending_state,
DRM_OUTPUT_STATE_PRESERVE_PLANES);
//在pending状态的时候,更新所有drm output的状态
ret = drm_pending_state_apply(pending_state);指定了drmvblank的类型为DRM_VBLANK_RELATIVE,设置sequence为当前的vblank计数。
DRM_VBLANK_ABSOLUTE:request.sequence是过去某个时间点以来的 vblank 计数,例如系统启动。
DRM_VBLANK_RELATIVE:request.sequence是当前值的 vblank 计数。例如 1 指定下一个 vblank。该值可以与这些值的任意组合进行按位或运算:
DRM_VBLANK_SECONDARY: 使用第二显示器的 vblank。
DRM_VBLANK_EVENT: 立即返回并触发事件回调而不是等待指定的 vblank。
weston_output_finish_frame
output_repaint_timer_handler函数最后会开启一轮新的repaint定时,repaint从而一直循环下去。repaint_begin创建一个合成器的drm_pending_state repaint_data,每一次repaint都要分配一个新的drm_pending_state给drm使用。
weston_output_repaint使用opengl渲染surface并将framebuffer写入drm设备。repaint_flush应用pending state。
weston_output_finish_frame//计算帧率
->output_repaint_timer_arm//启动repaint定时器
->output_repaint_timer_handler//定时器溢出处理函数,最后再次启动repaint定时器,从而实现repaint循环。
output_repaint_timer_handler
//创建一个合成器的drm_pending_state repaint_data,每一次repaint都要分配一个
//新的drm_pending_state给drm使用。
->repaint_data =compositor->backend->repaint_begin
//数据绘制,渲染完的数据保存在output
->weston_output_maybe_repaint(output, &now, repaint_data)
-->weston_output_repaint(output, repaint_data);
//送显
->compositor->backend->repaint_flush(compositor,
repaint_data);weston_output_repaint
weston_compositor_build_view_list(ec);
if (output->assign_planes && !output->disable_planes) {
//assign planes分配planes
output->assign_planes(output, repaint_data);
} else {
wl_list_for_each(ev, &ec->view_list, link) {
weston_view_move_to_plane(ev, &ec->primary_plane);
}
//计算damage区域
output_accumulate_damage(output);
pixman_region32_init(&output_damage);
pixman_region32_intersect(&output_damage,
&ec->primary_plane.damage, &output->region);
pixman_region32_subtract(&output_damage,
&output_damage, &ec->primary_plane.clip);
//repaint渲染出结果
output->repaint(output, &output_damage, repaint_data);
pixman_region32_fini(&output_damage);
//向client端发送done消息
wl_list_for_each_safe(cb, cnext, &frame_callback_list, link) {
wl_callback_send_done(cb->resource, frame_time_msec);
wl_resource_destroy(cb->resource);
}
drm_assign_planes
drm_pending_state *pending_state = repaint_data;
*primary = &output_base->compositor->primary_plane//primary走GPU渲染
drm_output_propose_state_mode mode = DRM_OUTPUT_PROPOSE_STATE_PLANES_ONLY//默认使用overlay模式
state = drm_output_propose_state(output_base, pending_state, mode);
//为每个output中的view分配对应的plane,并且分配plane对应的合成器,默认是GPU合成。
//如果这里overlay失败,就会尝试使用mix模式;再失败,就是尝试GPU-ONLY的合成模式
weston_view_move_to_plane(ev, primary);//如果没有assign_planes,直接全部交给primary_plane
drm_output_repaint
output->repaint最终指向的是drm_output_render_gl函数,走到gl_renderer_repaint_output这里,我们终于来到了最核心的opengl渲染部分。通过访问drm compositor的drm_fd来访问drm设备。在opengl画完数据后,drm_fb_get_from_bo将fb写入drm设备(最重要的函数)。
drm_output_render(state, damage)
->drm_output_render_gl(state, damage)
//第一步 gl渲染
->gl_renderer_repaint_output
->repaint_views
->draw_view //opengl渲染过程
//第二步 拿到gbm buffer
->bo = gbm_surface_lock_front_buffer(output->gbm_surface);//opengl画好以后从gbm_surface中拿到gbm_buffer,gbm buffer object
//第三步,将buffer写入drm设备。
//************送显最最核心的函数************
//通过gbm_bo拿到drm frame buffer
//ret作为返回值,是drm_fb类型,drm_fb_get_from_bo设置了drm_fb中的drm_fd,以及 buffer的实际数据与大小。
//其中drm_fb_addfb函数通过drm api(drmModeAddFB2WithModifiers,
//drmModeAddFB2,drmModeAddFB)将framebuffer写入进drm设备。
->ret = drm_fb_get_from_bo(bo, b, true, BUFFER_GBM_SURFACE);
//返回给scanout_state,为了后续尝试计算新damage区域,如果失败就是0,那么也就是全图
->ret->gbm_surface = output->gbm_surface;
->drmModeCreatePropertyBlob(b->drm.fd, rects, sizeof(*rects) * n_rects, &scanout_state->damage_blob_id);gl_renderer_repaint_output
gl_renderer_repaint_output中仍然有缩放、旋转操作,设置视图边界的操作。
wl_list_for_each_reverse(view, &compositor->view_list, link) {
if (view->plane == &compositor->primary_plane) {
struct gl_surface_state *gs =
get_surface_state(view->surface);
gs->used_in_output_repaint = false;
}
}
get_surface_state->gl_renderer_create_surface(surface)
->
//将buffer引用和gl surface中的buffer引用关联起来
weston_buffer_reference(&gs->buffer_ref, buffer);
weston_buffer_release_reference(&gs->buffer_release_ref,
es->buffer_release_ref.buffer_release);
if (surface->buffer_ref.buffer) {
//attach到buffer_ref.buffer
//其中gl_renderer_attach_shm将共享缓存中的内容读到surface中,这里涉及大量的gl参数
//有gl_renderer_attach_egl、gl_renderer_attach_dmabuf
gl_renderer_attach(surface, surface->buffer_ref.buffer);
//将buffer_ref.buffer
//刷新damage区域
gl_renderer_flush_damage(surface);
}
//gr->create_sync(gr->egl_display, EGL_SYNC_NATIVE_FENCE_ANDROID,attribs)
//调用EGL的"eglCreateSyncKHR"创建一个sync对象
go->begin_render_sync = create_render_sync(gr);
//渲染damage区域
repaint_views(output, &total_damage);
wl_signal_emit(&output->frame_signal, output_damage);
//
go->end_render_sync = create_render_sync(gr);
//swapSwapBuffers的作用
ret = eglSwapBuffers(gr->egl_display, go->egl_surface);
//在swap buffer之后必须提交render sync 对象,只有在flush之后, render sync
//对象才真正拥有一个有效的sync file fd
timeline_submit_render_sync(gr, output, go->begin_render_sync,
TIMELINE_RENDER_POINT_TYPE_BEGIN);
timeline_submit_render_sync(gr, output, go->end_render_sync,
TIMELINE_RENDER_POINT_TYPE_END);
update_buffer_release_fences(compositor, output);
gl_renderer_garbage_collect_programs(gr);repaint_views
static void
repaint_views(struct weston_output *output, pixman_region32_t *damage)
{
struct weston_compositor *compositor = output->compositor;
struct weston_view *view;
wl_list_for_each_reverse(view, &compositor->view_list, link)
if (view->plane == &compositor->primary_plane)
//!
draw_view(view, output, damage);
->ensure_surface_buffer_is_ready//等待EGLSyncKHR object
->attribs[1] = dup(surface->acquire_fence_fd);//复制文件描述符
->sync = gr->create_sync(gr->egl_display,
EGL_SYNC_NATIVE_FENCE_ANDROID,
attribs);//根据复制的fd创建sync对象
->wait_ret = gr->wait_sync(gr->egl_display, sync, 0);//阻塞等待egl完成fence
->destroy_ret = gr->destroy_sync(gr->egl_display, sync);//完成后摧毁sync对象
->gl_shader_config_init_for_view//配置输入纹理的着色器,surface的旋转矩阵、边缘滤波器种类(linear/nearest)
//blend之后,opengl进行渲染
-> if (pixman_region32_not_empty(&surface_blend)) {
glEnable(GL_BLEND);
//GL渲染
repaint_region(gr, ev, &repaint, &surface_blend, &sconf);
gs->used_in_output_repaint = true;
}
}实际渲染过程repaint_region,使能顶点着色器/片段着色器,打开shader program,glDrawArrays绘制三角形(一个四边形,由两个三角形组成,六个顶点数据)。
drm_repaint_flush
应用pending buffer
drm_pending_state_apply
->drm_pending_state_apply_atomic
->drm_output_apply_state_atomic//注意是以plane_list遍历
->drmModeAtomicCommit //这个就是commit,没什么好讲的;将pending state切到current后,终于完成了渲染显示整个流程。
drm_output_enable
drm函数的初始化过程。
static int
drm_output_enable(struct weston_output *base)
{
struct drm_output *output = to_drm_output(base);
struct drm_backend *b = to_drm_backend(base->compositor);
int ret;
assert(!output->virtual);
ret = drm_output_attach_crtc(output);
if (ret < 0)
return -1;
ret = drm_output_init_planes(output);
if (ret < 0)
goto err_crtc;
if (drm_output_init_gamma_size(output) < 0)
goto err_planes;
if (b->pageflip_timeout)
drm_output_pageflip_timer_create(output);
if (b->use_pixman) {
if (drm_output_init_pixman(output, b) < 0) {
weston_log("Failed to init output pixman state\n");
goto err_planes;
}
} else if (drm_output_init_egl(output, b) < 0) {
weston_log("Failed to init output gl state\n");
goto err_planes;
}
drm_output_init_backlight(output);
output->base.start_repaint_loop = drm_output_start_repaint_loop;
output->base.repaint = drm_output_repaint;
output->base.assign_planes = drm_assign_planes;
output->base.set_dpms = drm_set_dpms;
output->base.switch_mode = drm_output_switch_mode;
output->base.set_gamma = drm_output_set_gamma;
weston_log("Output %s (crtc %d) video modes:\n",
output->base.name, output->crtc->crtc_id);
drm_output_print_modes(output);
return 0;
err_planes:
drm_output_deinit_planes(output);
err_crtc:
drm_output_detach_crtc(output);
return -1;
}
















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









