







 Spark作为大数据处理引擎,提供SQL and DataFrames、Spark Streaming、MLlib和GraphX四大核心库。SQL and DataFrames支持结构化数据处理,集成Hive并提供统一的数据源访问。Spark Streaming简化容错流式应用,MLlib是机器学习库,易用且高性能。GraphX则专注于图形处理,具备灵活性和高速度。
Spark作为大数据处理引擎,提供SQL and DataFrames、Spark Streaming、MLlib和GraphX四大核心库。SQL and DataFrames支持结构化数据处理,集成Hive并提供统一的数据源访问。Spark Streaming简化容错流式应用,MLlib是机器学习库,易用且高性能。GraphX则专注于图形处理,具备灵活性和高速度。
Spark是大数据处理的引擎,提供了4种数据处理的库,还有很多第三方的库。本篇文章仅简单列举Spark的几种库及其特点。
SQL and DataFrames
sql和数据帧,此模块支持结构化数据的处理。
- 将Spark程序与sql查询无缝集成
在Spark程序中可以使用SQL或者DataFrame API进行结构化数据查询,支持在Java,Scala,Python,R语言中使用。
如:
results = spark.sql("SELECT * FROM people")
names = results.map(lambda p: p.name)
- 统一化数据访问
SQL和DataFrames提供了统一的方式连接多种数据源,包括:Hive,Avro,Parquet,ORC,Json,JDBC。甚至可以跨数据源进行数据的join操作。
如:
spark.read.json("s3n://...")
.registerTempTable("json")
results = spark.sql(
"""SELECT *
FROM people
JOIN json ...""")
- 集成Hive
支持HiveQL,Hive SerDes,Hive UDFs,用来访问 Hive的各类仓库。
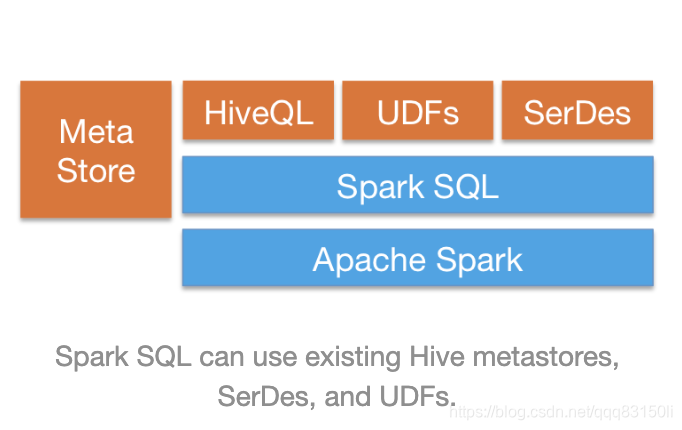
- 标准化连接
支持JDBC或ODBC连接。

Spark Streaming
spark 流,此模块简化了大规模的容错的流式应用的构建。
- 易用
Spark流将流式处理集成到了Spark的语言API中,使得编写一个流式任务和写一个批处理任务相同,支持Java,Scala,Python语言。 - 容错
Spark流的操作可以从丢失的工作和操作状态中自动恢复,不需要写额外的代码。 - 集成
流可以和批处理,交互式查询结合起来使用。
MLlib
machine learning 机器学习库
- 易用
在Java,Scala,Python,R语言中可用。 - 高性能
高质量的算法,比MapReduce快100多倍 - 跨平台
可以以独立集群模式运行,或在EC2,Hadoop Yarn,Mesos,Kubernetes上运行。访问HDFS,Cassandra,HBase,Hive等很多其余数据源的数据。
GraphX
图形处理,图形的并行计算。
- 灵活性
使用图形和集合进行无缝工作。 - 速度快
性能堪比专业图形处理系统。 - 算法
不断增长的图形算法库

















 874
874

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









