



1、springboot配置启动或者java spi机制加载加载
spring.datasource.driver-class-name=org.apache.shardingsphere.driver.ShardingSphereDriver
ShardingSphereDriver connect连接时
acceptsURL判断链接字符串开头:url.startsWith("jdbc:shardingsphere:");
private final DriverDataSourceCache dataSourceCache = new DriverDataSourceCache();
@Overridepublic Connection connect(final String url, final Properties info) throws SQLException {
return acceptsURL(url) ? dataSourceCache.get(url).getConnection() : null;
}
2、org.apache.shardingsphere.driver.jdbc.core.driver.DriverDataSourceCache#get
调用get方法时createDataSource 创建ShardingSphereDataSource
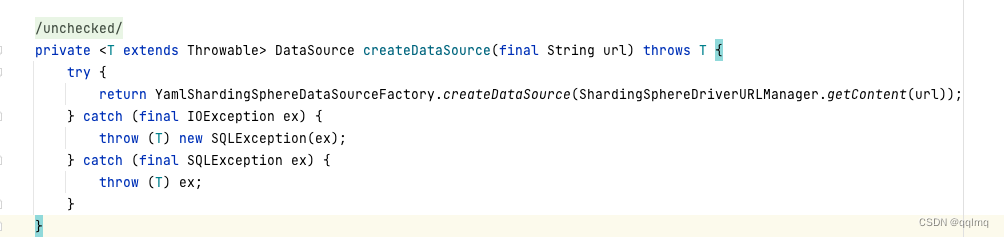
YamlShardingSphereDataSourceFactory.createDataSource(ShardingSphereDriverURLManager.getContent(url)); #加载配置文件创建ShardingSphereDataSource
3.创建上下文管理(ContextManagerBuilder)在启动流程创建数据源时:
org.apache.shardingsphere.driver.jdbc.core.datasource.ShardingSphereDataSource#createContextManager
return TypedSPILoader.getService(ContextManagerBuilder.class, null == modeConfig ? null : modeConfig.getType()).build(param);
4、上下文管理器管理上下文元数据metaDataContexts和当前上下文实例

MetaDataContexts metaDataContexts = MetaDataContextsFactory.create(persistService, param, instanceContext);
ContextManager result = new ContextManager(metaDataContexts, instanceContext);
5、上下文元数据metaDataContexts
org.apache.shardingsphere.mode.metadata.MetaDataContextsFactory#create
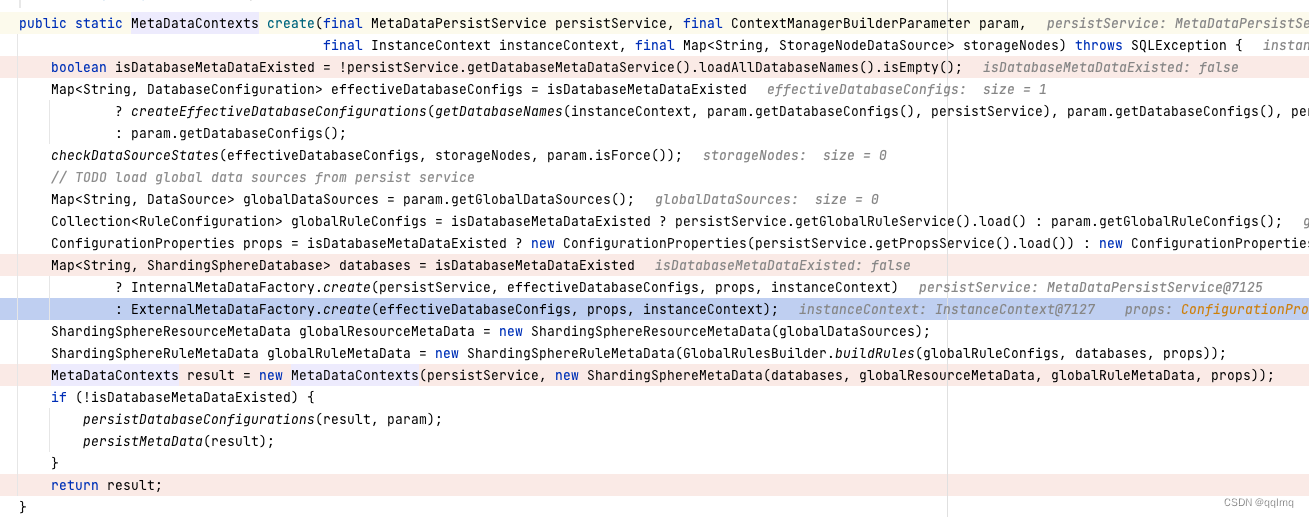
上下文元数据metaDataContexts 封装了persistService元数据持久化服务,分片元数据ShardingSphereMetaData
MapString, ShardingSphereDatabase> databases -> ExternalMetaDataFactory.create(effectiveDatabaseConfigs, props, instanceContext);
6、创建分片元数据org.apache.shardingsphere.infra.metadata.database.ShardingSphereDatabase#create
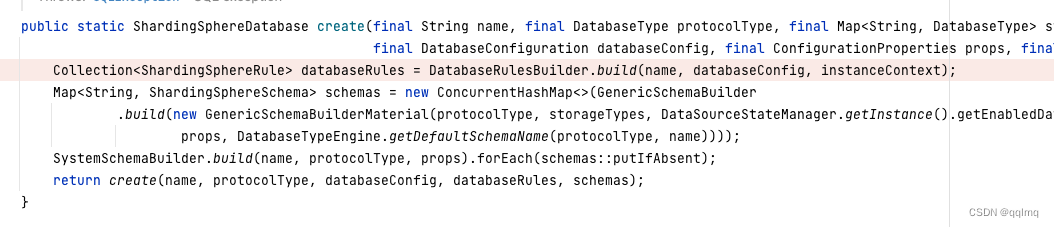
这里创建数据库规则:CollectionShardingSphereRule> databaseRules = DatabaseRulesBuilder.build(name, databaseConfig, instanceContext);
创建ShardingSphereSchema,这是第7步拦截的内容;
7、分片元数据org.apache.shardingsphere.infra.metadata.ShardingSphereMetaData

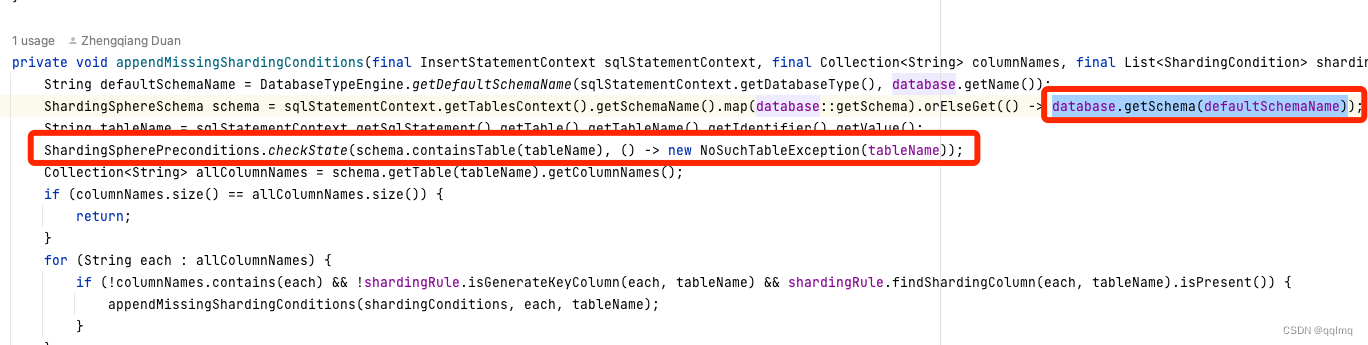
属性databases 保存了第6步创建的分片数据库元数据ShardingSphereDatabase, 在执行SQL时,路由引擎
org.apache.shardingsphere.sharding.route.engine.condition.engine.InsertClauseShardingConditionEngine#appendMissingShardingConditions
会拦截不存在于这个变量的SQL操作
8、解释数据库构造材料
配置是否按规则创建所有材料,
org.apache.shardingsphere.infra.metadata.database.schema.util.SchemaMetaDataUtils#getSchemaMetaDataLoaderMaterials
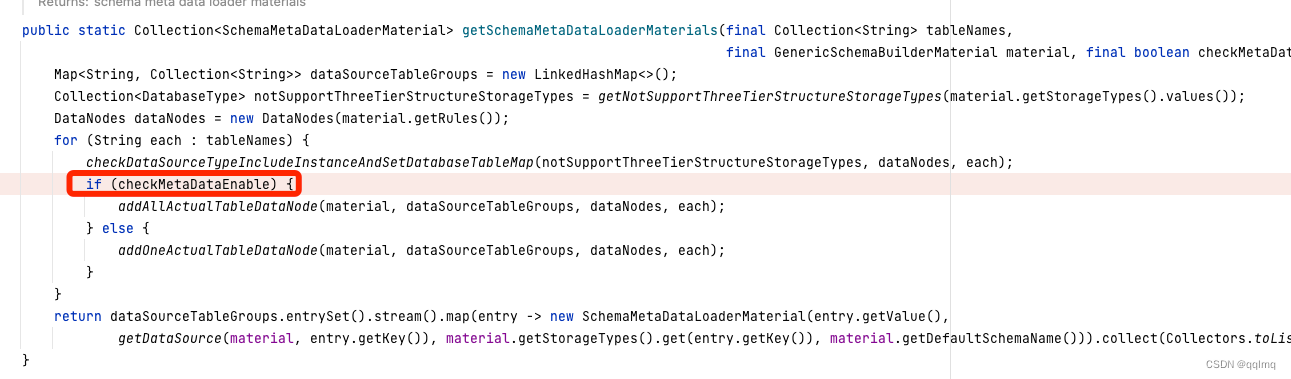
checkMetaDataEnable 为true则会自动根据规则创建所有表的元数据,比如年月日的规则2017..2200,如果没有启动,会报表无法找到,因为只会创建规则的第一个表2017.除非库表中真实创建了2017,刚好是第一个能加载到表结构的
配置
props:
check-table-metadata-enabled: true
9、根据数据库材料创建数据库元数据
org.apache.shardingsphere.infra.metadata.database.schema.loader.metadata.SchemaMetaDataLoaderEngine#load

dialectSchemaMetaDataLoader.get().load(material.getDataSource(), material.getActualTableNames(), material.getDefaultSchemaName()); #根据spi得到数据库言语元数据加载器,
实际会连接数据库,请求每个元数据材料中的表schema,得到所有数据库中存在的表结果,返回封装的表结构元数据Map
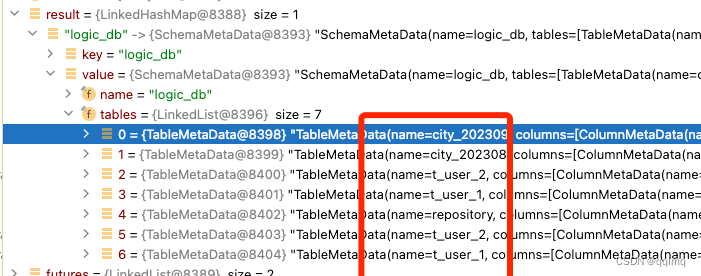
material.getActualTableNames(),这里得到按规则创建的所有分片表名t_user_202307,t_user_202308....
10、根据数据库元数据,创建数据库分片元数据
org.apache.shardingsphere.infra.metadata.database.schema.builder.GenericSchemaBuilder#revise -》

org.apache.shardingsphere.infra.metadata.database.schema.reviser.MetaDataReviseEngine#revise

org.apache.shardingsphere.infra.metadata.database.schema.reviser.schema.SchemaMetaDataReviseEngine#revise
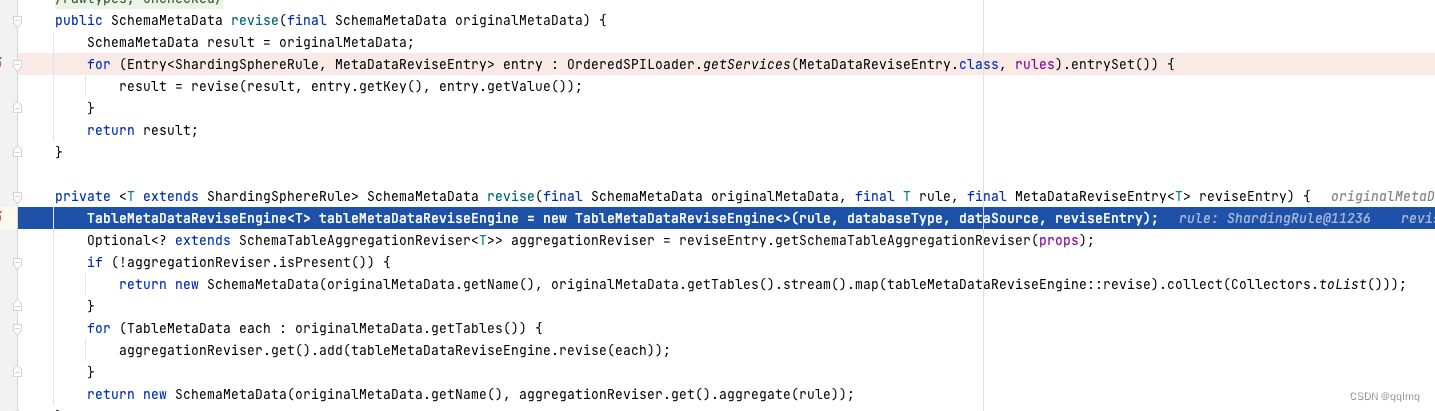
最后还是spi加载转换类,按规则再把数据库结果精减:
aggregationReviser.get().add(tableMetaDataReviseEngine.revise(each));
org.apache.shardingsphere.infra.metadata.database.schema.reviser.table.TableMetaDataReviseEngine#revise

精减的目的是把所有数据库在存在的相同规则分片的表融合,比如t_user_202307,t_user_202308, ->t_user;
org.apache.shardingsphere.sharding.metadata.reviser.table.ShardingTableNameReviser#revise

最结得到这样的表结构元数据

11、把数据库结构元数据转换成分片结构元数据
org.apache.shardingsphere.infra.metadata.database.schema.builder.GenericSchemaBuilder#revise

12、到此整个流程要准备的东西就是元数据上下文metaDataContexts,封装了分片元数据ShardingSphereMetaData,而它又封装了数据库ShardingSphereDatabase database(第7步),
ShardingSphereDatabase封装,加载数据库结构、数据库表结果....
13、使用:sql拦截
org.apache.shardingsphere.driver.jdbc.core.statement.ShardingSphereStatement
构造方法得到元数据上下文等数据

拦截SQL执行,然后就是SQL解释、路由、重造

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









