



PySpark 开发环境搭建指南
一、 前言
随着数据量的爆炸式增长,高效处理和分析大数据的能力已成为当今技术领域的核心竞争力之一。Apache Spark 作为业界领先的统一分析引擎,凭借其强大的内存计算能力和对多种数据处理场景(包括批处理、流处理、机器学习和图计算)的卓越支持,在众多分布式计算框架中脱颖而出。为了让广大的 Python 开发者能够便捷地利用 Spark 的威力,社区推出了 PySpark——Apache Spark 的官方 Python API。PySpark 允许我们使用简洁、易读的 Python 语言及其丰富的库生态,来驾驭 Spark 强大的分布式计算核心,从而优雅地应对海量数据的处理与分析挑战,无论是进行大规模数据清洗、转换,还是执行复杂的机器学习任务。学习和掌握 PySpark,对于希望进入大数据领域或提升数据处理能力的开发者来说,无疑具有重要意义。
然而,“工欲善其事,必先利其器”。要想顺利地踏上 PySpark 的学习之旅或在实际项目中高效应用,搭建一个稳定、可靠且配置得当的本地开发环境是至关重要的第一步。一个混乱或配置不当的环境,常常会引发恼人的版本冲突、依赖缺失或网络连接问题,不仅会无谓地消耗宝贵的排错时间,更可能在起步阶段就打击学习者的信心和探索热情。
考虑到这一点,本文旨在为广大 PySpark 学习者和开发者,特别是国内用户,提供一种清晰、高效且易于遵循的环境搭建方案。我们将重点介绍如何利用强大的 Python 发行版及环境管理工具 Anaconda(或其轻量级版本 Miniconda)来创建和管理独立的 PySpark 开发环境,并通过配置清华大学开源软件镜像站(清华源)来有效解决在国内直接下载依赖包时可能遇到的网络速度慢或连接不稳定的问题。本文将一步步引导您完成必要的安装与配置,助您快速构建一个稳定、隔离且易于管理的 PySpark 本地开发环境,为后续的学习、实验和项目开发奠定坚实的基础,让您可以更专注于 PySpark 本身的应用与探索。
二、 环境准备:Anaconda/Miniconda 安装
1. 选择与下载:
- 推荐使用 Anaconda 或 Miniconda 来管理 Python 环境和包。Miniconda 更轻量,如果硬盘空间有限或只想安装必要的包,可以选择它。
- 为了提高下载速度,我们可以使用清华大学开源软件镜像站。
- 访问清华源网站 (
https://mirrors.tuna.tsinghua.edu.cn/)。 - 找到 Anaconda 镜像,选择下载适合你 Windows 系统的 Anaconda 或 Miniconda 安装包(比如
Miniconda3-py312_25.1.1-1-Windows-x86_64.exe或Anaconda3-2024.10-1-Windows-x86_64.exe)。
2. 安装:
- 运行下载好的安装包,按照提示进行安装。
三、 配置国内镜像源(清华源)
为了后续安装包更快,我们需要配置 Conda 和 Pip 使用国内镜像源。
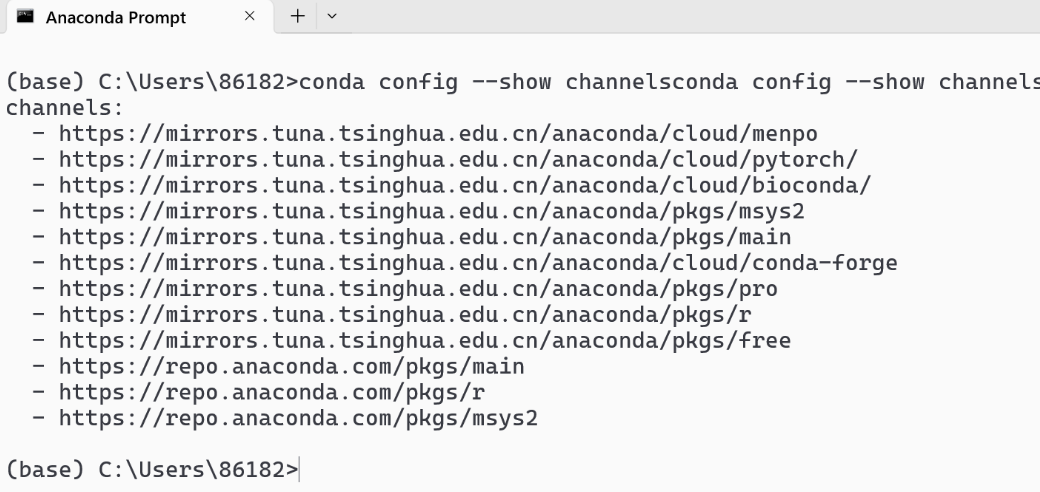
1. 配置 Conda 清华源:
- 打开 Anaconda Prompt (或者你安装 Miniconda 后的终端)。
- 执行以下命令添加清华源:
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/pro conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge conda config --set show_channel_urls yes
2. 配置 Pip 清华源:
-
(设置全局 Pip 镜像 - 推荐)
为了让pip默认就使用清华源,我们可以设置全局配置。这样以后安装包就不用每次都手动加-i https://pypi.tuna.tsinghua.edu.cn/simple了。操作步骤如下:-
找到或创建配置文件:
- 在 Windows 文件资源管理器的地址栏输入
%APPDATA%然后按回车,会打开类似C:\Users\你的用户名\AppData\Roaming的文件夹。 - 在这个文件夹里,检查有没有一个叫做
pip的文件夹。如果没有,就新建一个名为pip的文件夹。 - 进入
pip文件夹,检查里面有没有一个叫做pip.ini的文件。如果没有,就新建一个文本文档,然后把它重命名为pip.ini(确保文件扩展名是.ini而不是.txt)。
- 在 Windows 文件资源管理器的地址栏输入
-
编辑
pip.ini文件:-
用记事本或其他文本编辑器打开
pip.ini文件。 -
将以下内容复制粘贴进去:
[global] index-url = [https://pypi.tuna.tsinghua.edu.cn/simple](https://pypi.tuna.tsinghua.edu.cn/simple) trusted-host = pypi.tuna.tsinghua.edu.cn -
index-url指定了默认的下载源为清华源。 -
trusted-host是为了让 pip 信任这个源,特别是在网络环境复杂或使用 https 时建议加上。
-
-
保存并验证:
- 保存并关闭
pip.ini文件。 - 之后,你在任何项目(或基础环境)中使用
pip install 包名时,它都会默认从清华源下载,速度会快很多。你可以尝试安装一个小包(比如pip install requests)来测试一下速度,或者使用pip config list命令查看当前配置是否生效。
- 保存并关闭
-
四、 创建独立的 PySpark Conda 环境
为 PySpark 创建一个独立的环境是个好习惯,可以避免包版本冲突。
1. 创建环境 (以 Python 3.8 为例,你可以选择其他版本):
conda create --name mypyspark python=3.8
2. 激活环境:
conda activate mypyspark
- 激活后,命令行前面会出现 (mypyspark) 标识。
五、安装PySpark
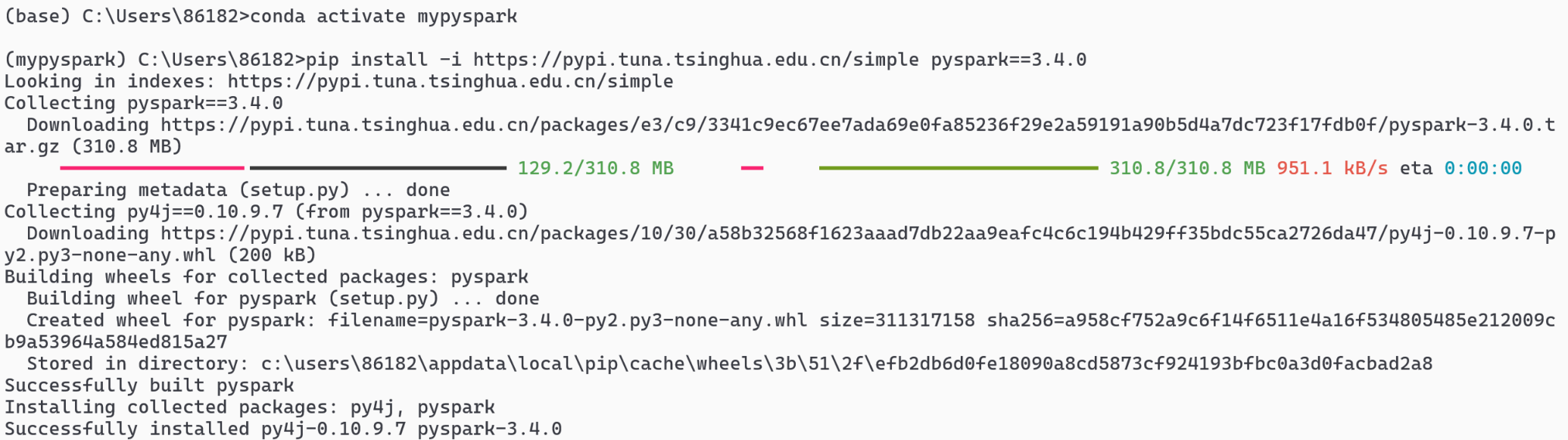
1.使用pip安装
- 确保你已经激活了
mypyspark环境。 - 执行安装命令(指定一个稳定版本,例如 3.4.0,或者你可以选择最新版),使用清华源加速:
pip install pyspark==3.4.0 -i [https://pypi.tuna.tsinghua.edu.cn/simple](https://pypi.tuna.tsinghua.edu.cn/simple)
- 虽然
pip install pyspark通常会处理好,但如果遇到问题,可能需要检查 JDK 是否正确安装和配置了JAVA_HOME。
六、 在 PyCharm 中配置和测试 PySpark
1. 创建 PyCharm 项目:
- 打开 PyCharm,创建一个新项目。
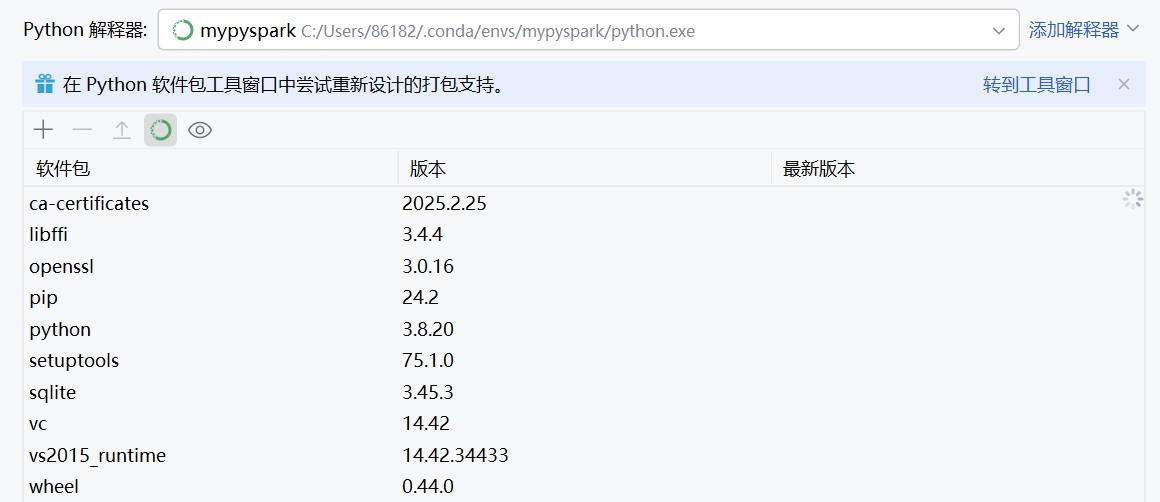
- 配置项目解释器:选择 “Existing interpreter”,然后找到你刚刚创建的
mypysparkConda 环境的 Python 解释器。路径类似C:\Users\你的用户名\.conda\envs\mypyspark\python.exe。
2. 编写测试代码:
- 在项目中创建一个 Python 文件(例如
main.py)。 - 将 示例代码粘贴进去。注意修改
os.environ['PYSPARK_PYTHON']中的路径为你自己环境中python.exe的实际路径。
from pyspark import SparkConf, SparkContext
import os
# 确保这里的路径是你环境中 python.exe 的实际路径!
# 示例路径,需要修改为你自己的:
os.environ['PYSPARK_PYTHON'] = 'C:\\Users\\dell\\.conda\\envs\\mypyspark\\python.exe'
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:\\Users\\86182\\.conda\\envs\\mypyspark\\python.exe'
# 如果你的 Spark 不是安装在默认位置,可能还需要设置 SPARK_HOME
# os.environ['SPARK_HOME'] = '/path/to/your/spark'
# 通常 pip install pyspark 后不需要手动设置 SPARK_HOME
conf = SparkConf().setAppName("WordCount").setMaster("local[2]") # 使用本地模式,2个核心
sc = SparkContext(conf=conf)
print(sc.version) # 打印版本号
print(cwd) # 获取当前工作目录并构建文件路径
# Windows 路径需要转义或使用原始字符串,并确保 file URI 格式正确
# 使用 os.path.join 生成路径,然后替换反斜杠
txt_file_path = os.path.join(cwd, "words.txt")
file_uri = "file:///" + txt_file_path.replace("\\", "/")
print(f"Reading file from: {file_uri}")
# 执行 WordCount
file = "file:///" + cwd + "/words.txt"
print(sc.textFile(file).
flatMap(lambda x: x.split(" ")).
map(lambda x: (x, 1)).
reduceByKey(lambda x, y: x + y).
collect())
- 在项目根目录下创建一个
words.txt文件,随便写点英文单词,用空格隔开。
3. 运行与结果:

- 运行
main.py。 - 如果一切顺利,控制台会输出 PySpark 的版本号和词频统计结果。
七、 总结
到这里,我们已经一步步地在 Windows 系统上,借助 Anaconda/Miniconda 搭建起了一个干净、独立的 PySpark 开发环境。回顾一下主要步骤:
- 安装 Anaconda/Miniconda: 作为强大的 Python 环境和包管理器。
- 配置清华镜像源: 大幅提升国内下载
conda和pip包的速度。 - 创建并激活独立环境 (
mypyspark): 这是管理项目依赖、避免版本冲突的好习惯,非常重要哦! - 安装 PySpark 包: 在独立环境中安装核心的 PySpark 库。
- PyCharm 配置与测试: 通过一个简单的 WordCount 例子验证了环境搭建成功。
希望这篇详细的步骤能帮助你(以及其他需要的小伙伴)顺利开启 PySpark 的学习和开发之旅。一个好的开端是成功的一半嘛!拥有一个稳定可靠的环境,接下来就可以更专注于 PySpark 本身强大的数据处理能力了。
动手试试看吧! 如果你在搭建过程中遇到了任何问题,或者有什么更好的建议和技巧,都非常欢迎在下面的评论区留言讨论。大家一起交流,共同进步!


















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









