






目录
前言
这是零声学院Linux入门环境编程的第二个项目,原本是统计文件单词数量作为例题,统计每个单词出现的次数作为课后作业。其中统计文件单词数量是用有限状态机来实现的,原理比较简单,且我认为源码存在一定缺陷,因此不介绍状态机的方法。下面我直接推倒重来,将两个问题合并起来解决。
一、完整代码展示
代码如下:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <ctype.h>
#define MAX_WORDS 1000 // 最大单词数
#define MAX_WORD_LEN 100 // 每个单词的最大长度
// 定义一个结构体用于存储单词及其出现次数
typedef struct {
char word[MAX_WORD_LEN];
int count;
} WordCount;
int is_word_char(char c) {
return isalpha(c) || c == '-' || c == '\''; // 判断是否是字母、连字符或撇号
}
int is_valid_hyphen_or_apostrophe(char *word, int pos, char c) {
// 处理连字符和撇号不能在单词开头或结尾,且不能连续出现
if ((c == '-' || c == '\'') && (pos == 0 || !isalpha(word[pos - 1]))) {
return 0; // 连字符或撇号在开头或者前面不是字母则无效
}
return 1;
}
void count_words(char *filename) {
WordCount words[MAX_WORDS]; // 存储单词及其出现次数
int word_count = 0; // 当前已存储的单词数
int total_word_count = 0; // 总单词数
FILE *fp = fopen(filename, "r");
if (fp == NULL) {
perror("Failed to open file");
return;
}
char word[MAX_WORD_LEN];
char c;
int pos = 0;
while ((c = fgetc(fp)) != EOF) {
if (is_word_char(c)) {
if (is_valid_hyphen_or_apostrophe(word, pos, c)) {
word[pos++] = tolower(c); // 构建单词,允许合法的连字符或撇号
}
} else if (pos > 0) {
word[pos] = '\0'; // 终止当前单词
pos = 0;
// 查找单词是否已经存在
int index = -1;
for (int i = 0; i < word_count; i++) {
if (strcmp(words[i].word, word) == 0) {
index = i;
break;
}
}
if (index != -1) {
words[index].count++; // 如果单词已存在,增加计数
} else {
// 如果单词不存在,添加到数组中
strcpy(words[word_count].word, word);
words[word_count].count = 1;
word_count++;
}
total_word_count++; // 增加总单词计数
if (word_count >= MAX_WORDS) {
printf("Too many words!\n");
break;
}
}
}
fclose(fp);
// 输出每个单词及其出现次数
for (int i = 0; i < word_count; i++) {
printf("%s: %d\n", words[i].word, words[i].count);
}
// 输出总单词数
printf("Total word count: %d\n", total_word_count);
}
int main(int argc, char *argv[]) {
if (argc < 2) {
printf("Usage: %s <filename>\n", argv[0]);
return -1;
}
count_words(argv[1]);
return 0;
}
二、代码解释
这段代码的功能是读取指定的文本文件,统计每个单词出现的次数,并输出总单词数和每个单词的出现次数。代码主要分为以下几个部分:
1.结构体定义与基本设置
#define MAX_WORDS 1000
#define MAX_WORD_LEN 100
typedef struct {
char word[MAX_WORD_LEN];
int count;
} WordCount;MAX_WORDS:定义了最多可以处理 1000 个不同的单词。MAX_WORD_LEN:单词的最大长度为 100 个字符。WordCount结构体用来保存每个单词及其出现的次数。
2.辅助函数


3.核心处理逻辑
3.1 count_words()
这个函数是代码的核心,负责文件读取和单词统计。
void count_words(char *filename) {
WordCount words[MAX_WORDS];
int word_count = 0;
int total_word_count = 0;FILE *fp = fopen(filename, "r");
if (fp == NULL) {
perror("Failed to open file");
return;
}char word[MAX_WORD_LEN];
char c;
int pos = 0;while ((c = fgetc(fp)) != EOF) {
if (is_word_char(c)) {
if (is_valid_hyphen_or_apostrophe(word, pos, c)) {
word[pos++] = tolower(c);
}
} else if (pos > 0) {
word[pos] = '\0'; // 单词结束
pos = 0;
// 查找单词是否已经存在
int index = -1;
for (int i = 0; i < word_count; i++) {
if (strcmp(words[i].word, word) == 0) {
index = i;
break;
}
}if (index != -1) {
words[index].count++; // 如果单词已存在,增加计数
} else {
strcpy(words[word_count].word, word); // 新单词
words[word_count].count = 1;
word_count++;
}total_word_count++;
if (word_count >= MAX_WORDS) {
printf("Too many words!\n");
break;
}
}
}fclose(fp);
// 输出每个单词及其出现次数
for (int i = 0; i < word_count; i++) {
printf("%s: %d\n", words[i].word, words[i].count);
}// 输出总单词数
printf("Total word count: %d\n", total_word_count);
}

3.2 main() 函数
int main(int argc, char *argv[]) {
if (argc < 2) {
printf("Usage: %s <filename>\n", argv[0]);
return -1;
}count_words(argv[1]);
return 0;
}
- 该函数检查命令行参数是否包含文件名,如果没有文件名作为参数,输出用法说明并返回错误。如果有文件名,则调用
count_words函数对文件进行处理。
三、实际运行结果展示
1.输入文件c.txt的内容
hello world it's mother-in-law John's cat. For exa-
mple, to report an error in datagram processing.
example it is in law.
2.运行结果
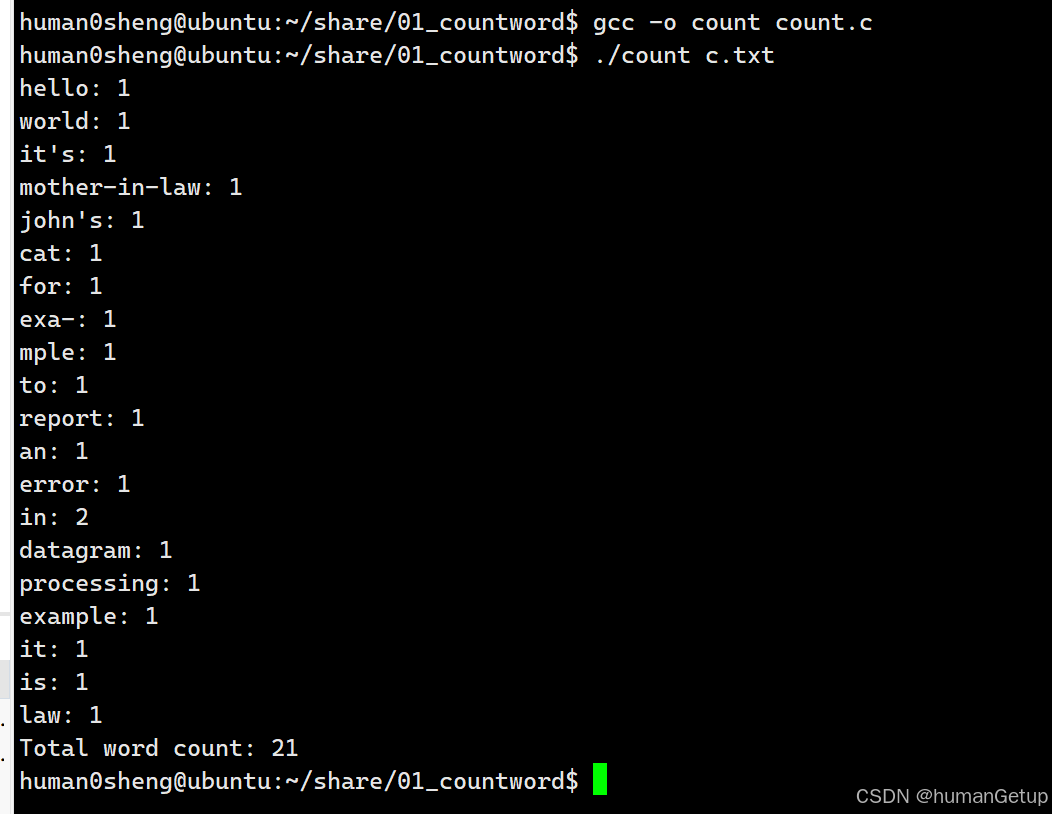
3.运行结果分析&可以改进的地方
代码在大部分情况下可以正确识别文件中的单词并完成统计,但存在以下问题。
- 连字符处理需要增强:目前连字符的处理仅允许它出现在单词内部,如果连字符出现在行尾,并且应该连接下一行的单词,则会出现错误,如上图展示的exa-,mple。
- 's被视为前一个单词的一部分:这导致统计并不完全准确,'s和is没有被当做同一个单词处理
总结
- 这段代码跳出了状态机的解法,借用链表来记录和存储各个单词出现的次数,以及统计所有单词的数量,并且输出。避开了状态机方法中对if()内条件的穷举——这是一个重大的缺陷,除非预设输入的文本除了字母以外其他字符的种类很少,不然很容易出现遗漏。
- 这段代码不能分辨's和换行用连字符连接起来的单词,但除此之外功能是比较完整的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









