







机器学习,顾名思义,机器具备有学习的能力。具体来讲,机器学习就是让机器具备找一个函数的能力。随着要找的函数不同,机器学习有不同的类别:
- 回归(输出是一个数值,一个标量)
- 分类(输出是从设定好的选项里面选择一个当作输出)结构化学习(机器不只是要做选择题或输出一个数字,而是产生一个有结构的物体,比如让机器画一张图,写一篇文章)
1.1 案例学习

机器学习找函数的过程分为三个步骤:
1、写出一个带有未知参数的函数f
比如将函数写成,
是准备要预测的东西,
和
是未知的参数,
称为偏置(bias),
称为权重(weight),特征
是函数里面已知的变量。我们将带有未知的参数(parameter)的函数称为模型(model)。
2、定义损失(loss)
损失也是一个函数,这个函数的输入是模型里面的参数,由上可知模型为,由于
和
是未知的,所以损失函数是
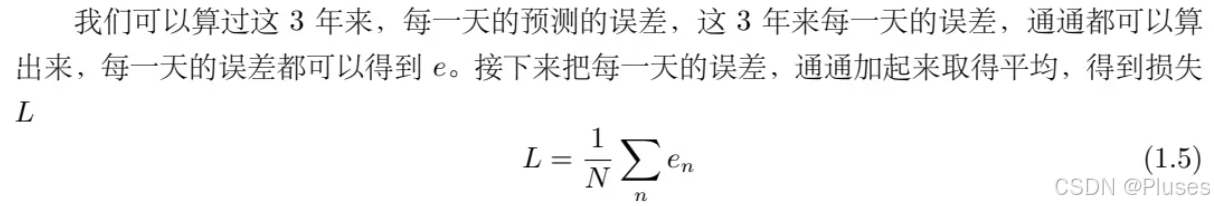
其中,代表训验数据的个数,即 3 年来的训练数据,就 365 乘以 3,计算出一个
,
是每一笔训练数据的误差
相加以后的结果。
越大,代表现在这一组参数越不好,
越小,代表现在这一组参数越好。
估测的值其实和实际的值之间的差距其实有不同的算法:
- 平均绝对误差(Mean Absolute Error,MAE)公式为:
;
- 均方误差(Mean SquaredError,MSE)公式为:
;
- 有一些任务中
和
都是概率分布,这个时候可能会选择交叉熵(cross entropy)
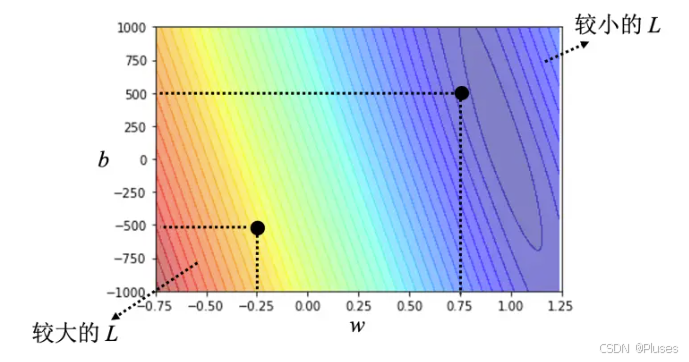
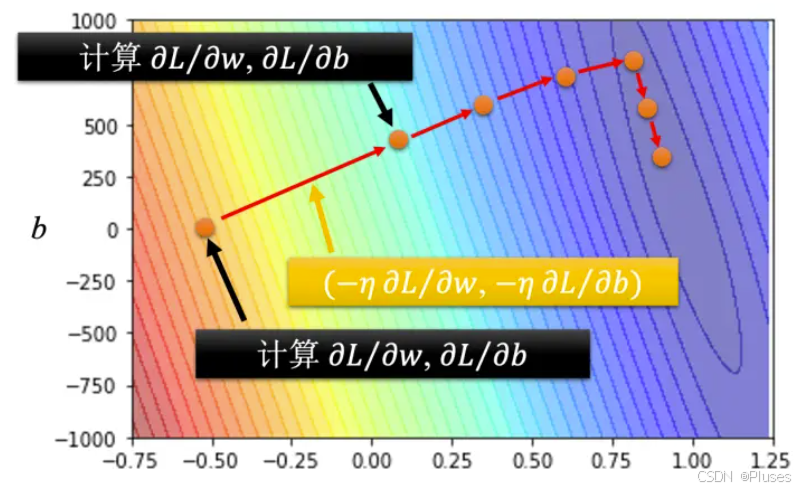
也可以画出等高线图,越偏红色系,代表计算出来的损失越大;如果越偏蓝色系,就代表损失越小,尝试不同的参数计算损失画出来的等高线图称为误差表面(error surface)
3、解一个最优化的问题
找到使得损失最小的参数
和
,代表他们是最优的一组,通常优化采用梯度下降(gradient descent)的方法,以一个参数变化为例先进行解释。
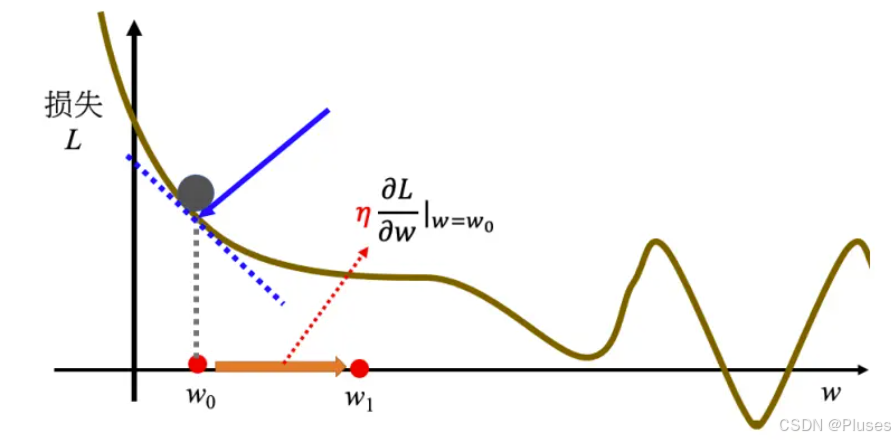
首先要随机选取一个初始的点。
接下来计算,在
等于
的时候,参数
对损失的微分。计算在这一个点,在
这个位置的误差表面的切线斜率,也就是这一条蓝色的虚线它的斜率。
- 如果这一条虚线的斜率是负的,代表说左边比较高,右边比较低,就把
的值变大,就可以让损失变小;
- 如果算出来的斜率是正的,就代表左边比较低,右边比较高,就代表把
其中,变化的大小取决于两个事情:
- 这个点的斜率,斜率越大
- 学习率(learning rate)
也会对其产生影响。学习率是自己设定的,如果

把往右移一步,新的位置为
,这一步的步伐是
乘上微分的结果,即:
接下来反复进行刚才的操作,计算一下微分的结果,再决定现在要把
移动多少,再移动到
,再继续反复做同样的操作,不断地移动
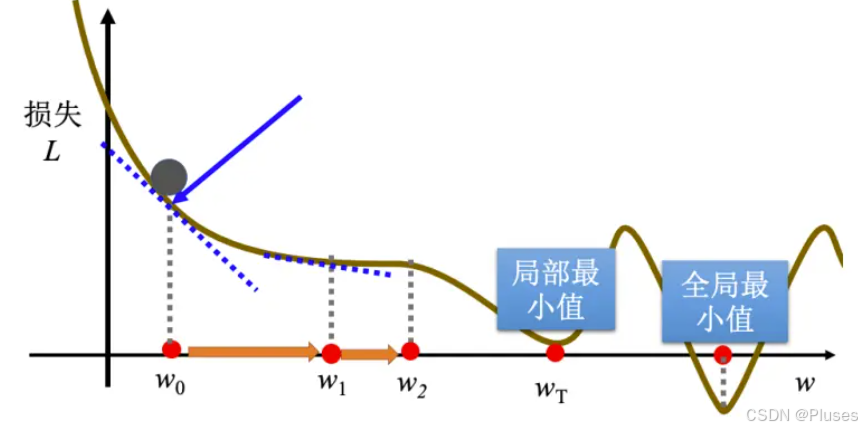
的位置,最后会有两种情况停下来:
- 一种情况是最开始将更新次数设定成了超参数
- 还有另外一种理想上的,当不断调整参数,调整到一个地方,它的微分的值就是这一项,算出来正好是 0 的时候,如果这一项正好算出来是 0,0 乘上学习率
更新到
,再更新到
,最后更新到
有点卡,
梯度下降法会有一个问题,可能走到时,训练就停止了,但是
只是一个局部最小值(local minima),其左右两边都比这个地方的损失还要高一点,但是它不是整个误差表面上面的最低点,即
这个点还不是全局最小值(global minima)
将梯度下降的方法推广到两个参数变化:
假设有两个参数,随机初始值为,
。要计算
,
跟损失的微分,计算在
的位置,
的位置,要计算
对
的微分,计算
对
的微分:
,
计算完后更新跟
,把
减掉学习率乘上微分的结果得到
,把
减掉学习率乘上微分的结果得到
:
,
1.2 线性模型
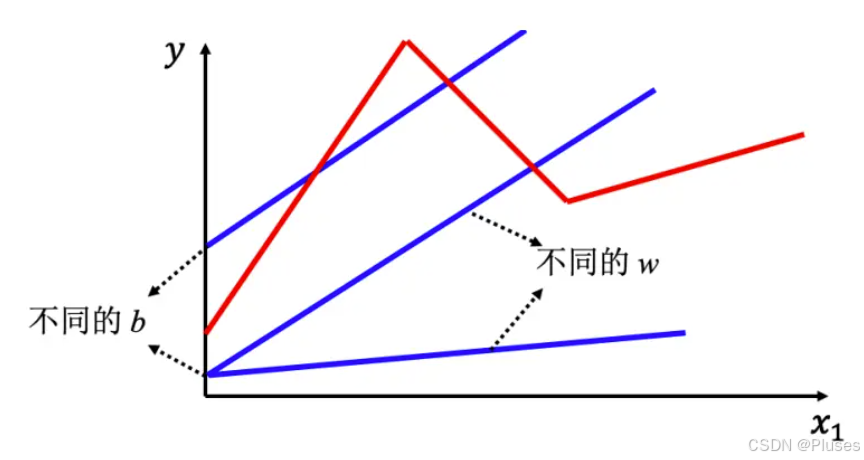
把输入的特征 x 乘上一个权重,再加上一个偏置就得到预测的结果,这样的模型称为线性模型(linear model)
1、分段线性曲线
线性模型有很大的限制,这种来自于模型的限制称为模型的偏差,无法模拟真实的情况。所以需要写一个更复杂的、更有灵活性的、有未知参数的函数。
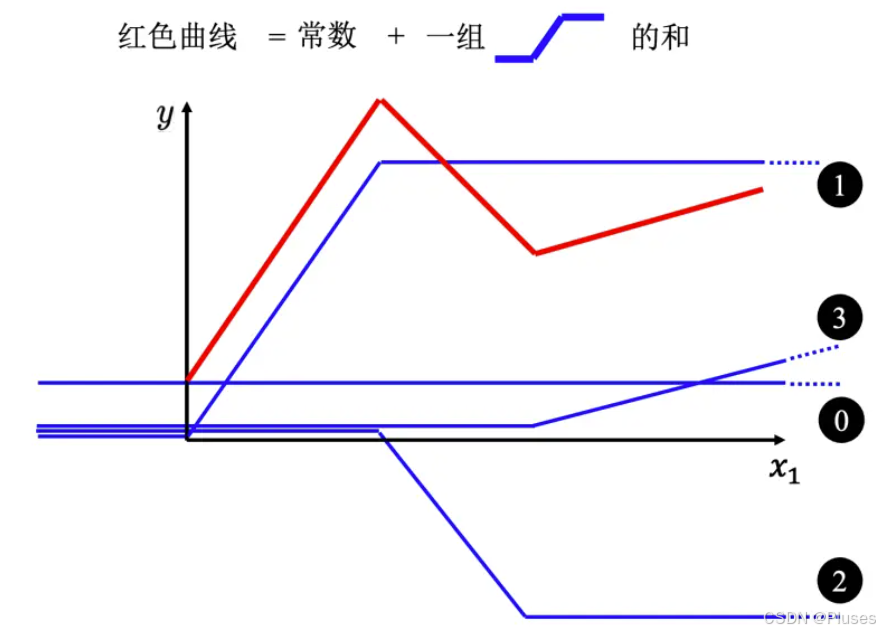
所以红色线,即分段线性曲线(piecewise linear curve)可以看作是一个常数,再加上一堆蓝色的函数。
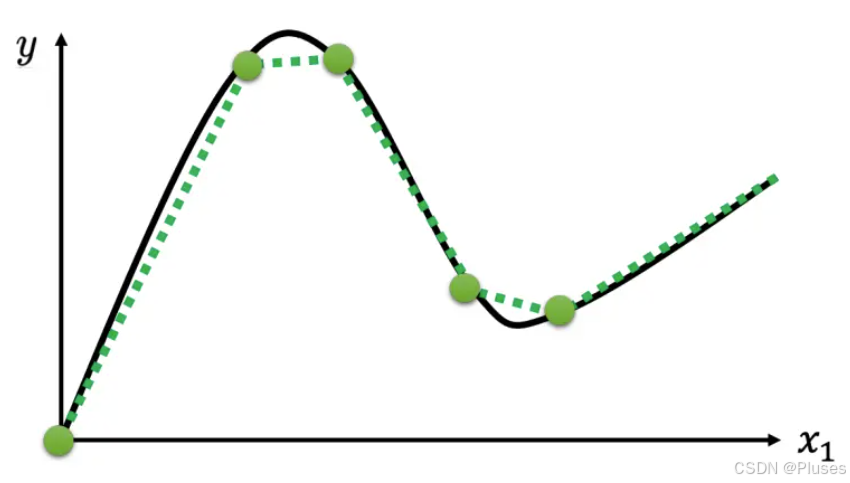
也许要考虑的x跟y的关系不是分段线性曲线,而是一条曲线。可以在这样的曲线上面,先取一些点,再把这些点点起来,变成一个分段线性曲线。而这个分段线性曲线跟原来的曲线,它会非常接近,如果点取的够多或点取的位置适当,分段线性曲线就可以逼近这一个连续的、有角度的、有弧度的这一条曲线。
所以可以用分段线性曲线去逼近任何的连续的曲线,而每个分段线性曲线都可以用一大堆蓝色的函数组合起来。也就是说,只要有足够的蓝色函数把它加起来,就可以变成任何连续的曲线。
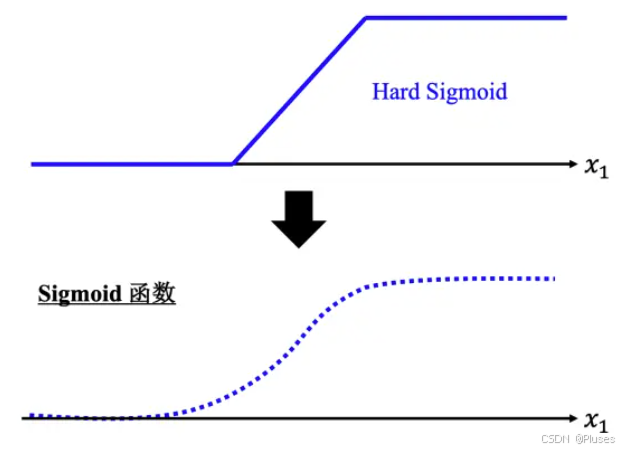
假设跟
的关系非常复杂也没关系,就想办法写一个带有未知数的函数。直接写 Hard Sigmoid 不是很容易,但是可以用一条曲线来理解它,用 Sigmoid 函数(S型的函数)来逼近 Hard Sigmoid。
Sigmoid 函数的表达式为:,其横轴输入是
,输出是
,
为常数。如果
的值,趋近于无穷大的时候,
这一项就会消失,当
非常大的时候,这一条就会收敛在高度为
的地方。如果
负的非常大的时候,分母的地方就会非常大,
的值就会趋近于 0。
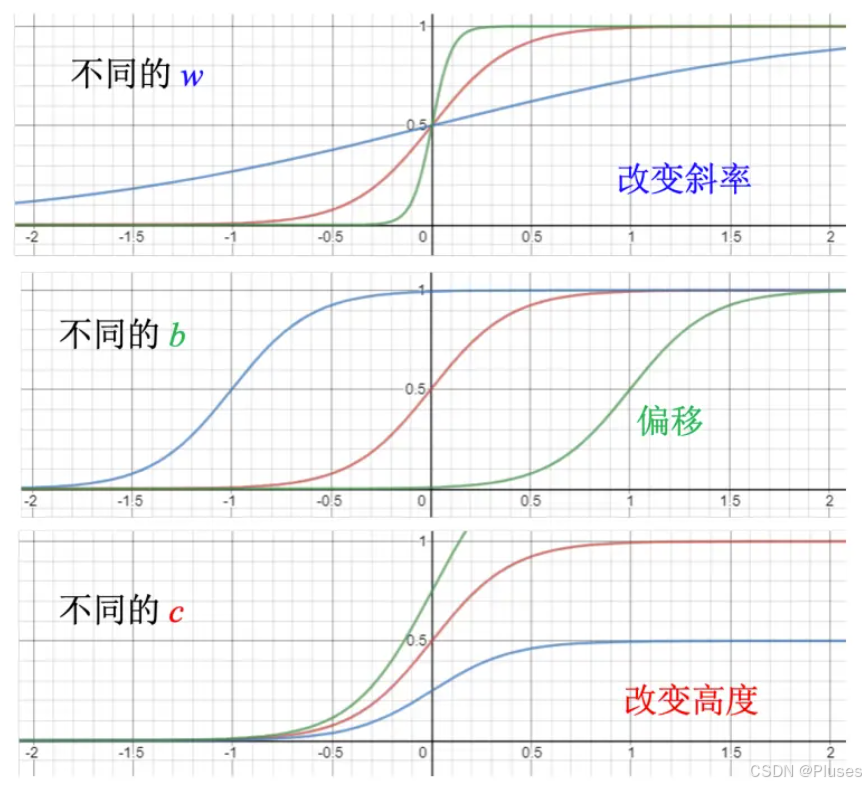
调整函数中的,
和
可以制造各种不同形状的Sigmoid 函数,把不同的Sigmoid 函数叠起来以后就可以去逼近各种不同的分段线性函数,各种不同的分段线性函数就可以用来近似各种不同的连续的函数。
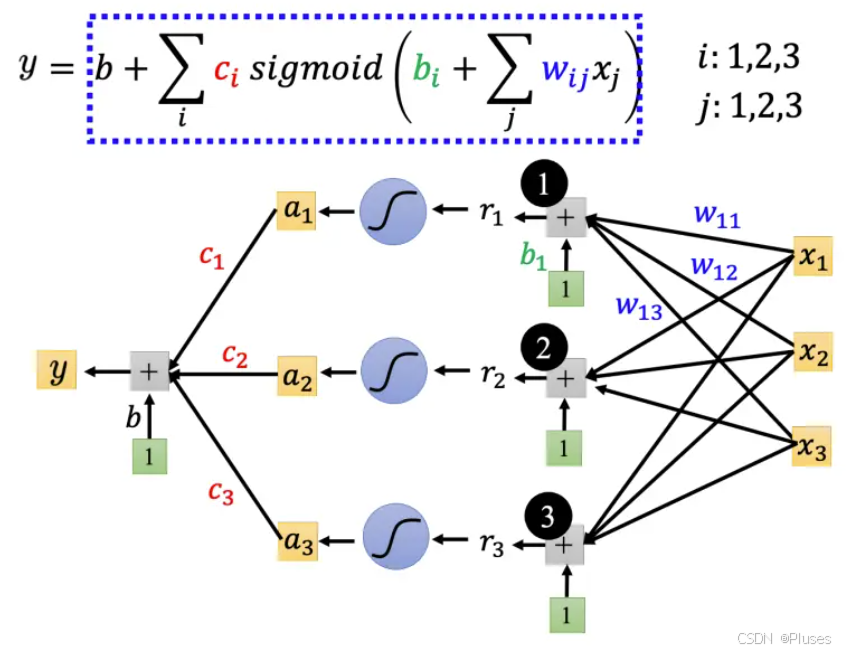
此外,我们可以不只用一个特征,可以用多个特征代入不同的
,
,
,组合出各种不同的函数,从而得到更有灵活性(flexibility)的函数。Sigmoid 越多可以产生有越多段线的分段线性函数,可以逼近越复杂的函数。Sigmoid 的数量也是一个超参数。

利用矩阵和向量相乘的方法计算更加具有灵活性的函数。

接下来要定义损失。现在未知的参数多了,再把它一个一个列出来太累了,所以直接用来统设所有的参数,所以损失函数就变成
,损失函数能够判断
的好坏,其计算方法与上文方法相同。
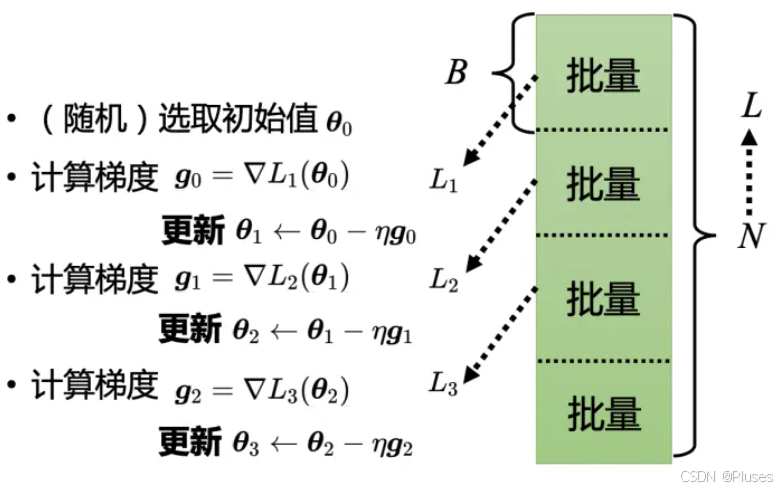
但实现上有个细节的问题,实际使用梯度下降的时候会把 N 笔数据随机分成一个一个的批量(batch),每个批量里面有 B 笔数据,现在只拿一个批量里面的数据出来算一个损失,记为跟
以示区别。假设 B 够大,也许
跟
会很接近。所以实现上每次会先选一个批量,用该批量来算
,根据
来算梯度,再用梯度来更新参数,接下来再选下一个批量算出
,根据
算出梯度,再更新参数,以此类推。
所以并不是拿来算梯度,实际上是拿一个批量算出来的
,
,
来计算梯度。把所有的批量都看过一次,称为一个回合(epoch),每一次更新参数叫做一次更新。更新跟回合的区别,用两个例子来说明:
- 假设有 10000 笔数据,即 N 等于 10000,批量的大小设 10,也就是 B 等于 10。10000 个样本(example)形成了 1000 个批量,所以在一个回合里面更新了参数 1000 次
- 假设有 1000 个数据,批量大小(batch size)和 Sigmoid的个数都是超参数,可以自行设置不同的值。所以做了一个回合的训练其实不知道它更新了几次参数,有可能 1000 次,也有可能 10 次,更新次数取决于它的批量大小。
2、模型变形
其实还可以对模型做更多的变形,不一定要把 Hard Sigmoid 换成 Soft Sigmoid。HardSigmoid 可以看作是两个修正线性单元(Rectified Linear Unit,ReLU)的加总,ReLU 的图像有一个水平的线,走到某个地方有一个转折的点,变成一个斜坡,其对应的公式为:
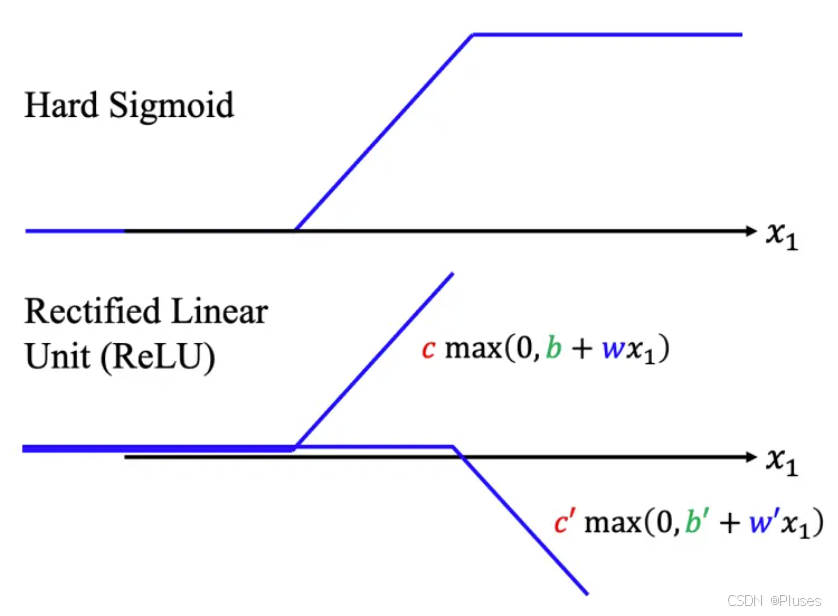
要合成 i 个 Hard Sigmoid,需要 i 个 Sigmoid,如果 ReLU 要做到一样的事情,则需要 2i 个 ReLU,因为 2 个 ReLU 合起来才是一个 Hard Sigmoid。因此表示一个 Hard 的 Sigmoid 不是只有一种做法。在机器学习里面,Sigmoid 或 ReLU 称为激活函数(activation function)

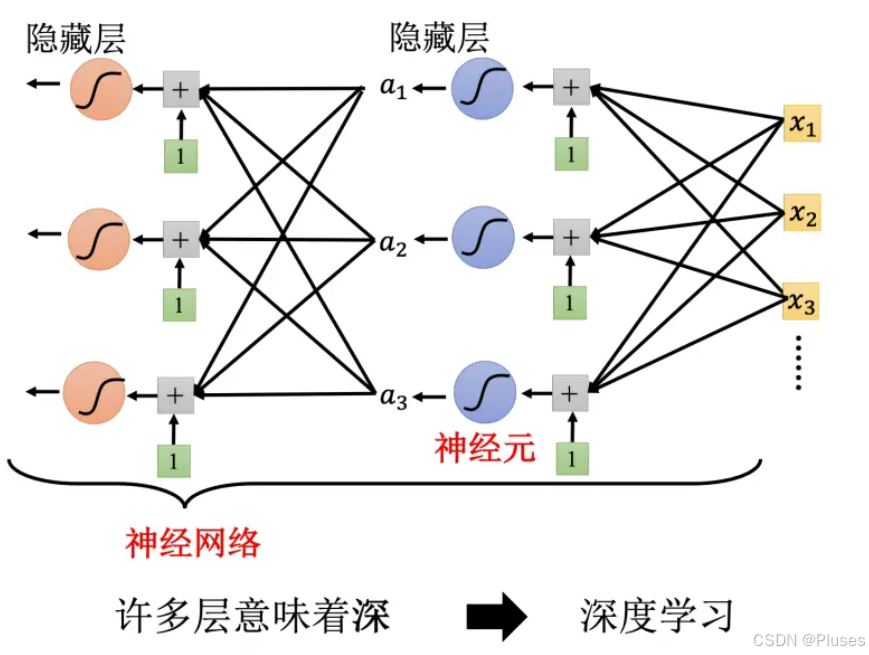
Sigmoid 或 ReLU 称为神经元(neuron),很多的神经元称为神经网络(neural network)。人脑中就是有很多神经元,很多神经元串起来就是一个神经网络,人工智能就是在模拟人脑。每一排称为一层,称为隐藏层(hiddenlayer),很多的隐藏层就“深”,这套技术便称为深度学习。 现在人们把神经网络越叠越多,越叠越深,以降低错误率达到更好的拟合效果,但是在训练拟合的过程中要注意防止过拟合(overfitting)
 深度学习的训练会用到反向传播(BackPropagation,BP),其实它就是比较有效率、算梯度的方法。
深度学习的训练会用到反向传播(BackPropagation,BP),其实它就是比较有效率、算梯度的方法。
3、机器学习框架
在机器学习中会有训练数据和测试数据,他们之间最大的差异就是测试集只有没有
,数据如下所示:
训练数据:,测试数据:
训练有三个步骤:
- 先写出一个有未知数
的函数,
的意思就是函数叫
- 定义损失,损失是一个输入就是一组参数的函数,然后利用损失去判断这一组参数的好坏
- 解一个优化的问题,找一个
,即:
有了以后,就把它拿来用在测试集上,也就是把
带入这些未知的参数,本来
里面有一些未知的参数,现在
用
来取代,输入是测试集,输出的结果存起来,上传到Kaggle 即可。
hahaha都看到这里了,要是觉得有用的话就辛苦动动小手点个赞吧!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











