






朴素贝叶斯是一种基于贝叶斯定理的分类算法,其核心思想是通过先验概率和样本数据中的条件概率来计算后验概率,进而进行分类预测。算法的"朴素"之处在于假设特征之间是相互独立的,这使得计算变得简单。在分类问题中,朴素贝叶斯通过利用已知信息进行概率推断,选择具有最高后验概率的类别作为预测结果。尽管这是一个较强的假设,但朴素贝叶斯在处理文本分类等问题时表现良好,是一种简单而有效的分类方法。
一、贝叶斯公式
先验概率(Prior Probability):
先验概率是在考虑任何新的观测数据之前,基于以往经验或先前信息对事件发生概率的估计。它是对事件的初始信仰或置信度,没有考虑新的数据。在朴素贝叶斯中,先验概率通常指的是在没有任何新证据的情况下,某一类别的概率。
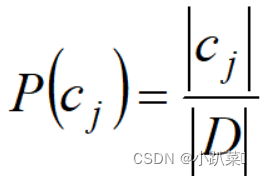
后验概率(Posterior Probability):
后验概率是在考虑了新的观测数据后,通过贝叶斯定理计算得出的概率。它是基于先验概率和新数据的联合概率,表示在观测到新数据之后对事件发生概率的修正或更新。在朴素贝叶斯中,后验概率是在考虑了特征数据后,某一类别的概率。
贝叶斯定理(Bayes' theorem ):
它是一种通过先验概率和观测数据来更新我们对事件概率的估计的方法。
贝叶斯定理的表达式为:
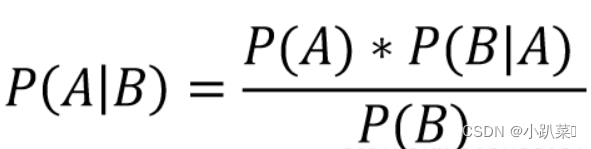
其中:
P(A∣B) 是后验概率,表示在观测到B后,A的概率。
P(B∣A) 是似然度,表示在A条件下观测到B的概率。
P(A) 是先验概率,表示在考虑任何新的观测数据之前A的概率。
P(B) 是边缘概率,表示观测到B的概率。
在朴素贝叶斯中,我们通常关注的是在给定某个类别的先验概率(P(A)),以及在该类别下观测到特征数据的似然度(P(B∣A))。通过应用贝叶斯定理,我们可以计算出在考虑特征数据后,该类别的后验概率(P(A∣B)),从而进行分类预测。
二、朴素贝叶斯分类器
朴素贝叶斯分类器是一种基于贝叶斯定理的概率分类算法。其核心思想在于通过先验概率和样本数据中的条件概率,利用贝叶斯定理计算后验概率,从而进行分类预测。"朴素"体现在算法对特征之间的独立性的假设上,使得计算变得简单。在分类问题中,朴素贝叶斯分类器通过比较不同类别的后验概率,选择具有最高概率的类别作为预测结果。尽管基于较强的独立性假设,朴素贝叶斯在文本分类等领域表现出色,是一种简单而有效的分类方法。
基于属性条件独立性假设,我们可以重新表达后验概率P(c∣x)。在这里,d 表示属性的数量,xi 表示在第 i 个属性上的取值。由于对于所有类别来说,P(x) 相同,因此贝叶斯判定准则(即朴素贝叶斯分类器的表达式)为:
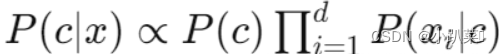
显而易见,朴素贝叶斯分类器的训练过程涉及基于训练集 D 估计类先验概率 P(c),并为每个属性估计条件概率 P(xi∣c)。
定义 Dc 表示训练集 D 中第 c 类样本组成的集合。如果有充足的独立同分布样本,我们可以容易地估计类先验概率:
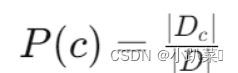
对于离散属性,定义 Dc,xi 表示在第 i 个属性上取值为 xi 的样本组成的集合,条件概率可估计为:
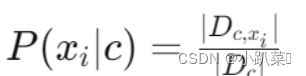
对于连续属性,我们可以考虑概率密度函数,假设 Xi 在第c 类样本上的取值服从高斯分布,其中 μc,i 和 σc,i 分别是第 c 类样本在第i 个属性上取值的均值和方差。
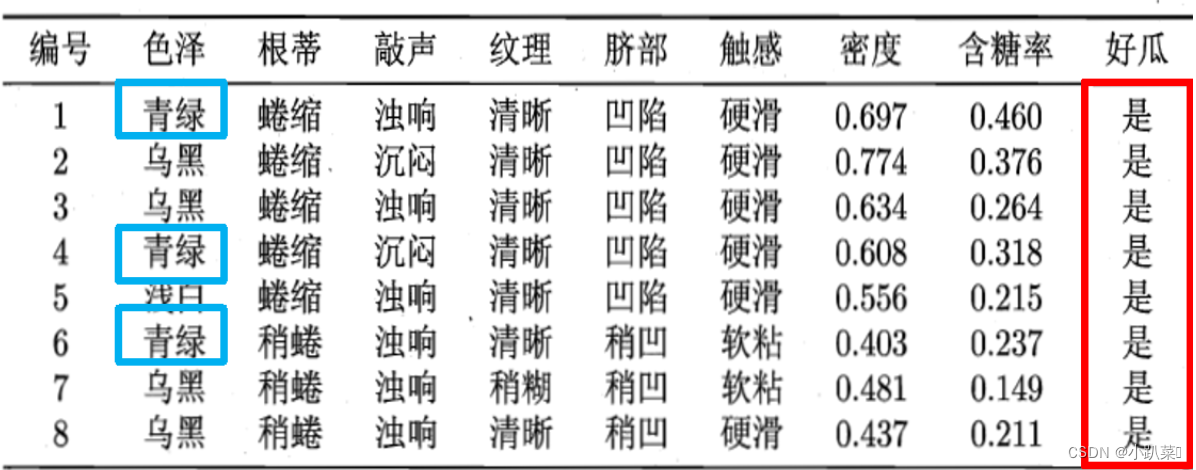
例子:用西瓜数据集训练一个朴素贝叶斯分类器,对测试例进行分类




三、拉普拉斯修正
拉普拉斯修正是朴素贝叶斯分类器中用于处理零概率问题的一种方法。由于属性条件独立性假设,当训练集中某个类别下的某个属性值未出现时,对应的条件概率为零,这可能导致整体概率计算失效。为避免这种情况,拉普拉斯修正通过在频数上添加一个小的常数,确保所有属性值都有非零的概率,从而提高了模型的泛化能力。这种调整有助于更准确地估计先验概率和条件概率,提高了朴素贝叶斯分类器在实际应用中的性能表现。

四、朴素贝叶斯分类器基本步骤
朴素贝叶斯分类器的基本步骤包括以下几个阶段:
收集数据: 获取带有标签的训练数据集,其中包含已分类的样本和它们的特征。
预处理数据: 对数据进行清理和预处理,包括处理缺失值、标准化数据等。
提取特征: 从训练数据中提取用于分类的特征,这些特征应与分类目标相关。
训练模型: 使用训练数据集估计类别的先验概率和特征的条件概率,即计算P(c) 和 P(xi∣c)。
应用模型: 对于新的未标记数据,使用贝叶斯定理计算后验概率,选择具有最高后验概率的类别作为预测结果。
评估模型: 使用测试数据评估模型的性能,通常通过计算分类准确度、精确度、召回率等指标。
五、垃圾邮件分类
样本数据构建
基于已经分辨好的垃圾邮件和良好邮件,构成两种不同的数据集。

以及test文件。将他们统一命名为以ham或者spam开头的文件
用python代码构建单词库
利用了jieba库,提高了我构建单词库的效率,对于spam的构建也是类似的。大致原理就是便利ham文件夹下的所有txt文件,然后去检索每个以空格分隔的字符串,寻找单词库中是否存在同一个,没有则添加,有则略过。
def ham_words():
folder_path = './email/ham'
# 获取文件夹下的所有 txt 文件
txt_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 初始化单词库
word_all_ham = set()
# 遍历所有 txt 文件
for txt_file in txt_files:
with open(os.path.join(folder_path, txt_file), 'r') as f:
# 读取文件内容,去掉标点符号
content = f.read().replace('-',' ').replace(':',' ').replace(',', '').replace('.', '').replace('?', '').replace('!', '').replace('&',' ').replace('=',' ').replace('(',' ').replace(')',' ').replace('\\',' ')
# 对内容进行分词
words = jieba.cut(content)
# 将分词结果添加到单词库
word_all_ham.update(words)
# 将单词库保存为 txt 文件
with open('./email/word_all_ham.txt', 'w') as f:
for word in word_all_ham:
f.write(word + '\n')
print('ham 单词库创建完成!')利用python代码构建目标邮件的单词库,并且检索ham和spam单词库的词出现的频率
def find_word(file_words,txt_path):
word_dict = {}
# 读取词库文件,构建词库
with open(file_words, 'r') as f:
for line in f:
word = line.strip()
if word:
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 1
# 读取文本文件
with open(txt_path, 'r') as f:
content = f.read()
# 将内容转换为小写并去除标点符号
content = re.sub(r'[^\w\s]', '', content.lower())
# 使用 jieba 进行分词
words = jieba.cut(content)
# 统计单词频率
for word in words:
if word in word_dict:
word_dict[word] += 1
# 输出结果
count_all = 0
for word, count in word_dict.items():
#print(f'{word}: {count}')
count_all+=count-1
return count_all这里的txt_path是指spam或者pam的单词库路径,去检索word 在他们这两个单词库的出现频率
完整代码
import os
import re
import jieba
def ham_words():
folder_path = './email/ham'
# 获取文件夹下的所有 txt 文件
txt_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 初始化单词库
word_all_ham = set()
# 遍历所有 txt 文件
for txt_file in txt_files:
with open(os.path.join(folder_path, txt_file), 'r') as f:
# 读取文件内容,去掉标点符号
content = f.read().replace('-',' ').replace(':',' ').replace(',', '').replace('.', '').replace('?', '').replace('!', '').replace('&',' ').replace('=',' ').replace('(',' ').replace(')',' ').replace('\\',' ')
# 对内容进行分词
words = jieba.cut(content)
# 将分词结果添加到单词库
word_all_ham.update(words)
# 将单词库保存为 txt 文件
with open('./email/word_all_ham.txt', 'w') as f:
for word in word_all_ham:
f.write(word + '\n')
print('ham 单词库创建完成!')
def spam_words():
folder_path = './email/spam'
# 获取文件夹下的所有 txt 文件
txt_files = [f for f in os.listdir(folder_path) if f.endswith('.txt')]
# 初始化单词库
word_all_spam = set()
# 遍历所有 txt 文件
for txt_file in txt_files:
with open(os.path.join(folder_path, txt_file), 'r') as f:
# 读取文件内容,去掉标点符号
content = f.read().replace('-',' ').replace(':',' ').replace(',', '').replace('.', '').replace('?', '').replace('!', '').replace('&',' ').replace('=',' ').replace('(',' ').replace(')',' ').replace('\\',' ')
# 对内容进行分词
words = jieba.cut(content)
# 将分词结果添加到单词库
word_all_spam.update(words)
# 将单词库保存为 txt 文件
with open('./email/word_all_spam.txt', 'w') as f:
for word in word_all_spam:
f.write(word + '\n')
print('spam 单词库创建完成!')
def find_word(file_words,txt_path):
word_dict = {}
# 读取词库文件,构建词库
with open(file_words, 'r') as f:
for line in f:
word = line.strip()
if word:
if word in word_dict:
word_dict[word] += 1
else:
word_dict[word] = 0
# 读取文本文件
with open(txt_path, 'r') as f:
content = f.read()
# 将内容转换为小写并去除标点符号
content = re.sub(r'[^\w\s]', '', content.lower())
# 使用 jieba 进行分词
words = jieba.cut(content)
# 统计单词频率
for word in words:
if word in word_dict:
word_dict[word] += 1
# 输出结果
count_all = 0
for word, count in word_dict.items():
#print(f'{word}: {count}')
count_all+=count
return count_all
def counts_of_txt(text):
# 统计单词数
with open(text, 'r') as file:
content = file.read()
#过滤符号
words = re.findall(r'\b\w+\b', content)
word_count = len(words)
#print("单词数:", word_count)
return word_count
if __name__ == '__main__':
ham_words_path = './email/word_all_ham.txt'
spam_words_path = './email/word_all_spam.txt'
test_path = './email/test/'
ham_words()
spam_words()
#txt_path = './email/test/21.txt'
test_files = [f for f in os.listdir(test_path) if f.endswith('.txt')]
test_num = len(test_files)
P_right = 0
for txt_path in test_files:
temp_path = test_path + txt_path
true_mark = 0 # 对于邮件来说真正是不是有效的标识符
temp_mark = 0 # 对于模型来说判断是不是有效的标识符
#print(temp_path)
spam_word = find_word(spam_words_path, temp_path)
ham_word = find_word(ham_words_path, temp_path)
word_nums = counts_of_txt(temp_path)
# print('spam = ', spam_word)
# print('ham = ', ham_word)
if word_nums!=0:
P_of_ham = ham_word / (word_nums * 1.0) * 1 / 2
P_of_spam = spam_word / (word_nums * 1.0) * 1 / 2 # 这个1/2是由样本数量决定
if P_of_ham > P_of_spam:
print(txt_path," is good email")
temp_mark = 1
else:
print(txt_path," is bad email")
temp_mark = 2
else:
temp_mark = 2
print(txt_path, " is bad email")
if 'ham' in txt_path:
true_mark = 1
if 'spam' in txt_path:
true_mark = 2
if true_mark == temp_mark:
P_right += 1
print('模型的正确率是:',(P_right)/test_num * 100 ,'%')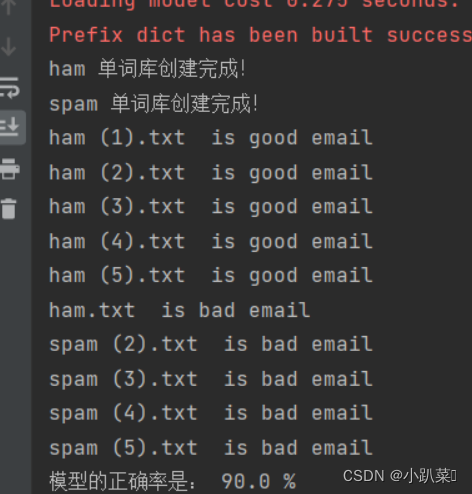


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









