






哈希表的基本概念
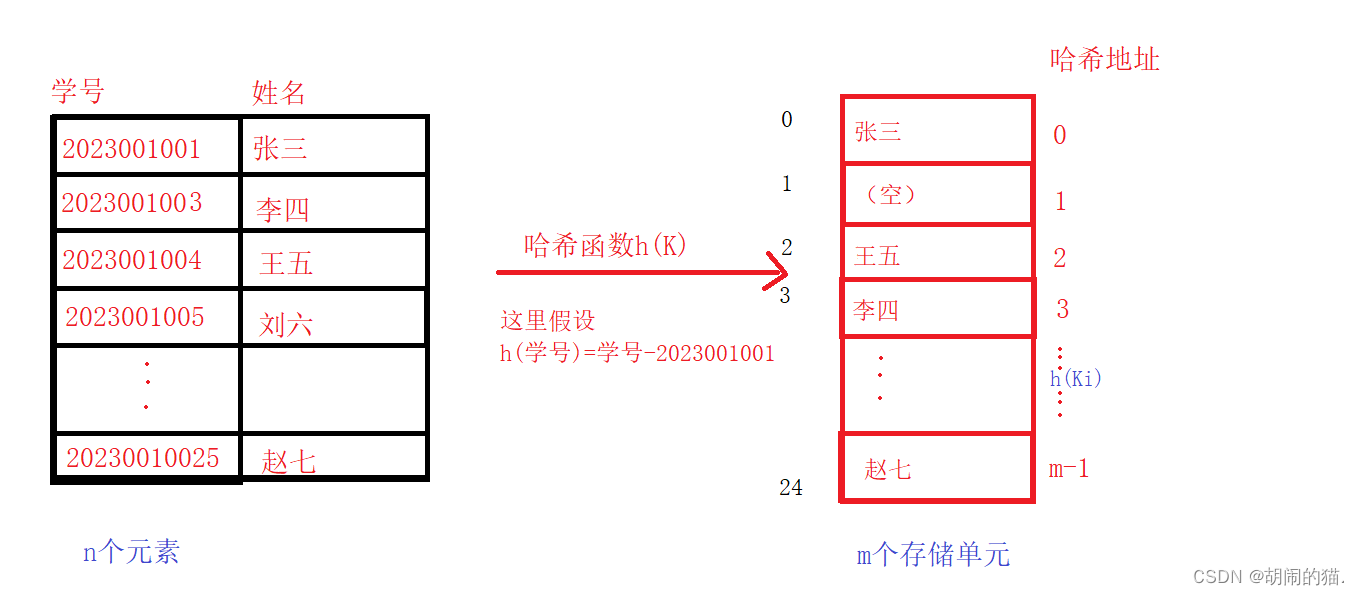
哈希表(hash table)又称为散列表,其基本思路是:设要储存的元素个数为 n , 设置一个长度为 m 的连续内存存储单元,以每个元素的关键字 Ki(0 ≤ i ≤ n-1)为自变量,通过一个称为哈希函数的函数h(Ki) 把 Ki 映射为内存单元的地址(或下标),并把该元素存储在这个内存单元中,h(Ki)也称为哈希地址。如此构造的线性表存储结构叫做哈希表。
e.g
哈希冲突
在构建哈希表的过程出如果出现h(Ki)==h(Kj)的现象,我们将这种现象称为哈希冲突 。通常将这种具有不同关键字而具有相同哈希地址的元素称为同义词,这种冲突也叫同义词冲突。
e.g
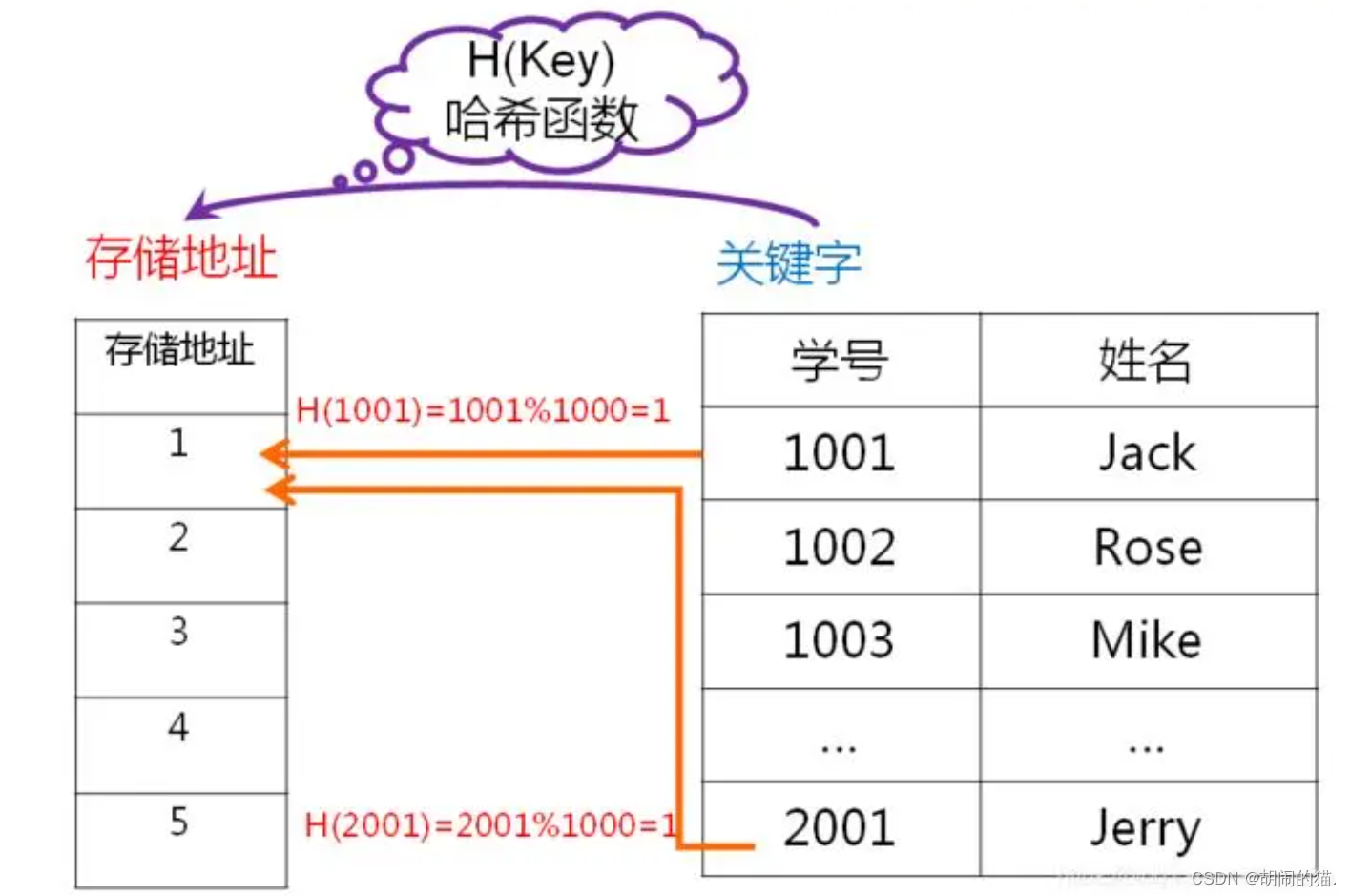
在哈希表存储结构中,同义词冲突是很难避免的,因此对频繁进行查找的关键字应该尽力设计一个完美的哈希函数。
哈希表的查找性能
哈希表的查找性能主要与3个因素有关:
- 与装填因子α有关
装填因子 α:指哈希表中已存入的元素 n 与哈希地址空间大小m的比值。即 α=n/m 。α越小,冲突的可能性就越小;α 越大(最大取值为1),冲突的可能性越大。
- 与所采用的的哈希函数有关
若哈希函数选择得当,就可以使哈希地址尽可能均匀的分布在哈希地址空间上,从而减小冲突发生;否则,就可能使哈希地址集中于某一地址处,从而加大冲突发生
- 与解决冲突的方法有关
大家解决冲突的方法不尽相同,就导致了哈希查找性能的不同
哈希函数的构造方法
构造哈希函数的目标是使所有元素的哈希地址尽可能均匀地分布在m个连续内存单元上,同时使计算过程尽可能简单以达到尽可能高的时间效率。这里介绍几种常用的整数类型关键字的哈希函数构造方法。
- 直接定址法
概念:以关键字k本身或关键字加上某个常量c作为哈希地址的方法。
h(k) = k + c
优点:计算简单
缺点:关键字分布不均匀时,将造成大量内存单元浪费
- 除留余数法
概念:用关键字k除以某个不大于哈希表长度m的整数p所得的余数作为哈希地址。
h(k) = k % p (p≤m)
优点:计算简单,适用范围广
缺点:对于其他类型的数学运算无法使用。例如,对于分数的求余运算
- 数字分析法
e.g
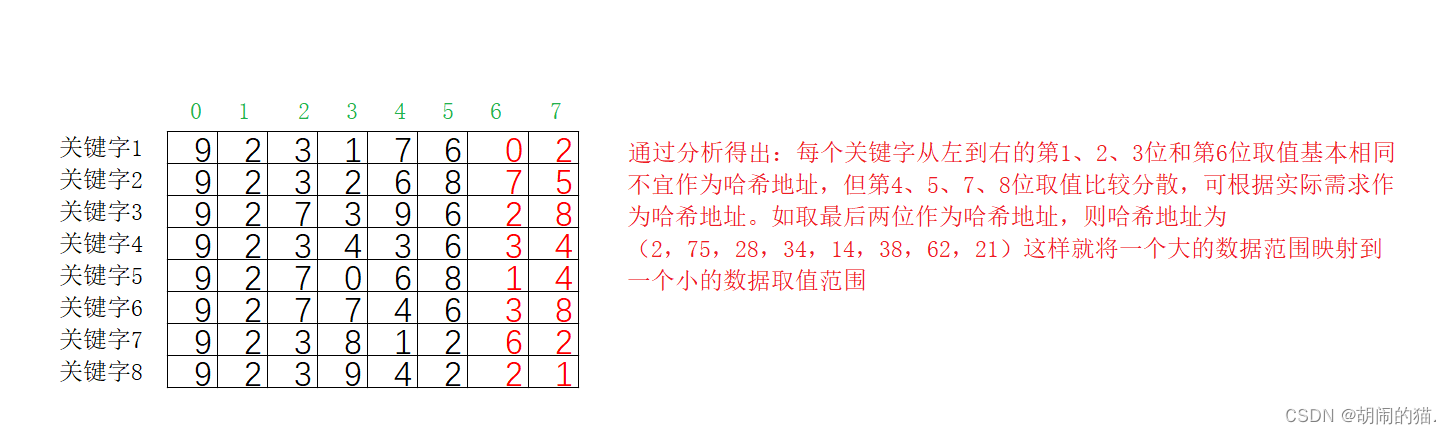
优点:便于处理大的数据
缺点:需要已知所有关键字的值,且对关键字的每一位的取值分布情况都进行分析
哈希表的应用
e.g
题目:
编写一个函数,计算字符串中含有的不同字符的个数。字符在 ASCII 码范围内( 0~127 ,包括 0 和 127 ),换行表示结束符,不算在字符里。不在范围内的不作统计。多个相同的字符只计算一次。例如,对于字符串 abaca 而言,有 a、b、c 三种不同的字符,因此输出 3 。
int main()
{
char str[501];
int arr[128] = { 0 };//这里相当于创建了一个哈希表
int count = 0;
scanf("%s", str);
int len = strlen(str);
for (int i = 0; i < len; i++)
{
if (arr[(int)str[i]] == 0)//将字符强制转换为整型,字符的ASCII值所对应的下标,并判断是否重复
{
arr[(int)str[i]] = 1;
count++;
}
}
printf("%d\n", count);
return 0;
}



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











