






 本文介绍了如何将微调后的模型转换为lmdeployTurboMind格式,涉及模型KVCache量化、W4A16量化过程,以及如何调整配置参数以优化内存使用。作者分享了量化后的显存占用和外推能力的调整策略,最终实现本地部署并解决版本兼容性问题。
本文介绍了如何将微调后的模型转换为lmdeployTurboMind格式,涉及模型KVCache量化、W4A16量化过程,以及如何调整配置参数以优化内存使用。作者分享了量化后的显存占用和外推能力的调整策略,最终实现本地部署并解决版本兼容性问题。
目录
① 将我们之前得到的merge即微调合并好的模型转为 lmdeploy TurboMind 的格式
④ 成功了,还是W4A16 量化好弄一点。【量化后占用6G显存】
① 将我们之前得到的merge即微调合并好的模型转为 lmdeploy TurboMind 的格式
lmdeploy convert internlm-chat-7b /root/share/temp/model_repos/internlm-chat-7b/执行完成后将会在当前目录生成一个 workspace 的文件夹。这里面包含的就是 TurboMind 和 Triton “模型推理”需要到的文件。
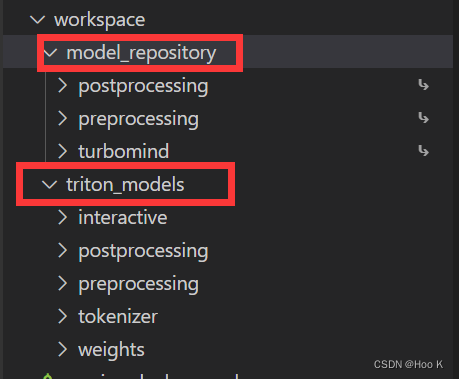
生成的workspace目录如下:
② 模型KV Cache 量化量化
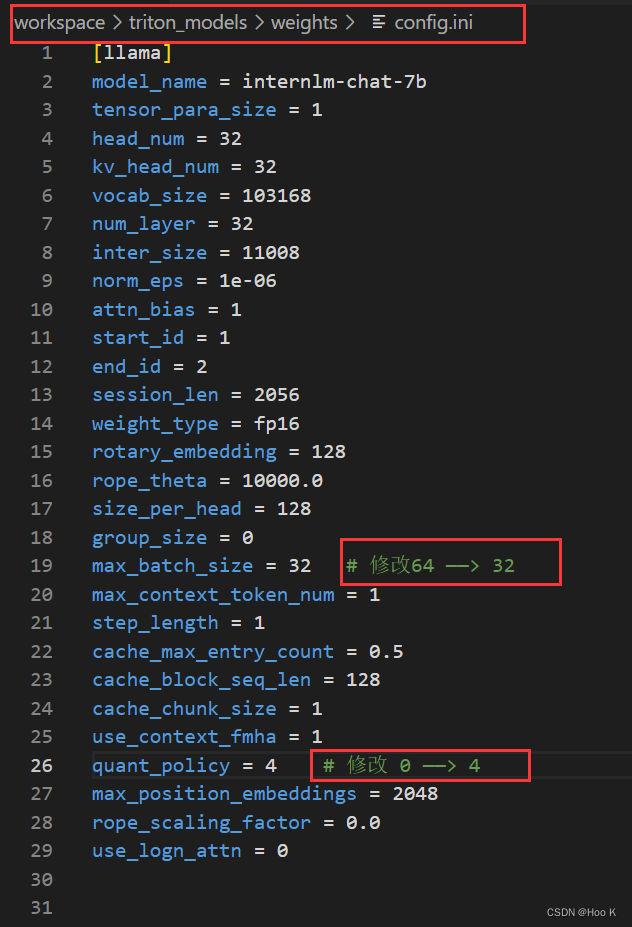
1、 我们先修改刚刚生成的workspace下的triton_models下的weights下的文件 config.ini
它里面存的主要是模型相关的配置信息
内容如下:
[llama]
model_name = internlm-chat-7b
tensor_para_size = 1
head_num = 32
kv_head_num = 32
vocab_size = 103168
num_layer = 32
inter_size = 11008
norm_eps = 1e-06
attn_bias = 0
start_id = 1
end_id = 2
session_len = 2056
weight_type = fp16
rotary_embedding = 128
rope_theta = 10000.0
size_per_head = 128
group_size = 0
max_batch_size = 64
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.5
cache_block_seq_len = 128
cache_chunk_size = 1
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 2048
rope_scaling_factor = 0.0
use_logn_attn = 0其中,模型属性相关的参数不可更改,主要包括下面这些。
model_name = llama2
head_num = 32
kv_head_num = 32
vocab_size = 103168
num_layer = 32
inter_size = 11008
norm_eps = 1e-06
attn_bias = 0
start_id = 1
end_id = 2
rotary_embedding = 128
rope_theta = 10000.0
size_per_head = 128和数据类型相关的参数也不可更改,主要包括两个。
weight_type = fp16
group_size = 0weight_type 表示权重的数据类型。目前支持 fp16 和 int4。int4 表示 4bit 权重。当 weight_type 为 4bit 权重时,group_size 表示 awq 量化权重时使用的 group 大小。
剩余参数包括下面几个。
tensor_para_size = 1
session_len = 2056
max_batch_size = 64
max_context_token_num = 1
step_length = 1
cache_max_entry_count = 0.5
cache_block_seq_len = 128
cache_chunk_size = 1
use_context_fmha = 1
quant_policy = 0
max_position_embeddings = 2048
rope_scaling_factor = 0.0
use_logn_attn = 0一般情况下,我们并不需要对这些参数进行修改,但有时候为了满足特定需要,可能需要调整其中一部分配置值。这里主要介绍三个可能需要调整的参数。
- KV int8 开关:
- 对应参数为
quant_policy,默认值为 0,表示不使用 KV Cache,如果需要开启,则将该参数设置为 4。 - KV Cache 是对序列生成过程中的 K 和 V 进行量化,用以节省显存。我们下一部分会介绍具体的量化过程。
- 当显存不足,或序列比较长时,建议打开此开关。
- 对应参数为
- 外推能力开关:
- 对应参数为
rope_scaling_factor,默认值为 0.0,表示不具备外推能力,设置为 1.0,可以开启 RoPE 的 Dynamic NTK 功能,支持长文本推理。另外,use_logn_attn参数表示 Attention 缩放,默认值为 0,如果要开启,可以将其改为 1。 - 外推能力是指推理时上下文的长度超过训练时的最大长度时模型生成的能力。如果没有外推能力,当推理时上下文长度超过训练时的最大长度,效果会急剧下降。相反,则下降不那么明显,当然如果超出太多,效果也会下降的厉害。
- 当推理文本非常长(明显超过了训练时的最大长度)时,建议开启外推能力。
- 对应参数为
- 批处理大小:
- 对应参数为
max_batch_size,默认为 64,也就是我们在 API Server 启动时的instance_num参数。 - 该参数值越大,吞度量越大(同时接受的请求数),但也会占用更多显存。
- 建议根据请求量和最大的上下文长度,按实际情况调整。
- 对应参数为
2、 模型配置修改
① kv int8 开关打开
② 根据生成古诗的实际情况 max_batch_size设为32
3、 开始kv cache量化
lmdeploy lite calibrate \
--model /root/gushi2/merged/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./quant_output在这个命令行中,会选择 128 条输入样本,每条样本长度为 2048,数据集选择 C4,输入模型后就会得到上面的各种统计值。值得说明的是,如果显存不足,可以适当调小 samples 的数量或 sample 的长度。
interstudio开发机上:
这一步由于默认需要从 Huggingface 下载数据集,国内经常不成功。所以我们导出了需要的数据,大家需要对读取数据集的代码文件做一下替换。共包括两步:
- 第一步:复制
calib_dataloader.py到安装目录替换该文件:cp /root/share/temp/datasets/c4/calib_dataloader.py /root/.conda/envs/lmdeploy/lib/python3.10/site-packages/lmdeploy/lite/utils/- 第二步:将用到的数据集(c4)复制到下面的目录:
cp -r /root/share/temp/datasets/c4/ /root/.cache/huggingface/datasets/
第二步:通过 minmax 获取量化参数。主要就是利用下面这个公式,获取每一层的 K V 中心值(zp)和缩放值(scale)。
# 通过 minmax 获取量化参数
lmdeploy lite kv_qparams \
--work_dir ./quant_output \
--turbomind_dir workspace/triton_models/weights/ \
--kv_sym False \
--num_tp 1在这个命令中,num_tp 的含义前面介绍过,表示 Tensor 的并行数。每一层的中心值和缩放值会存储到 workspace 的参数目录中以便后续使用。kv_sym 为 True 时会使用另一种(对称)量化方法,它用到了第一步存储的绝对值最大值,而不是最大值和最小值。
第三步:修改配置。也就是修改 weights/config.ini 文件,这个我们在《2.6.2 模型配置实践》中已经提到过了(KV int8 开关),只需要把 quant_policy 改为 4 即可。
这一步需要额外说明的是,如果用的是 TurboMind1.0,还需要修改参数 use_context_fmha,将其改为 0。
接下来就可以正常运行前面的各种服务了,只不过咱们现在可是用上了 KV Cache 量化,能更省(运行时)显存了。
4、 量化后不知道怎么启用
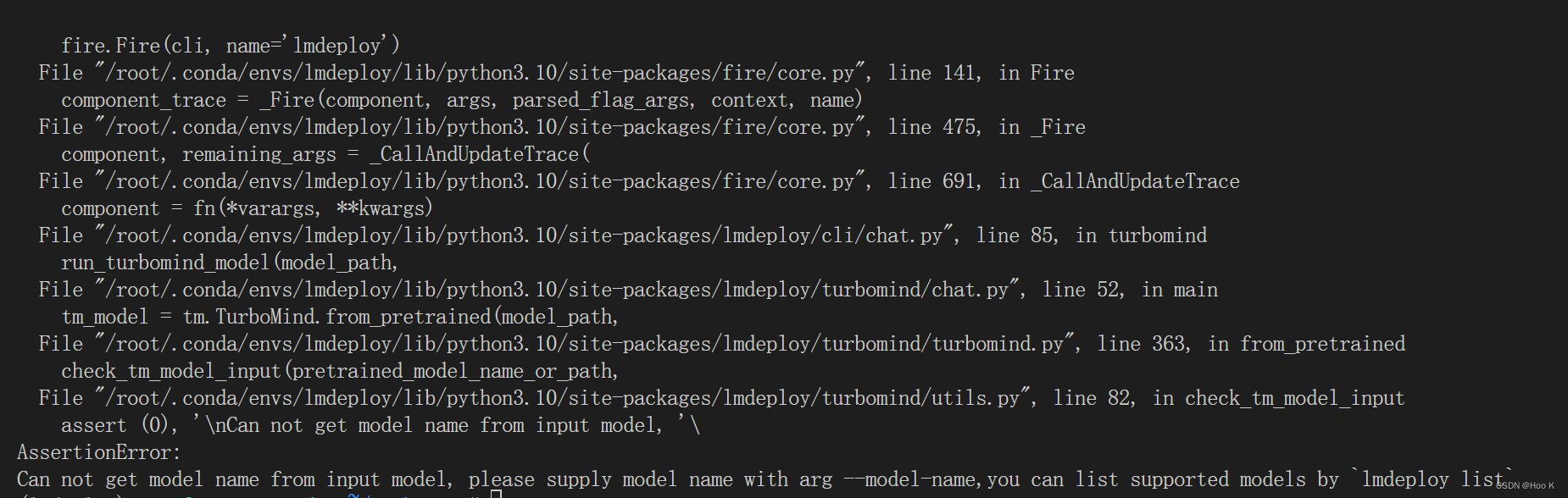
官方给的,但是我要对自己的模型微调,最后报错
# get minmax
export HF_MODEL=internlm/internlm-chat-7b
lmdeploy lite calibrate \
$HF_MODEL \
--calib-dataset 'ptb' \
--calib-samples 128 \
--calib-seqlen 2048 \
--work-dir $HF_MODEL
测试聊天效果。注意需要添加参数--quant-policy 4以开启KV Cache int8模式。
lmdeploy chat turbomind $HF_MODEL --model-format hf --quant-policy 4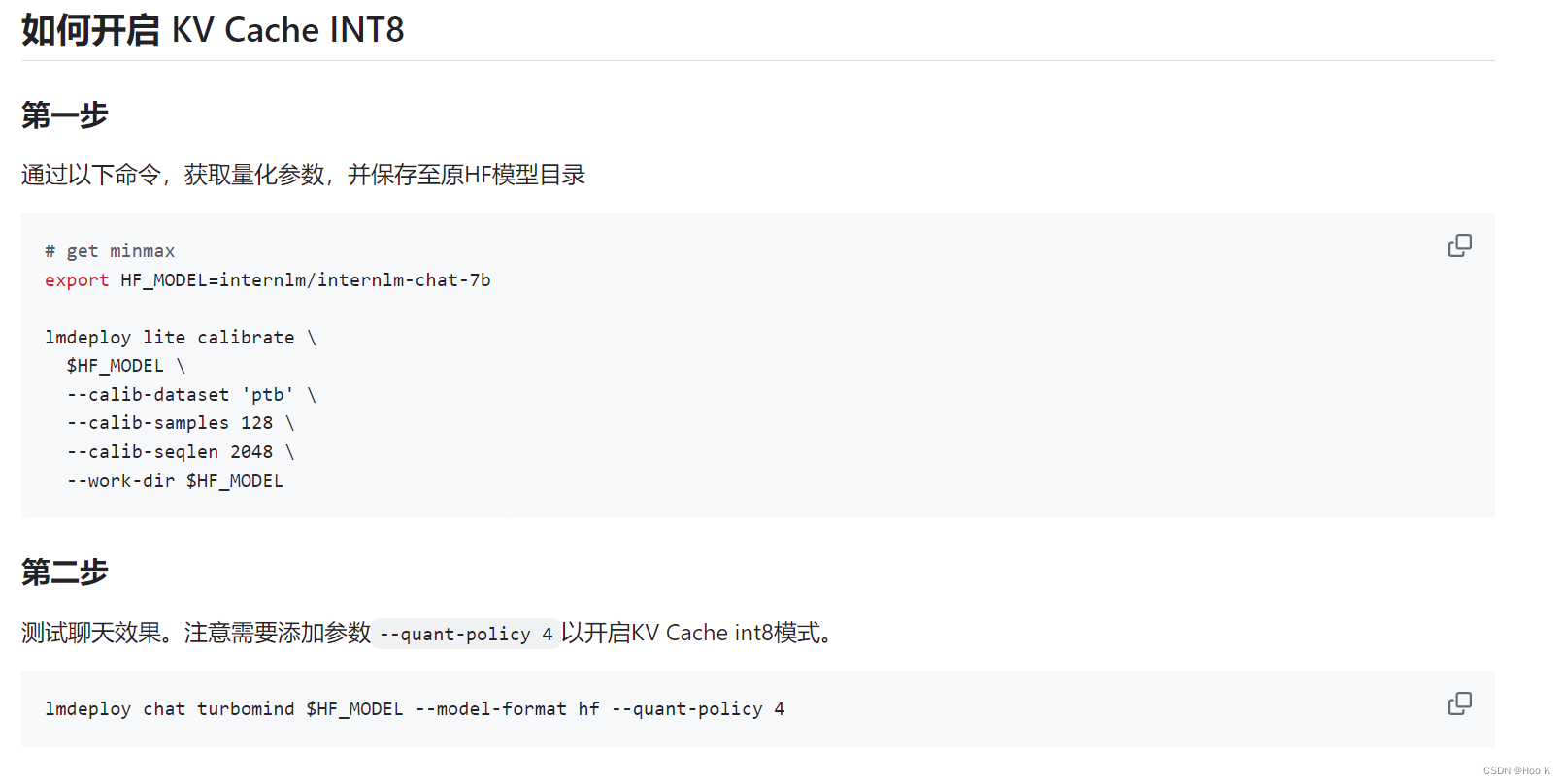
③ W4A16 量化
1. 同kv cache量化第一步一样
第一步:计算 minmax。主要思路是通过计算给定输入样本在每一层不同位置处计算结果的统计情况。
# 计算 minmax
lmdeploy lite calibrate \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--calib_dataset "c4" \
--calib_samples 128 \
--calib_seqlen 2048 \
--work_dir ./quant_output2、 量化权重模型。利用第一步得到的统计值对参数进行量化,
具体又包括两小步:
- 缩放参数。
- 整体量化。
第二步的执行命令如下:
# 量化权重模型
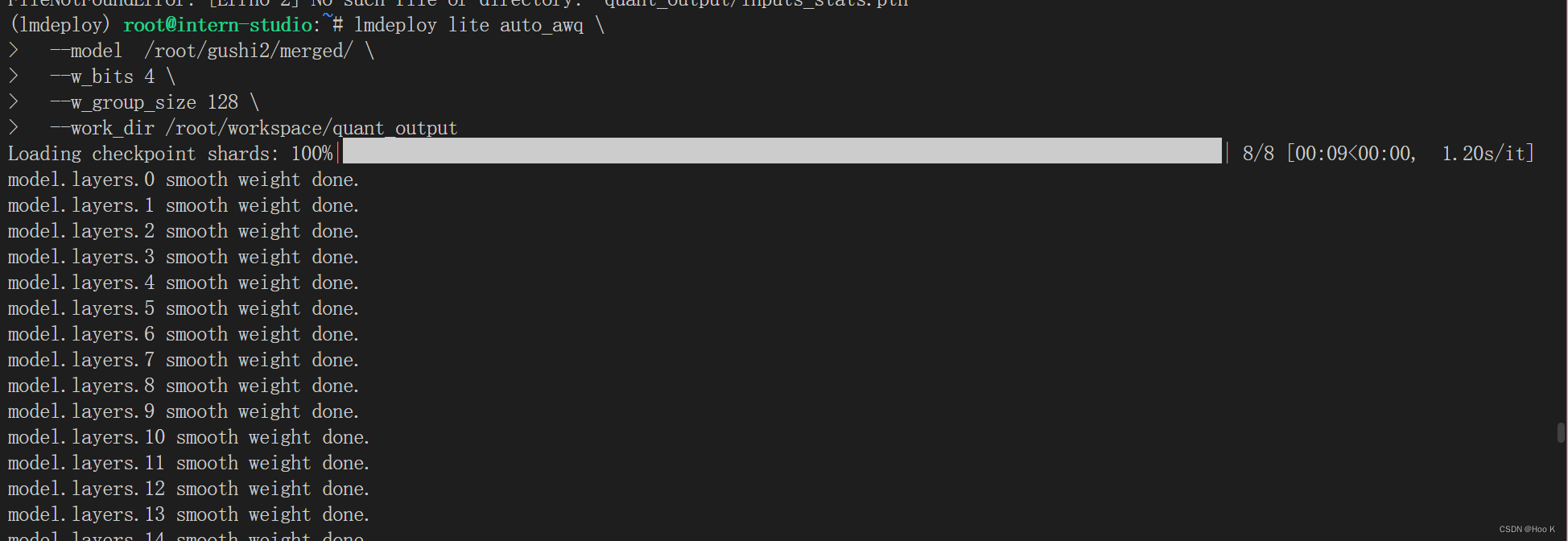
lmdeploy lite auto_awq \
--model /root/share/temp/model_repos/internlm-chat-7b/ \
--w_bits 4 \
--w_group_size 128 \
--work_dir ./quant_output 命令中 w_bits 表示量化的位数,w_group_size 表示量化分组统计的尺寸,work_dir 是量化后模型输出的位置。这里需要特别说明的是,因为没有 torch.int4,所以实际存储时,8个 4bit 权重会被打包到一个 int32 值中。所以,如果你把这部分量化后的参数加载进来就会发现它们是 int32 类型的。
最后一步:转换成 TurboMind 格式。
# 转换模型的layout,存放在默认路径 ./workspace 下
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128这个 group-size 就是上一步的那个 w_group_size。如果不想和之前的 workspace 重复,可以指定输出目录:--dst_path,比如:
lmdeploy convert internlm-chat-7b ./quant_output \
--model-format awq \
--group-size 128 \
--dst_path ./workspace_quant 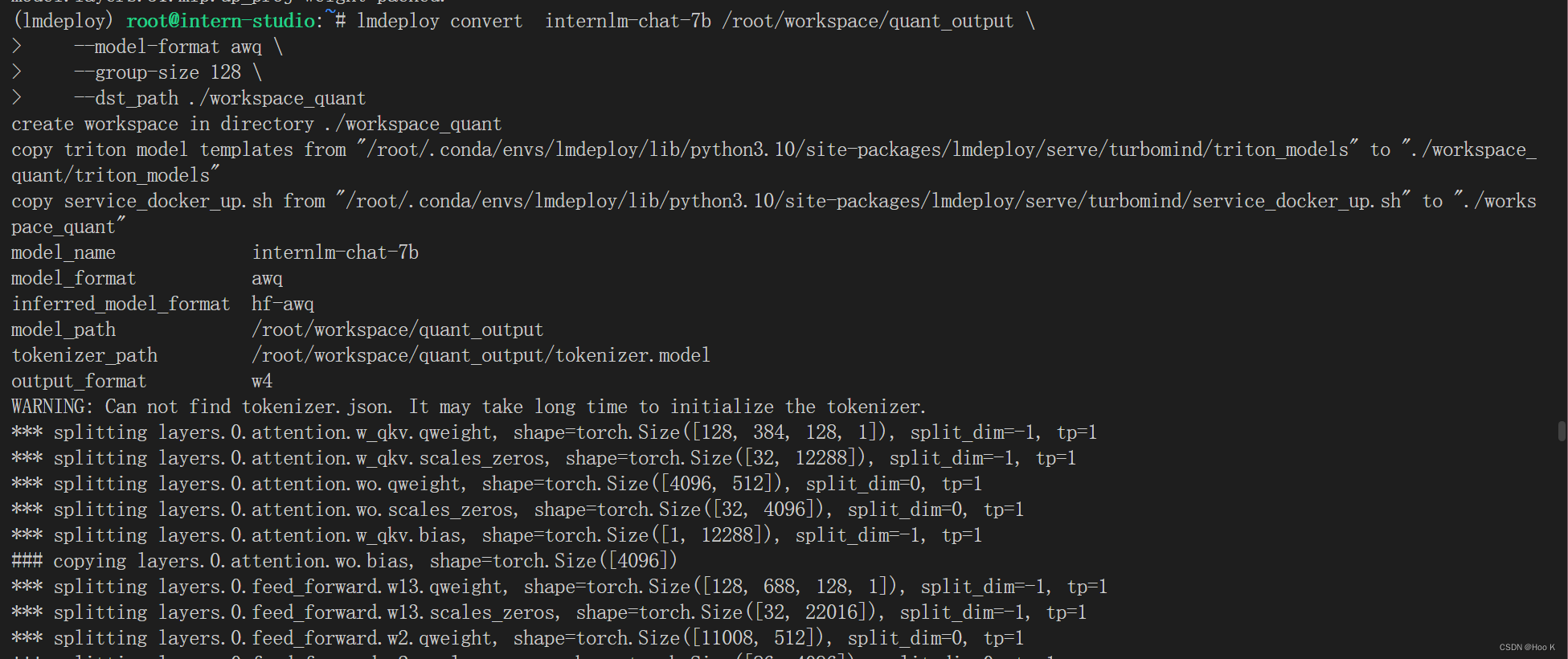
接下来和上一节一样,可以正常运行前面的各种服务了,不过咱们现在用的是量化后的模型。
最后再补充一点,量化模型和 KV Cache 量化也可以一起使用,以达到最大限度节省显存。
④ 成功了,还是W4A16 量化好弄一点。【量化后占用6G显存】
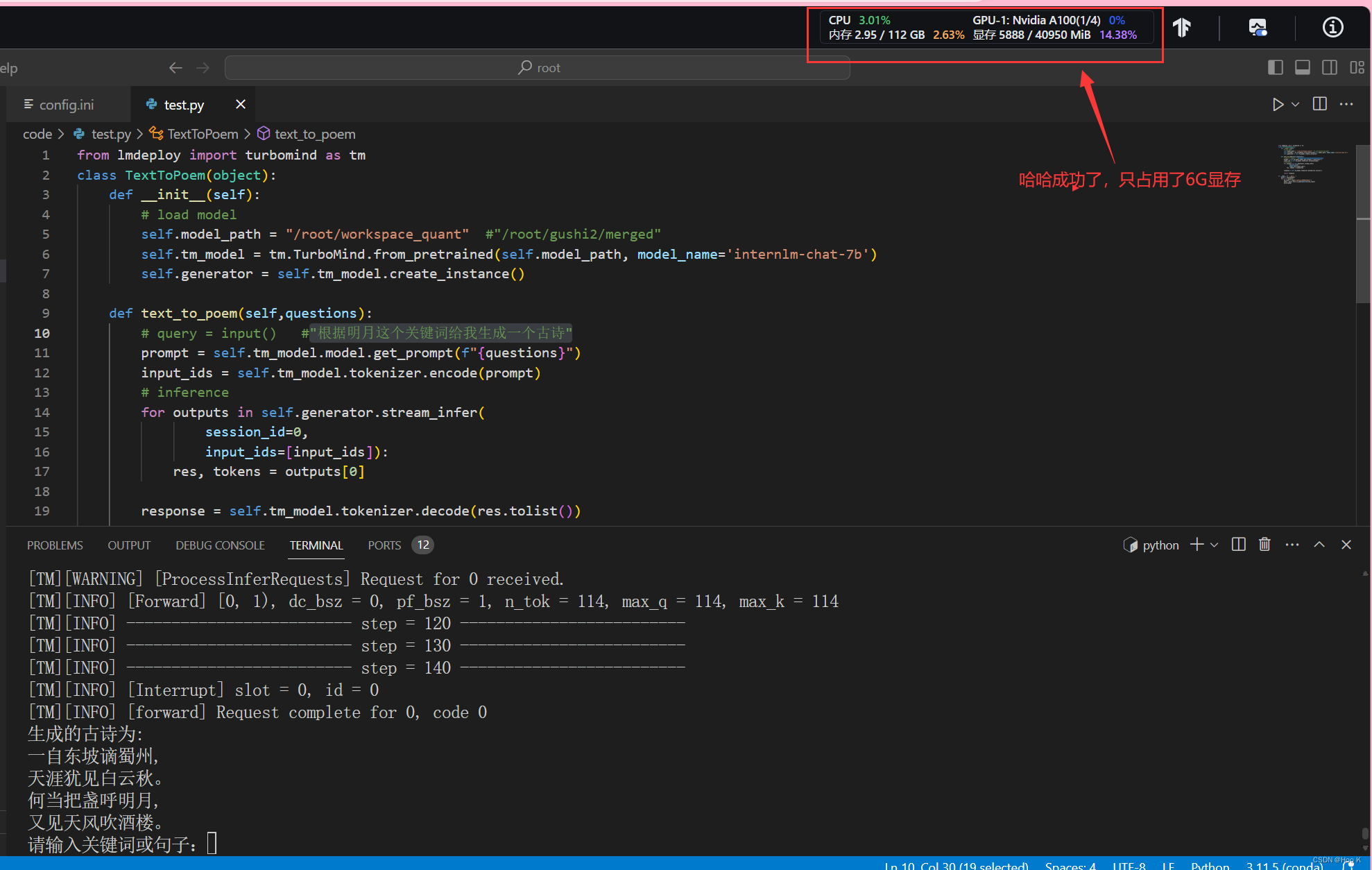
来对比一下没有量化时的模型效果和占用的显存【占用14G显存】
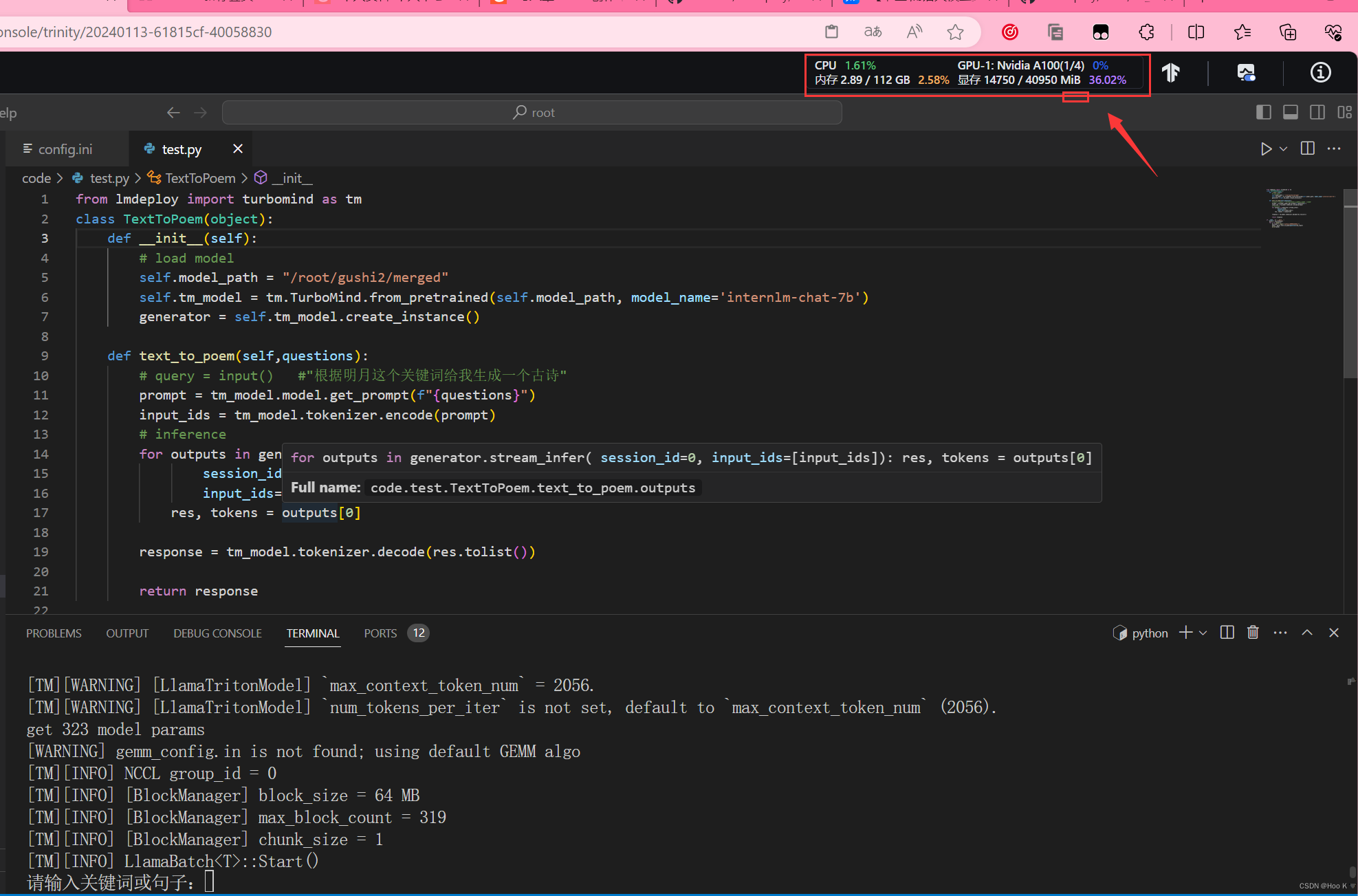
哈哈,终于可以在本地为所欲为的跑模型了,6G显存咱这电脑可算能跑起来了。
⑤ 在本地通过lmdeploy部署模型
- 使用使用TurboMind 推理 + Python 代码集成,会在本地报错【interstudio开发机上正常】
- 报错可能是lmdeploy版本问题,开发机上是0.1.0,本地是0.2.1
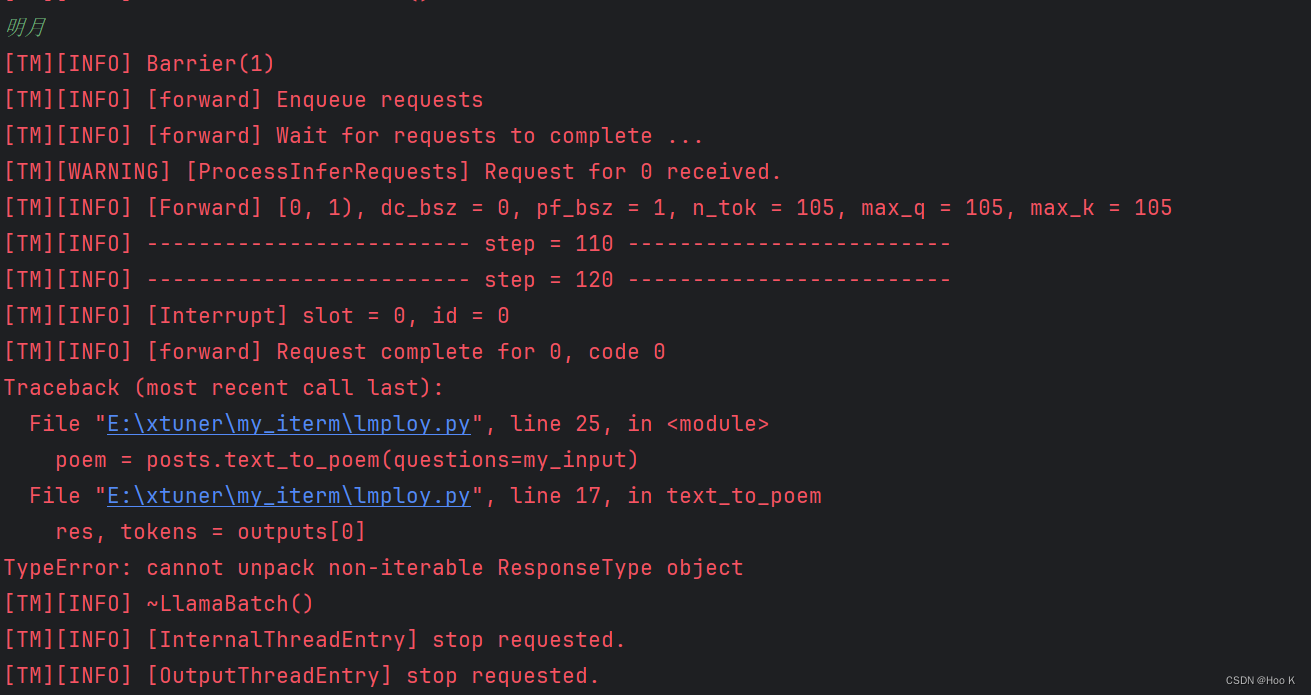
- 使用命令行在终端开启对话

响应速度超快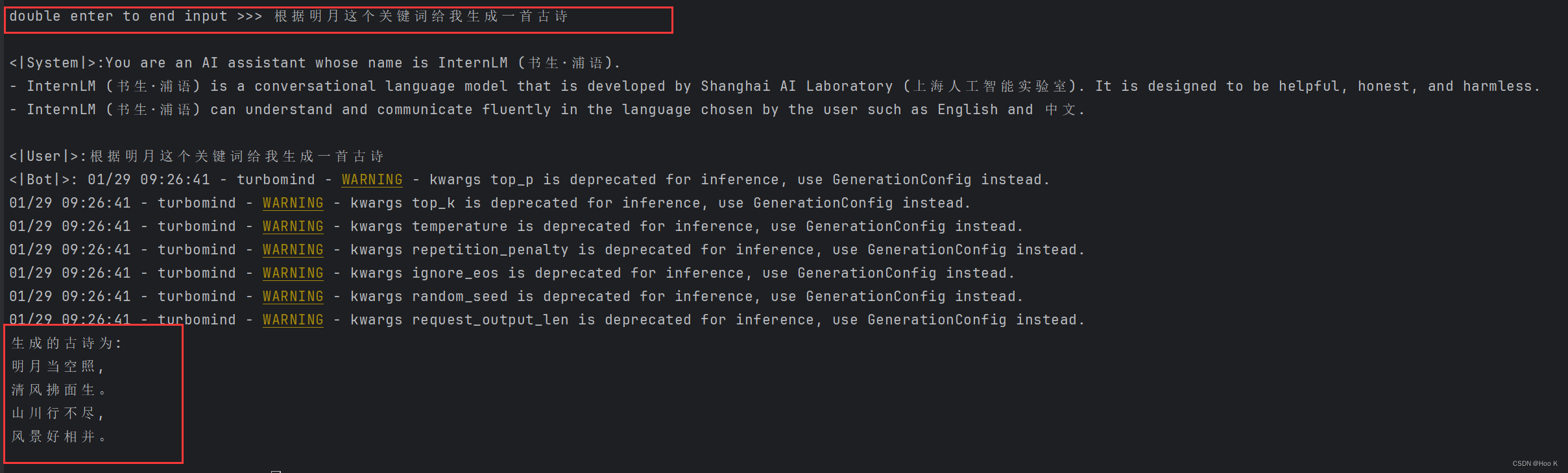
- 由于昨天使用TurboMind 推理 + Python 代码集成一直报错,今天去官方文档找解决方法,看到了这个:离线批量推理
from lmdeploy import pipeline
pipe = pipeline("internlm/internlm2-chat-7b")
response = pipe(["Hi, pls intro yourself", "Shanghai is"])
print(response)本地效果图如下:
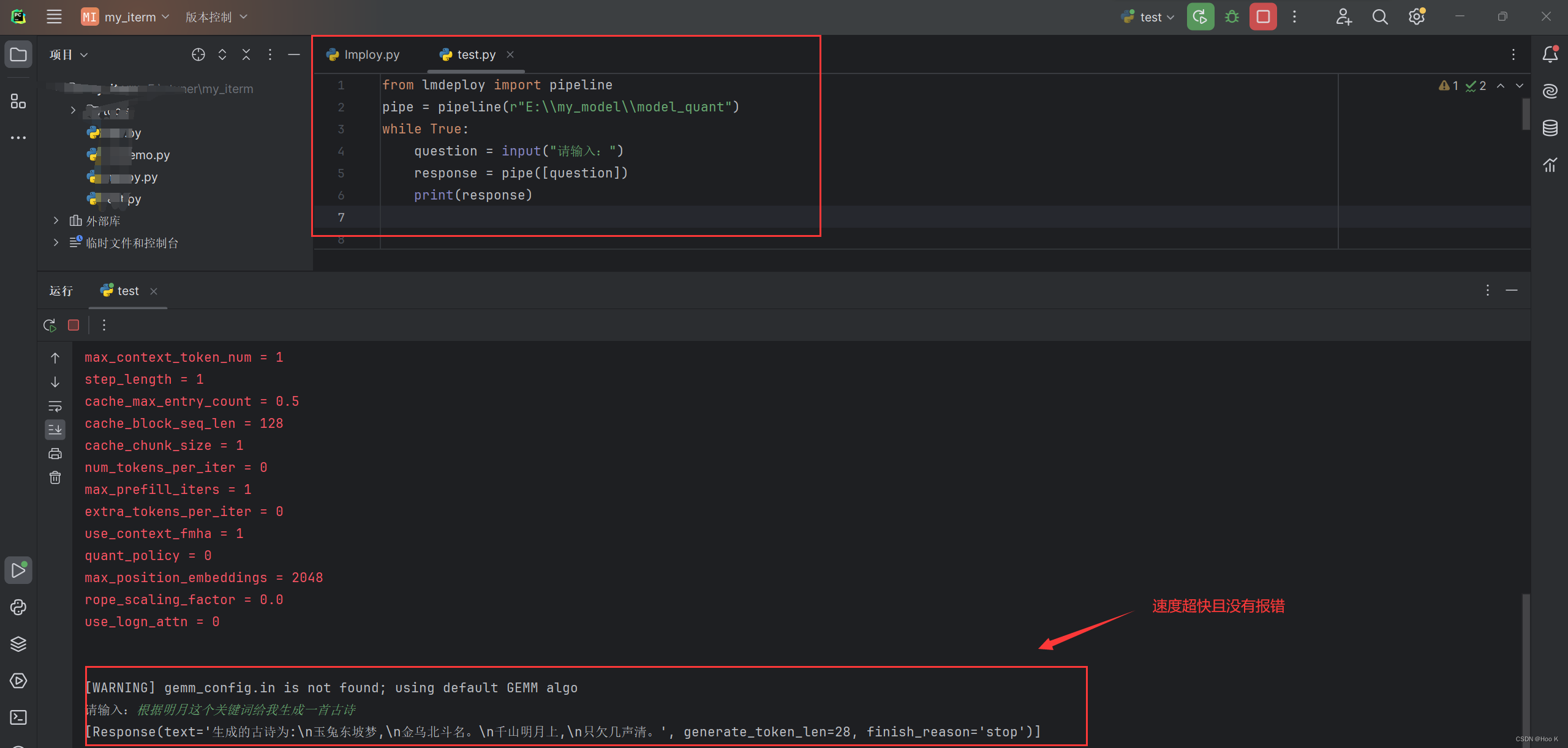


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









