







 本文详细介绍了动态规划的概念、原理,包括最优子结构、无后效性和子问题重叠,并通过最长公共子序列和最长上升子序列的经典例子展示了动态规划的应用。动态规划是一种通过解决子问题来求解复杂问题的方法,通过记忆化存储避免重复计算,提高效率。
本文详细介绍了动态规划的概念、原理,包括最优子结构、无后效性和子问题重叠,并通过最长公共子序列和最长上升子序列的经典例子展示了动态规划的应用。动态规划是一种通过解决子问题来求解复杂问题的方法,通过记忆化存储避免重复计算,提高效率。
目录
最长公共子序列(Longest Common Subsuqueue)
最长上升子序列(Longest Increasing Subsuqueue)
动态规划部分简介
本专栏将介绍动态规划(Dynamic Programming, DP)及其解决的问题。
动态规划是一种通过把原问题分解为相对简单的子问题的方式求解复杂问题的方法。
由于动态规划并不是某种具体的算法,而是一种解决特定问题的方法,因此它会出现在各式各样的数据结构中,与之相关的题目种类也更为繁杂。
在 OI 中,计数等非最优化问题的递推解法也常被不规范地称作 DP,因此本专栏将它们一并列出。事实上,动态规划与其它类型的递推的确有很多相似之处,学习时可以注意它们之间的异同。
动态规划基础
接下来,主要介绍了动态规划的基本思想,以及动态规划中状态及状态转移方程的设计思路,帮助各位对动态规划有一个初步的了解。
本专栏的其他部分,将介绍各种类型问题中动态规划模型的建立方法,以及一些动态规划的优化技巧。
引例
[USACO1.5] [IOI1994]数字三角形 Number Triangles

最简单粗暴的思路是尝试所有的路径。因为路径条数是级别的,这样的做法无法接受。
注意到一个基本事实,如果要走出最优路径,那么每一次的决策都应该是最优解。
以例题里提到的最优路径为例,只考虑前四步 7 -> 3 -> 8 -> 7,不存在一条以顶点为起点,以第 4 行第 2 个数为终点且具有比该路径更大权值的路径。
而对于每一个点,它的下一步决策只有两种:往左下角或者往右下角(如果存在)。因此只需要记录当前点的最大权值,用这个最大权值执行下一步决策,来更新后续点的最大权值。
这样做还有一个好处:我们成功缩小了问题的规模,将一个问题分成了多个规模更小的问题。要想得到从顶端到第 r 行的最优方案,只需要知道从顶端到第 r - 1 行的最优方案的信息就可以了。
这时候还存在一个问题:子问题间重叠的部分会有很多,同一个子问题可能会被重复访问多次,效率还是不高。解决这个问题的方法是把每个子问题的解存储下来,通过记忆化的方式限制访问顺序,确保每个子问题只被访问一次。
上面就是动态规划的一些基本思路。下面将会更系统地介绍动态规划的思想。
动态规划的原理
动态规划的原理有三个性质组成:最优子结构、无后效性、子问题重叠。
最优子结构
具有最优子结构也可能是适合用贪心的方法求解。
注意要确保我们考察了最优解中用到的所有子问题。
- 证明问题最优解的第一个组成部分是做出一个选择;
- 对于一个给定问题,在其可能的第一步选择中,假定你已经知道哪种选择才会得到最优解。你现在并不关心这种选择具体是如何得到的,只是假定已经知道了这种选择;
- 给定可获得的最优解的选择后,确定这次选择会产生哪些子问题,以及如何最好地刻画子问题空间;
- 证明作为构成原问题最优解的组成部分,每个子问题的解就是它本身的最优解。方法是反证法,考虑加入某个子问题的解不是其自身的最优解,那么就可以从原问题的解中用该子问题的最优解替换掉当前的非最优解,从而得到原问题的一个更优的解,从而与原问题最优解的假设矛盾。
要保持子问题空间尽量简单,只在必要时扩展。
最优子结构的不同体现在两个方面:
- 原问题的最优解中涉及多少个子问题;
- 确定最优解使用哪些子问题时,需要考察多少种选择。
子问题图中每个定点对应一个子问题,而需要考察的选择对应关联至子问题顶点的边。
无后效性
已经求解的子问题,不会再受到后续决策的影响。对应数学观念中的相关性(弱相关)。
子问题重叠
如果有大量的重叠子问题,我们可以用空间将这些子问题的解存储下来,避免重复求解相同的子问题,从而提升效率。
PS:通过记忆化的方式,或者说是用“超急评估”的思想,对问题的时间复杂度进行优化。
基本思路
对于一个能用动态规划解决的问题,一般采用如下思路解决:
- 将原问题划分为若干 阶段,每个阶段对应若干个子问题,提取这些子问题的特征(称之为 状态);
- 寻找每一个状态的可能 决策,或者说是各状态间的相互转移方式(用数学的语言描述就是 状态转移方程)。
- 按顺序求解每一个阶段的问题。
如果用图论的思想理解,我们建立一个 有向无环图,每个状态对应图上一个节点,决策对应节点间的连边。这样问题就转变为了一个在 DAG 上寻找最长(短)路的问题。
扯回正题
让我们把实现收束至引例。
我们的决策只有两种,向左下角或右下角前进。
我们不妨假设已经获得了第 r - 1 行的最优子结构(最大权值)。但是,我们现在不关心第 r - 1 行的最大全权值是如何获取的。
对于第 r 行的最优子结构(最大权值)只能通过两种决策产生。
关注到我们在计算机中存放数据时,并不能向金字塔一般。而应该像三角形一样,如下图。

所以,我们的状态转移方程便是:
dp[i][j] = max{dp[i-1][j] + nums[i][j], dp[i-1][j-1] + nums[i][j]};
同时,需要注意数组的“越界行为”,也就是边界情况的讨论。
其次,因为我们求取第 r 行的前提条件是获取了第 r - 1 行。同理,我们获取第 r - 1 行就需要先获取第 r - 2行。以此类推我们需要最先求解的是第1行。这对应着循环的顺序是从小到大的正向循环。
至于正确性证明,可利用反证法。不做过多解释,按照最优子结构中的步骤即可。
至此我们可以编码:
#include <iostream>
#include <vector>
#include <queue>
#include <algorithm>
int data[1000][1000];
int dp[1000][1000];
int main() {
int R;//R行数据
//读入
scanf("%d", &R);
for(int i = 0; i < R; ++i) {
for(int j = 0; j <= i; ++j) {
scanf("%d", &data[i][j]);
}
}
dp[0][0] = data[0][0];//初始化
for(int i = 1; i < R; ++i) {
for(int j = 0; j < R; ++j) {
dp[i][j] = data[i][j] + dp[i-1][j];
if(j - 1 >= 0) dp[i][j] = std::max(dp[i][j], data[i][j] + dp[i-1][j-1]);
}
}
int ans = dp[R-1][0];
for(int i = 1; i < R; ++i) {
if(ans < dp[R-1][i]) ans = dp[R-1][i];
}
printf("%d", ans);
return 0;
}经典历练
最长公共子序列(Longest Common Subsuqueue)
剑指 Offer II 095. 最长公共子序列(LCS问题)
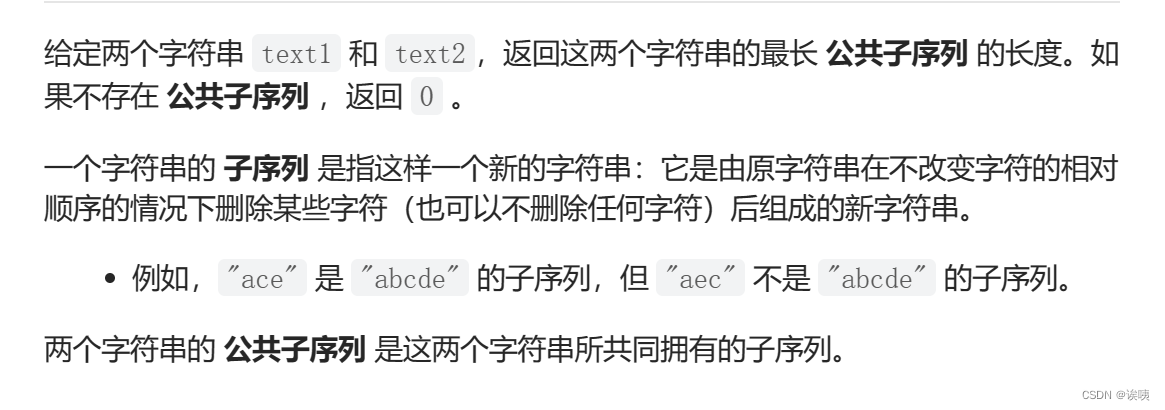

我们先以“abcde”和“ace”进行说明。这两个序列的公共子序列有"a","c","e","ac","ae","ce","ace",其中最长的子序列就是"ace",长度为3。
那么我们就知道了对于两个序列text1和text2,只有text1[i] == text2[j] 才会对公共子序列长度有贡献值。
所以,我们不妨规定 f(i, j) 表示 text1 的前 i 个字符和 text2 的前 j 个字符的最长公共子序列长度。这样,我们就表述出了子问题,而最终的答案就是f(n, m),其中n,m 分别对应了 text1 和 text2 的长度。
因为只有text1[i] == text2[j] 才会对公共子序列长度有贡献值。所以我们需要对text1[i] 和 text2[j] 的关系进行讨论
如果相等,自然是 f(i, j) = f(i - 1, j - 1) + 1。
如果不等,那么f(i, j)的状态并没有的产生新变化,而是继承前面的最大情况。这此时有两种决策:剔除test1[i] 或 text2[j];
所以我们可以获取到状态转移方程:
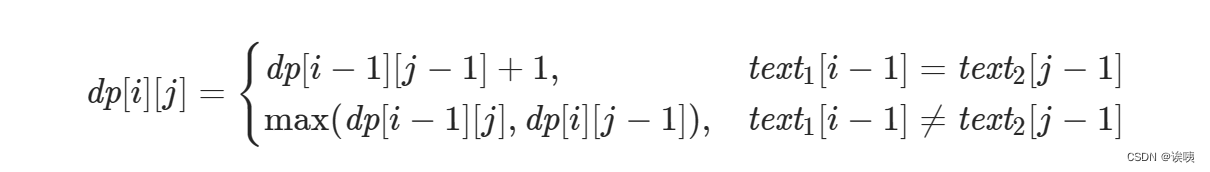
![]()
继而,我们可以设计代码:
class Solution {
public:
int longestCommonSubsequence(string text1, string text2) {
int n = text1.size(), m = text2.size();
vector<vector<int>> f(n + 1, vector<int>(m + 1, 0));
for(int i = 1; i <= n; ++i) {
for(int j = 1; j <= m; ++j) {
if(text1[i - 1] == text2[j - 1]) {
f[i][j] = f[i-1][j-1] + 1;
}
else {
f[i][j] = max(f[i-1][j], f[i][j-1]);
}
}
}
return f[n][m];
}
};
最长上升子序列(Longest Increasing Subsuqueue)
![]()
算法1:动态数组
我们知道对于一个递增子序列来说,其最后一个元素是最大的,那么如果有一个元素大于该值,则可以加入其中。
所以我们不妨假设 f(i) 是以 nums[i] 为最后一个元素的子序列的最大长度。
有注意到需要保护原数组中的下标有序性,即 j < i && nums[j] < nums[i], 那么我们可以将nums[i] 加入到以 nums[j] 为结尾的子序列当中。此时,f(i) = f(j) + 1。
因为,我们的 f(i) 存放的是最大的子序列长度。所以,我们需要遍历所有的j,j < i。找到其中满足执行策略产生的状态值,继而可以获取到最大值。因此,我们获得到了状态转移方程
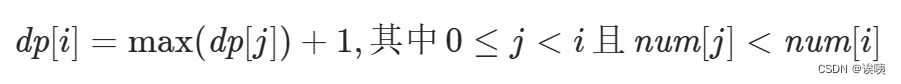
![]()
代码如下:
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int n = (int)nums.size();
if (n == 0) {
return 0;
}
vector<int> dp(n, 0);
for (int i = 0; i < n; ++i) {
dp[i] = 1;
for (int j = 0; j < i; ++j) {
if (nums[j] < nums[i]) {
dp[i] = max(dp[i], dp[j] + 1);
}
}
}
return *max_element(dp.begin(), dp.end());
}
};
算法2:静态数组
即便是相同的策略的,在不一样的角度和表述中,会有不一样的状态转移方程。
因为我们需要求取最长递增子序列长度len,我们不妨假设 f(len) 表示长度为 len 的子序列的最后一个元素。
如果我们发现,nums[i] > f(len), 那么 f(len + 1) = nums[i] 并且 len = len + 1。
但如果nums[i] <= f(len)呢?我们知道,为了让len尽可能长,那么 f(len) 应该尽可能小。所以,我们有了决策2:更新 f(len') , 其中 f(len') 是第一个 大于等于 nums[i] 的。
为了方便理解,我们给出一下的运行模拟图

![]()
故而有代码:
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int len = 1, n = nums.size();
vector<int> dp(n + 1, 0x3F3F3F3F);
dp[0] = nums[0];
for (int i = 1; i < n; ++i) {
if (nums[i] > dp[len - 1]) dp[len++] = nums[i];
else {
*lower_bound(dp.begin(), dp.begin() + len, nums[i]) = nums[i];
}
}
return len;
}
};
第二份:自己实现lower_bound
class Solution {
public:
int lengthOfLIS(vector<int>& nums) {
int len = 1, n = (int)nums.size();
if (n == 0) {
return 0;
}
vector<int> d(n + 1, 0);
d[len] = nums[0];
for (int i = 1; i < n; ++i) {
if (nums[i] > d[len]) {
d[++len] = nums[i];
} else {
int l = 1, r = len, pos = 0; // 如果找不到说明所有的数都比 nums[i] 大,此时要更新 d[1],所以这里将 pos 设为 0
while (l <= r) {//区间设计[l, r],寻找最大的小于nums[i]的位置pos
int mid = (l + r) >> 1;
if (d[mid] < nums[i]) {
pos = mid;
l = mid + 1;
} else {
r = mid - 1;
}
}
d[pos + 1] = nums[i];
}
}
return len;
}
};思考:如果是连续呢?
如果是连续的话,那就更加简单因为上述分析中的 j 便符合 j = i - 1。一旦 nums[i-1] >= nums[i]便意味着不符合题意。那么我们就可以重新设置起始点。
class Solution {
public:
int findLengthOfLCIS(vector<int>& nums) {
int ans = 0;
int n = nums.size();
int start = 0;
for (int i = 0; i < n; i++) {
if (i > 0 && nums[i] <= nums[i - 1]) {
start = i;
}
ans = max(ans, i - start + 1);
}
return ans;
}
};再思考:如果是不下降子序列的最大长度呢?
一样的分析过程,注意等号即可。再第二种方法中,我们只需要将lower_bound --> upper_bound即可。
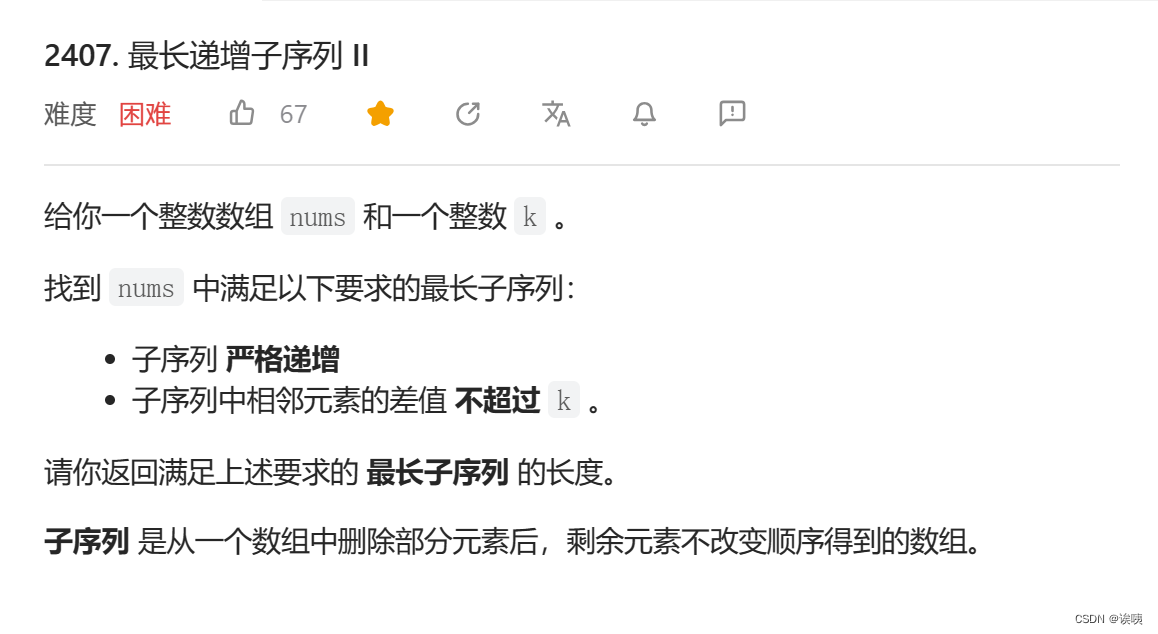
难度升级

![]()

![]()
PS:题目来源于洛谷P8776/2022年蓝桥杯省A G题
(听说数据有点弱,用正常的LIS也可以过关)
我们可以很快反应出来,这道题是LIS的题目,并且我们有方式求取 f(i) 。
PS:f(i) 表示以 nums[i] 为最后一个元素的最大不下降子序列长度。
但是,本题多了一点操作,就是我们需要将其中K个连续的区间内的数变为任意的同一个值。正是因为我们可以任意变换这个值。所以我们不需要关注它到底变成什么值,我们只需要关注它加在什么位置。
如果加入位置在末尾,ans = max{f(i)} + k。
如果加入位置在末尾,我们发现无法使用 f(i) 来进行表示。所以我们需要引入一个新概念。g(j) 表示以 nums[j] 为开头的最大子序列长度。所以此时 ans = k + max{g(j)}。
如果加入位置在中间,则有 ans = max { f(i) + k + g(j)},其中 j - i + 1 >= k。
我们发现,在LIS问题的过程中,我们有查询“前缀区间”、“更改单一值”的情况,而维护这个关系我们自然而然的会选择树状数组来维护。
那么问题来了,我们如何维护 g。因为 g(j) 以 nums[j] 为开始元素。而树状数组更适合查询“前缀区间”。故此我们不妨做一个变换,nums[M]' 到 nums[j]', 其中nums[M]' = 0, nums[j]' = M - nums[j] + 1。
当然,如果我们采用线段树来维护,那么我们可以不需要设计反转操作,但是需要专门对g进行设计。
所以,LIS问题是可以用树状数组维护的!!!
代码如下:
#include <bits/stdc++.h>
using namespace std;
const int N = 1e5 + 5, M = 1e6;
int n, k, a[N], f[N], g[N], c[M + 5];
//修改区间 将x位修改为k op:0--从[0, x] 1--[0, M - x + 1] 通过倒序处理g
inline void modify(int x, int k, int op) {
op && (x = M - x + 1);
while (x <= M) {
c[x] = max(c[x], k);
x += (x & -x);
}
}
//查询区间 查询(op:0--f, 1--g)对应x区间的值
inline int query(int x, int op) {
op && (x = M - x + 1);
int res = 0;
while (x) {
res = max(res, c[x]);
x -= (x & -x);
}
return res;
}
int main() {
cin.tie(NULL)->sync_with_stdio(false);//快速读入
cin >> n >> k;
for (int i = 1; i <= n; i++)
cin >> a[i];
int ans = k;
for (int i = 1; i <= n; i++) {
f[i] = query(a[i], 0) + 1;//更新f
modify(a[i], f[i], 0);//修改c数据
ans = max(ans, f[i]);
}
memset(c, 0, sizeof c);//重置c,避免之前f对g的影响
for (int i = n; i >= 1; i--) {
g[i] = query(a[i], 1) + 1;//更新g
modify(a[i], g[i], 1);//修改c数据
ans = max(ans, g[i]);
int pos = i - k - 1;
if (pos >= 1)
ans = max(ans, f[pos] + k + query(a[pos], 1));
}
//另外两种策略
for (int i = 1; i + k <= n; i++)
ans = max(ans, f[i] + k);
for (int i = k + 1; i <= n; i++)
ans = max(ans, g[i] + k);
cout << ans << '\n';
return 0;
}

![]() 编辑
编辑

![]()
这道题就很有意思,反应了许多设计细节。
1.因为这对查询范围提出要求,所以动态数组并不优于静态数组。所以,我们可以开一个静态数组
2.因为是单值更新,所以我们不需要一个额外数组来维护区间公共操作值,或者懒惰更新。
3.注意查询界限,例如此题查询下界为1。
4.因为这里涉及区间查询,而不是简单的前缀查询,所以采用线段树维护。
5.整体算法思路仍然采用正常的LIS算法2。
const int N = 1e5;
class Solution {
public:
int myTree[N * 4];//开静态数组
//更新对区间[l, r] 编号pos区间[start, end]更新为val
void update(int pos, int start, int end, int l, int r, int val) {
if (l <= start && end <= r) {//编号区间被包含
myTree[pos] = val;
return;
}
int m = (start + end) >> 1;
if (l <= m) update(pos * 2 + 1, start, m, l, r, val);
if (r > m) update(pos * 2 + 2, m + 1, end, l, r, val);
myTree[pos] = max(myTree[pos * 2 + 1], myTree[pos * 2 + 2]);
}
//查询
int query(int pos, int start, int end, int l, int r) {
if (l <= start && end <= r) return myTree[pos];
int m = (start + end) >> 1, ret = 0;
if (l <= m) ret = max(ret, query(pos * 2 + 1, start, m, l, r));
if (m < r) ret = max(ret, query(pos * 2 + 2, m + 1, end, l, r));
return ret;
}
int lengthOfLIS(vector<int>& nums, int k) {
for (int& i : nums) {
if (i == 1) update(0, 1, N, i, i, 1);
else {
int tmpRet = 1 + query(0, 1, N, max(1, i - k), i - 1);
update(0, 1, N, i, i, tmpRet);
}
}
return myTree[0];
}
};![]()

你需要知道的一些“结论”:
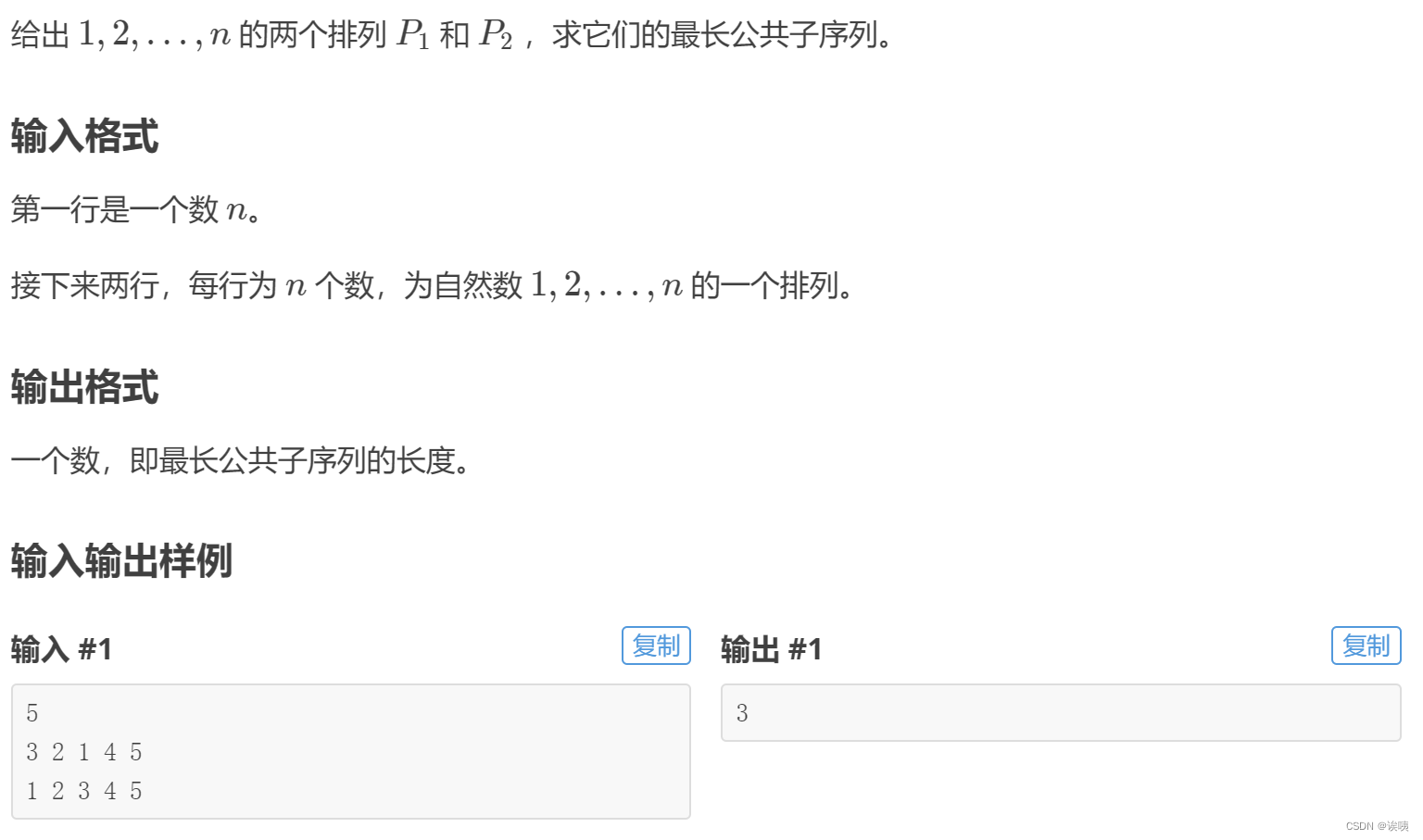
1. LCS 转为 LIS 的前提是两个序列是异位的,即仅仅是相同元素的位置不同。
2. LCS 中 两个序列是异位的,并且其中一个是递增的,那么求取LCM 等价于 求取另一个序列的LIS。
我们发现此时两个序列是异位的。所以,我们可以将其转至LIS问题从而得以求解。那么问题来了如何转换?
由结论2,我们可以知道。我需要一个递增数列!但是该如何变换递增呢?
假设我们拥有两个序列 A 和 B。
A:3 2 1 4 5
B:1 2 3 4 5
我们不妨给它们重新标个号:把3标成a,把2标成b,把1标成c……于是变成:
A: a b c d e
B: c b a d e
经过重新编号,我们的序列便成了递增数列,接下来,我们求取 B 的 LIS 即可。
#include<iostream>
#include<cstdio>
using namespace std;
int a[100001],b[100001],map[100001],f[100001];
int main()
{
int n;
cin>>n;
for(int i=1;i<=n;i++){scanf("%d",&a[i]);map[a[i]]=i;}//读入a,同时重新编号成递增数列
for(int i=1;i<=n;i++){scanf("%d",&b[i]);f[i]=0x7fffffff;}//读入b,并初始化f
int len=0;//初始化len
f[0]=0;//至此完全初始化完f
for(int i=1;i<=n;i++)
{
int l=0,r=len,mid;
if(map[b[i]] > f[len])f[++len]=map[b[i]]; //当重新编号后的b > f[len] 加入
else//更新相应的f
{
while(l<r)//区间设计(l, r], upper_bound;
{
mid=(l+r)/2;
if(f[mid] > map[b[i]])r=mid;//r -- 大于
else l=mid+1;
}
f[l]=min(map[b[i]],f[l]);// l == r 所以标记的是大于
}
}
cout<<len;
return 0
}PS:因为这道题一个序列内部不存在重复元素,所以使用lower_bound还是upper_bound都无伤大雅。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









