







就此告一段落
花了整整七天时间终于把《黑马点评》项目实战篇全部学完了,每天大概学八九个小时左右,中途也是遇到很多问题,困难重重,虽说学了就忘了但是会查会用就行嘿嘿。笔记我做的很随便,时间太紧了且内容太多了所以不会像以前一样认真做笔记了。具体完整笔记可看大神的这一篇:https://blog.youkuaiyun.com/RuanFun/article/details/137594801?spm=1001.2014.3001.5502
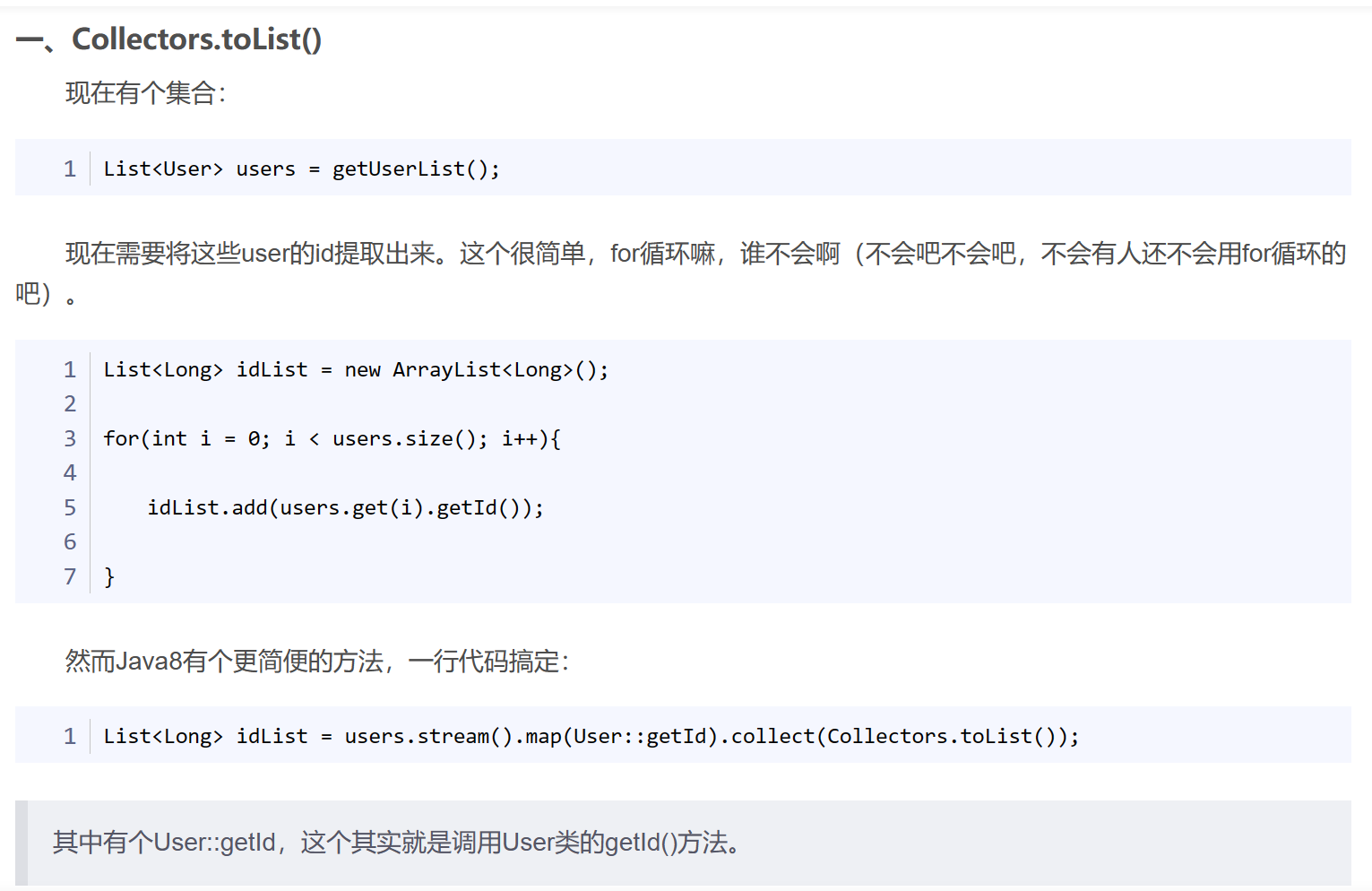
java8 stream().map().collect()的Collectors.toList()、Collectors.toMap()、Collectors.groupingBy()的用法
关注和取关 共同关注
MyBatis-Plus 框架中QueryWrapper基本用法
https://blog.youkuaiyun.com/weixin_45266691/article/details/135752963
灵活的 QueryWrapper
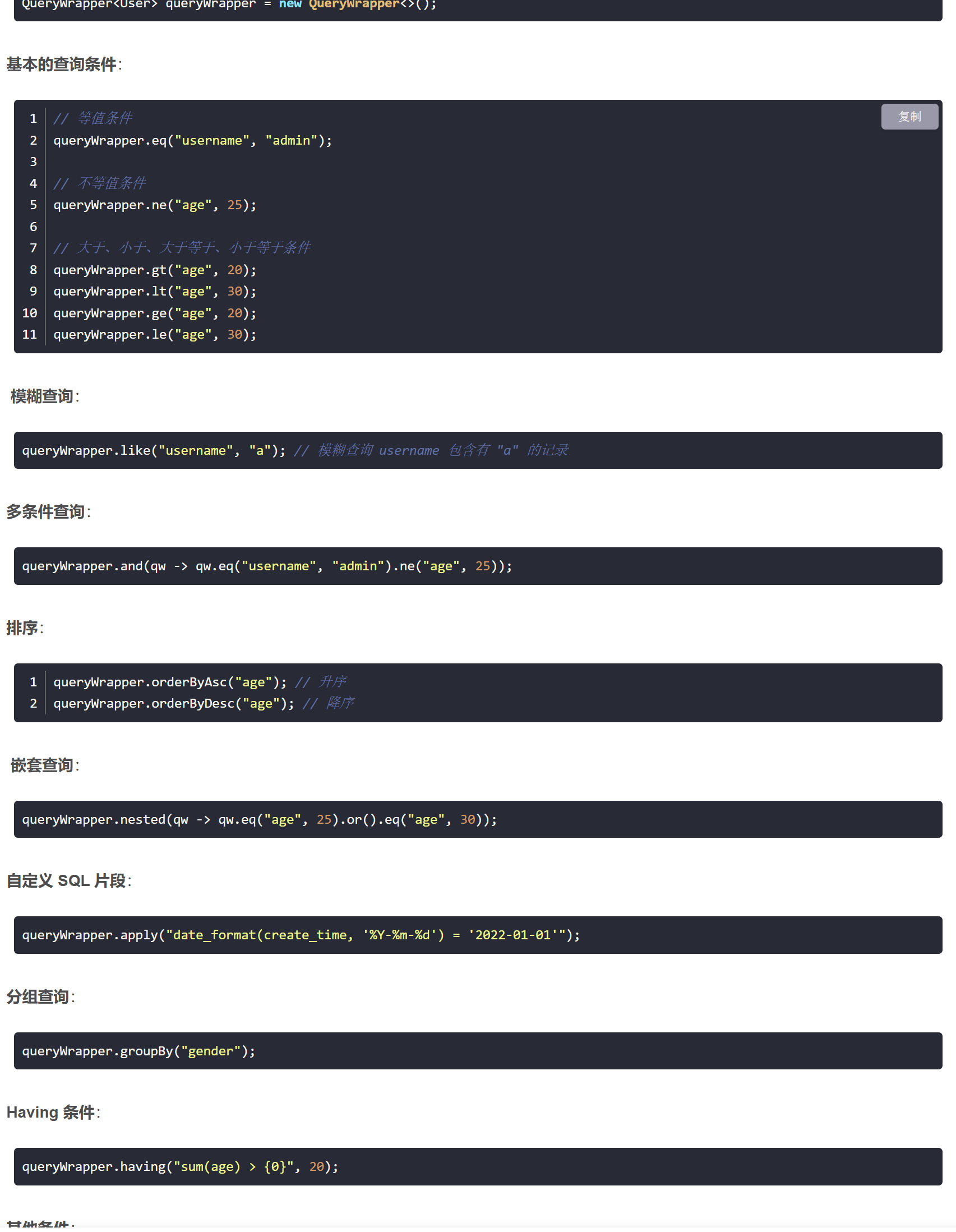
https://mybatis-flex.com/zh/base/querywrapper.html
具体实现
//修改:主要在关注时把被关注用户的id放入redis,取关时从redis中移除id:
@Override
public Result follow(Long followUserId, Boolean isFollow) {
//获取登录用户
Long userId = UserHolder.getUser().getId();
String key = "follows:" + userId;
//1.判断是关注还是取关
if(isFollow){
//2.关注,新增数据
Follow follow = new Follow();
follow.setUserId(userId);
follow.setFollowUserId(followUserId);
boolean isSuccess = save(follow);
if(isSuccess){
//把关注用户的id放入redis的set集合
stringRedisTemplate.opsForSet().add(key,followUserId.toString());
}
}else{
//3.取关,删除记录
boolean isSuccess = remove(new QueryWrapper<Follow>()
.eq("user_id", userId).eq("follow_user_id", followUserId));
if(isSuccess){
//把关注用户的id从Redis移除
stringRedisTemplate.opsForSet().remove(key,followUserId.toString());
}
}
return Result.ok();
}
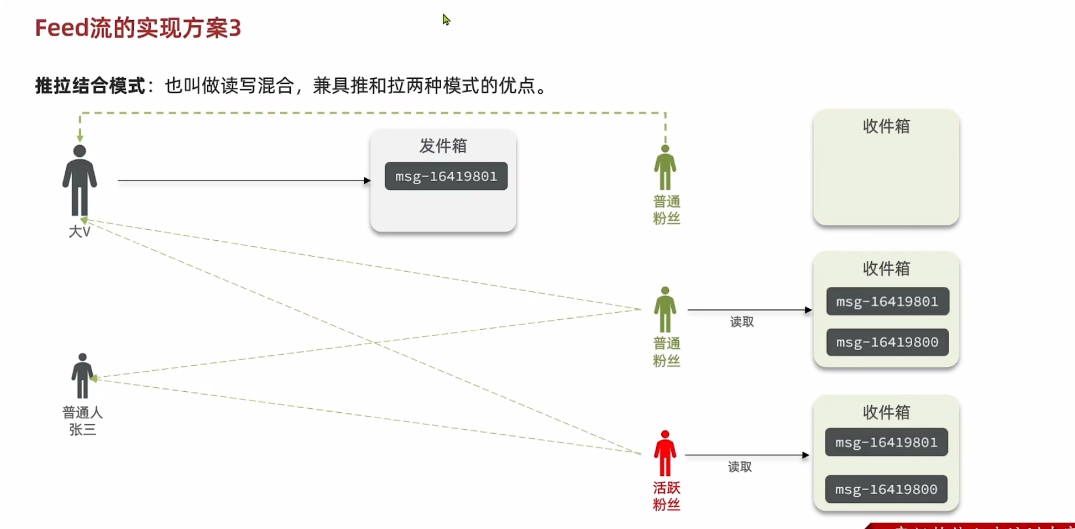
要实现分页查询要指定page和size,计算从哪里开始到哪里结束。
List有角标,SortedSet有排名。 推荐使用SortedSet
滚动分页查询
滚动查询:每一次查询都记住上一次查询的最小值是谁,将最小值作为下一次的最大值,这样就能避免重复查询
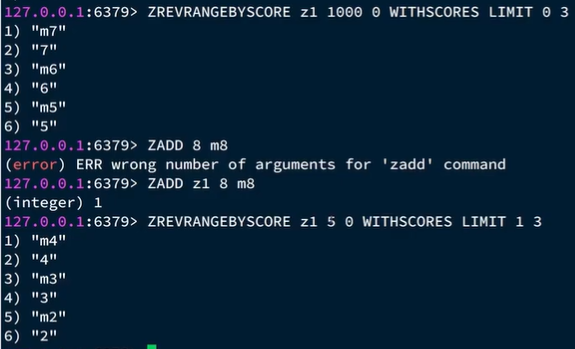
规律:分数最小值和查的数量固定不变。最大值为上一次查询的最小值、偏移量第1次给0,第1次后给在上一次的结果中,与最小值一样的元素的个数。
当分数一致出现问题
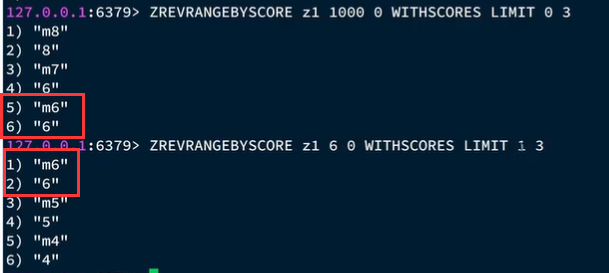
score范围进行查询,记住最小的时间戳,下次找比这个更小的时间戳。
滚动分页查询参数:
max:第一次:当前时间戳 接下来的:上一次查询的最小值
min:永远是0
offset偏移量:第一次:0 在上一次的结果中,与最小值一样的元素个数
count:3
分数最小值和查的数量固定不变。最大值为上一次查询的最小值、偏移量第1次给0,第1次后给在上一次的结果中,与最小值一样的元素的个数。
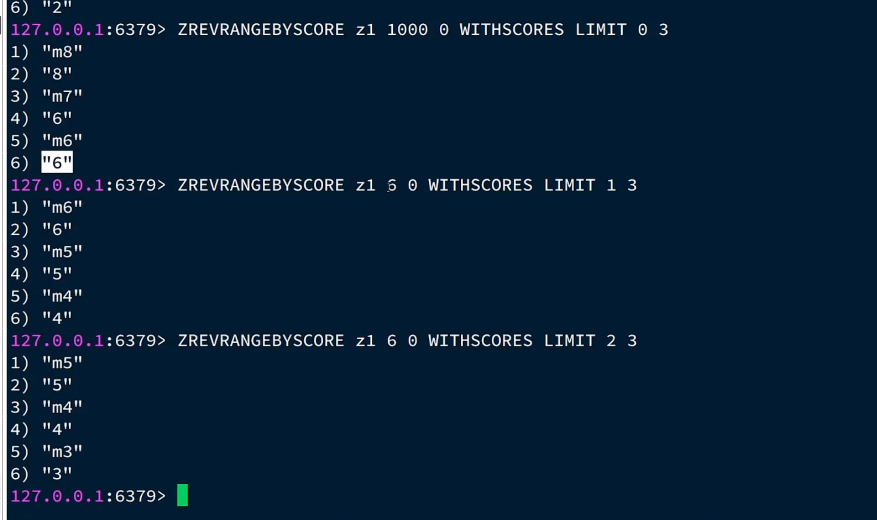
看图:
最小值6有了,下一次查询的时候做最大值;跟6一样的有2个,则下一次查询的offset为2,上一次查询分析出来的信息就作为下一次查询的参数。则每一次查询返回包含三部分:
minTime:本次查询的推送的最小时间戳**(最后面那个不是最小的那个)**
offset:和最小时间戳值一样的那些时间戳的个数!!!
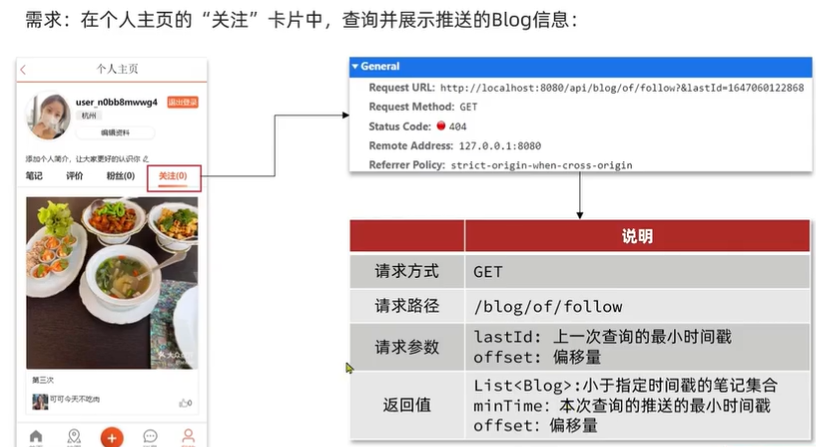
List 小于指定时间戳的笔记集合
元组(tuple)是关系数据库中的基本概念,是数据库中的一种数据结构。 在关系数据库中,数据以表格的形式存储,每个表格称为一个关系(relation),而表格中的每一行称为一个元组(tuple)。 元组是关系数据库中的基本单位,它代表了数据库中的一条记录。
ZSetOperations 操作接口
https://www.hxstrive.com/subject/spring_data_redis/1793.htm

实现滚动分页查询逻辑
@Override
public Result queryBlogOfFollow(Long max, Integer offset) {
//获取当前用户 之后得到它的id
Long userId = UserHolder.getUser().getId();
//然后查询收件箱 zrevrangebyscore key max min limit offset count
//查询出来的有点多 解析数据
String key = FEED_KEY + userId;
Set<ZSetOperations.TypedTuple<String>> typedTuples = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
//非空判断
if (typedTuples == null ||typedTuples.isEmpty()){
return Result.ok();
}
//3.解析数据:blogId、minTime(时间戳)、offset
ArrayList<Long> ids = new ArrayList<>(typedTuples.size());
/*
遍历ZSetOperations集合先拿到第一个,然后把它赋值给minTime,然后遍历第二个,又赋值,最后一个一定是这个最小时间戳
*/
long minTime = 0;
/*
offset怎么求 涉及到算法
*/
int os = 1;
for (ZSetOperations.TypedTuple<String> tuple : typedTuples){
//
//4.1.获取id
String idStr = tuple.getValue();
ids.add(Long.valueOf(idStr));
//4.2.获取分数(时间戳)
long time = tuple.getScore().longValue();
if (time == minTime){
os++;
}else {
minTime = time;
os = 1;
}
}
//根据id查询blog 和上面 根据用户id查询用户差不多
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query()
.in("id",ids).in("id", ids)
.last("ORDER BY FIELD(id," + idStr + ")").list();
//再补充上一点才完整
for (Blog blog : blogs) {
isBlogLiked(blog);
User user = userService.getById(blog.getUserId());
blog.setName(user.getNickName());
blog.setIcon(user.getIcon());
}
//封装并返回
ScrollResult r = new ScrollResult();
r.setList(blogs);
r.setOffset(os);
r.setMinTime(minTime);
return Result.ok(r);
}

















 1140
1140

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









