






往期推荐
MySQL三大日志_mysql 大事务 回滚 记录binlog吗-优快云博客
符号引用和直接引用、强引用、软引用、弱引用、虚引用-优快云博客
1. 聚簇索引和二级索引
innodb使用b+树作为索引数据结构。在创建表时,InnoDB 默认会创建一个主键索引,也就是聚簇索引,而其它索引都属于二级索引。
值得一提的是,InnoDB和MyISAM都支持B+树索引,但是它们数据的存储结构实现方式不同。InnoDB存储擎的B+树索引的叶子节点保存数据本身(图1),MylSAM存储引擎的B+树索引的叶子节点保存数据的物理地址(图2);
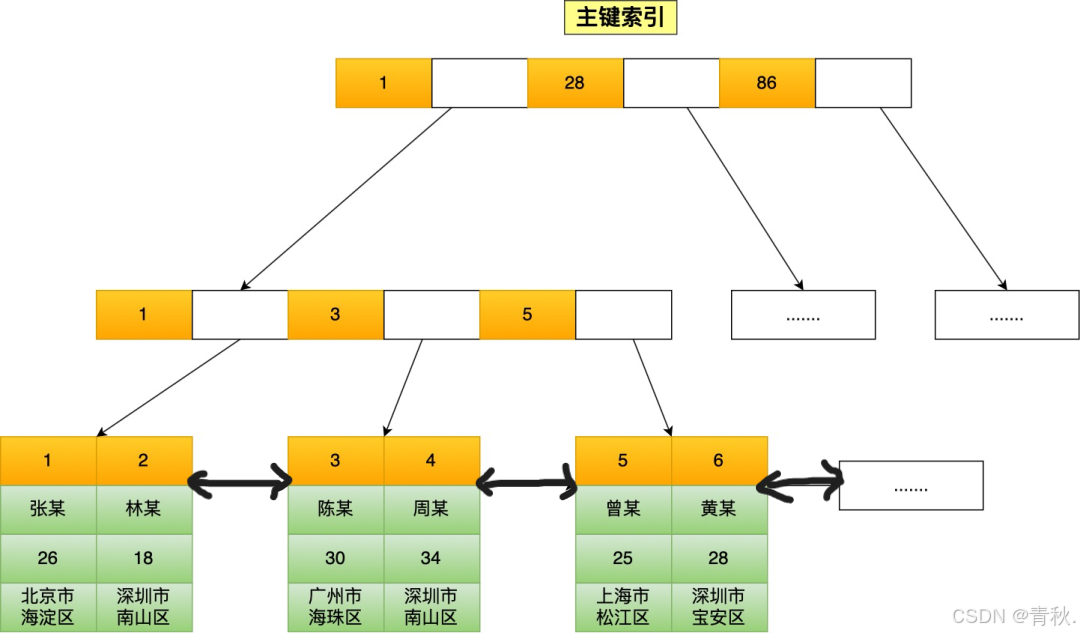
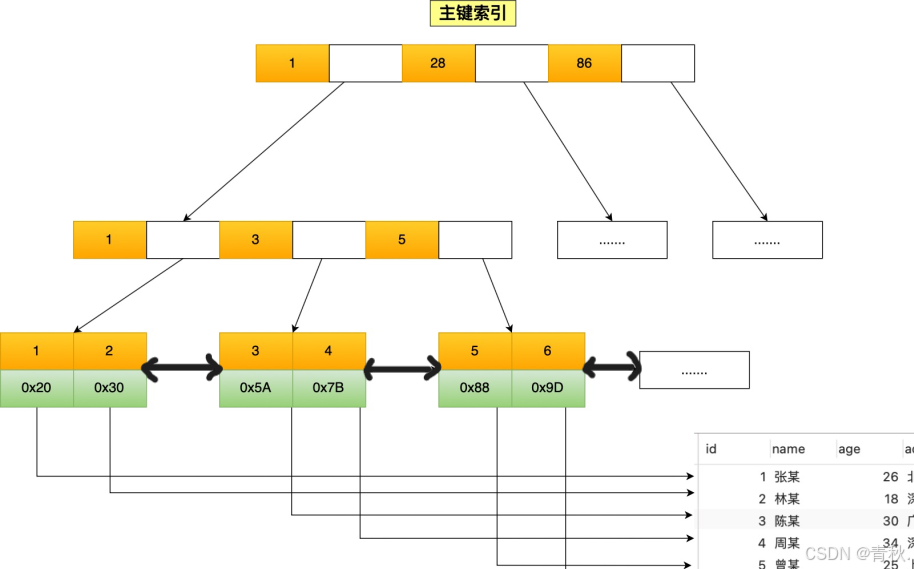
InnoDB存储引擎根据索引类型不同,分为聚簇索引(图1)和二级索引。区别在于,聚簇索引的叶子节点存放的是实际数据,所有完整的用户数据都存放在聚簇索引的叶子节点,而二级索引的叶子节点存放的是主键值,而不是实际数据。如果将 name 字段设置为普通索引,那么这个二级索引长下图这样
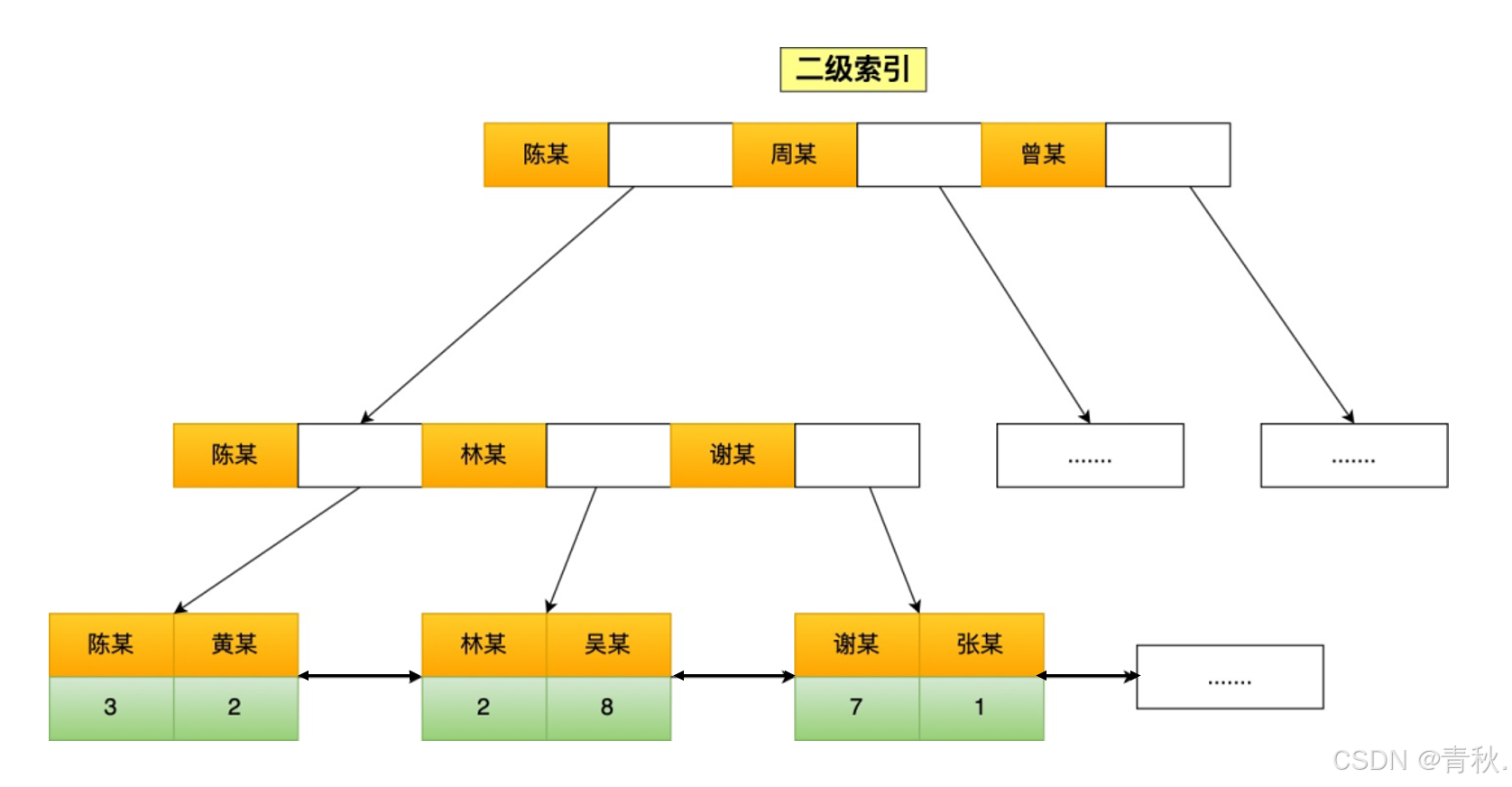
2. 回表和索引覆盖
- 使用主键索引作为条件查询时,如果查询的数据都在聚簇索引的叶子节点(图1),那么就直接在叶子节点读取到要查询的数据,比如select * from user where id=1 (id是主键索引)
- 使用二级索引字段作为条件查询时,如果要查询的数据都在聚簇索引的叶子节点里,那么需要检索两颗B+树:
先在二级索引的B+树找到对应的叶子节点,获取主键值(图3),然后用获取的主键值,在聚簇索引中的B+树检索到对应的叶子节点(图1),然后获取要查询的数据。这个过程叫做回表,如select * from user where name="林某"(name是二级索引)- 使用二级索引字段作为条件查询时,如果要查询的数据在二级索引的叶子节点(图3),那么只需在二级索引的 B+ 树找到对应的叶子节点,然后读取要查询的数据,不需要用到主键索引,这个过程叫做覆盖索引。如select id from user where name="林某"(name是二级索引,id正好存在于二级索引中)
3. 索引失效场景
3.1 like %xx或like %xx%
因为索引 B+ 树是按照「索引值」有序排列存储的,只能根据前缀进行比较。对索引使用左或左右模糊匹配,此时会走二级索引的全表扫描
3.2 对索引使用函数
select * from user where length(name)=3(name是二级索引),因为索引保存的是索引字段原始值,而不是经过函数计算后的值,自然就没办法走索引了而是全表扫描。
不过,从MySQL8.0开始,索引特性增加了函数索引,可以针对函数计算后的值建立一个索引,也就是说该索引的值是函数计算后的值,所以就可以通过扫描索引来查询数据。
3.3 对索引表达式计算
select * from from where id +1=10会走全表扫描,因为索引保存的是索引字段的原始值,而不是 id + 1 表达式计算后的值,而select * from from where id = 10 -1则会走索引查询。
3.4 对索引隐式类型转换
如果索引字段是字符串类型,但是在条件查询中,输入的参数是整型的话就会走全表扫描,而如果反过来,索引字段是整型,查询参数是字符串,此时会走索引,因为mysql在字符串和整型比较时会自动把字符串变成数字,所以字符串类型的索引,在使用整型参数查询时,还得把字符串索引变成整型才行,也就相当于调用了函数。
3.5 联合索引不满足最左匹配
对主键字段建立的索引叫做聚簇索引,对普通字段建立的索引叫做二级索引。那么多个普通字段组合在一起创建的索引就叫做联合索引(组合索引),在使用联合索引时要遵循最左匹配,比如创建联合索引(a,b,c),查询时where b=1;where c=3;where b=2 and c=3;这三种情况都会使联合索引失效。
有一个比较特殊的查询条件:where a > 1and c = 3,这属于索引截断,不同版本处理方式也不一样。MySQL5.5的话,前面a会走索引,在联合索引找到主键值后,开始回表,到主键索引读取数据行交给Server层,在Server层再比对c字段的值。从MySQL5.6之后,有一个索引下推,即在存储引擎层进行索引遍历时,对索引中包含的字段先做判断(a和c都在索引中),直接过滤掉不满足条件的记录,再返还给Server层,从而减少回表次数。
索引下推原理
截断的字段不会在Server层进行条件判断,而是会被下推到「存储引擎层」进行条件判断(因为c字段的值是在(a,b,c)联合索引里的),然后过滤出符合条件的数据后再返回给Server层。由于在引擎层就过滤掉大量的数据,无需再回表读取数据来进行判断,减少回表次数,从而提升了性能。
没索引下推:存储引擎先定位到第一条a>1的数据,然后拿着其主键去回表,读取出数据给server层,然后server层判断是否满足c=3,来决定是否给客户端,然后存储引擎重复上面操作,反复回表。
有索引下推: 就直接在存储引擎层过滤,减少回表操作。
联合索引的匹配遵循 最左前缀原则,且 从最左列开始按顺序匹配。当遇到第一个范围查询时,后续列的索引将不再生效;而等值查询则允许后续列继续匹配索引,直到遇到范围查询为止。
3.6 where中使用or
在 WHERE 子句中,如果 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效。因为 OR 的含义就是两个只要满足一个即可,因此只有一个条件列是索引列是没有意义的,只要有条件列不是索引列,就会进行全表扫描
3.7 两个索引列做比较
MySQL的索引(如B+Tree索引)是按列值单独排序的。每个索引独立存储某列的值及其行位置(ROWID)。当比较两列时:
若使用
column1的索引,只能快速定位到column1的特定值,但无法直接关联到column2的值。同理,column2的索引也无法关联到column1的值。优化器无法通过索引直接找到满足column1 = column2的行,只能通过全表扫描逐行比较。
3.8 不等于比较
3.9 is not null
3.10 not in和not exists
查询条件使用not in时,如果是主键索引则走索引,如果是普通索引,则索引失效。
3.11 order by
对索引order by导致全表排序


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









