







 超级会员免费看
超级会员免费看
 该实验报告详细介绍了数字示波器的使用,包括实验目的、原理,以及操作步骤和数据处理过程。通过对实验数据的分析,得出结论并进行了深入的讨论。同时,报告还包含了思考题和原始数据记录,为理解物理现象提供了实践依据。
该实验报告详细介绍了数字示波器的使用,包括实验目的、原理,以及操作步骤和数据处理过程。通过对实验数据的分析,得出结论并进行了深入的讨论。同时,报告还包含了思考题和原始数据记录,为理解物理现象提供了实践依据。
1.实验目的及实验原理
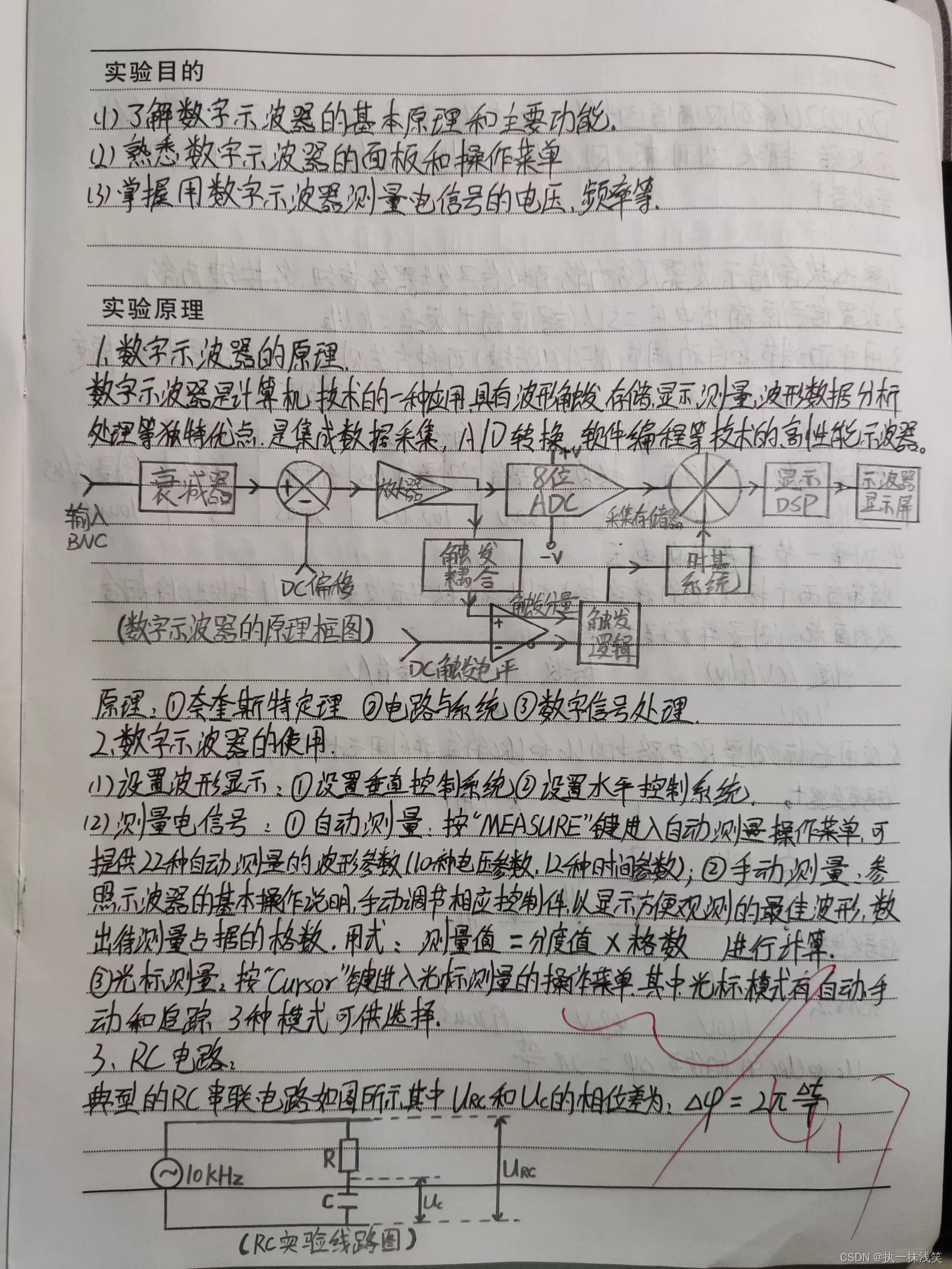
2.实验仪器,实验步骤及数据处理

3.实验数据处理

4.实验结论及实验讨论

1.实验目的及实验原理
2.实验仪器,实验步骤及数据处理
3.实验数据处理
4.实验结论及实验讨论
 5万+
349
5212
806
2782
1万+
5万+
349
5212
806
2782
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























