







说明:本文采用了一个三层 BP 网络来拟合 s i n ( x ) sin(x) sin(x) 和其他的一些简单函数,并且训练集和测试集都是生成的随机数,在拟合更加复杂的模型时需要进行相应的数据预处理、正则化或归一化操作,同时调整网络的超参。
一、BP 网络原理简介
什么是 BP 网络?
人工神经网络可以通过自身的训练,寻找并学习训练集中给定输入值和期望输出值之间的关系,从而总结出某些规则,并以此在应用过程中根据用户的输入得到一个合适的输出值。这些规则可以是为我们所知的,也有可能是未知的,神经网络的训练过程是一个黑盒操作,我们通过损失函数的变化、网络在测试集上的表现等等来判断一个网络的优劣。
BP 网络通过前向计算、反向传播两个简单的过程,利用梯度下降方法,逐步更新网络中的参数矩阵,从而实现对函数的拟合等其他任务。下图是一个三层神经网络的基本结构。
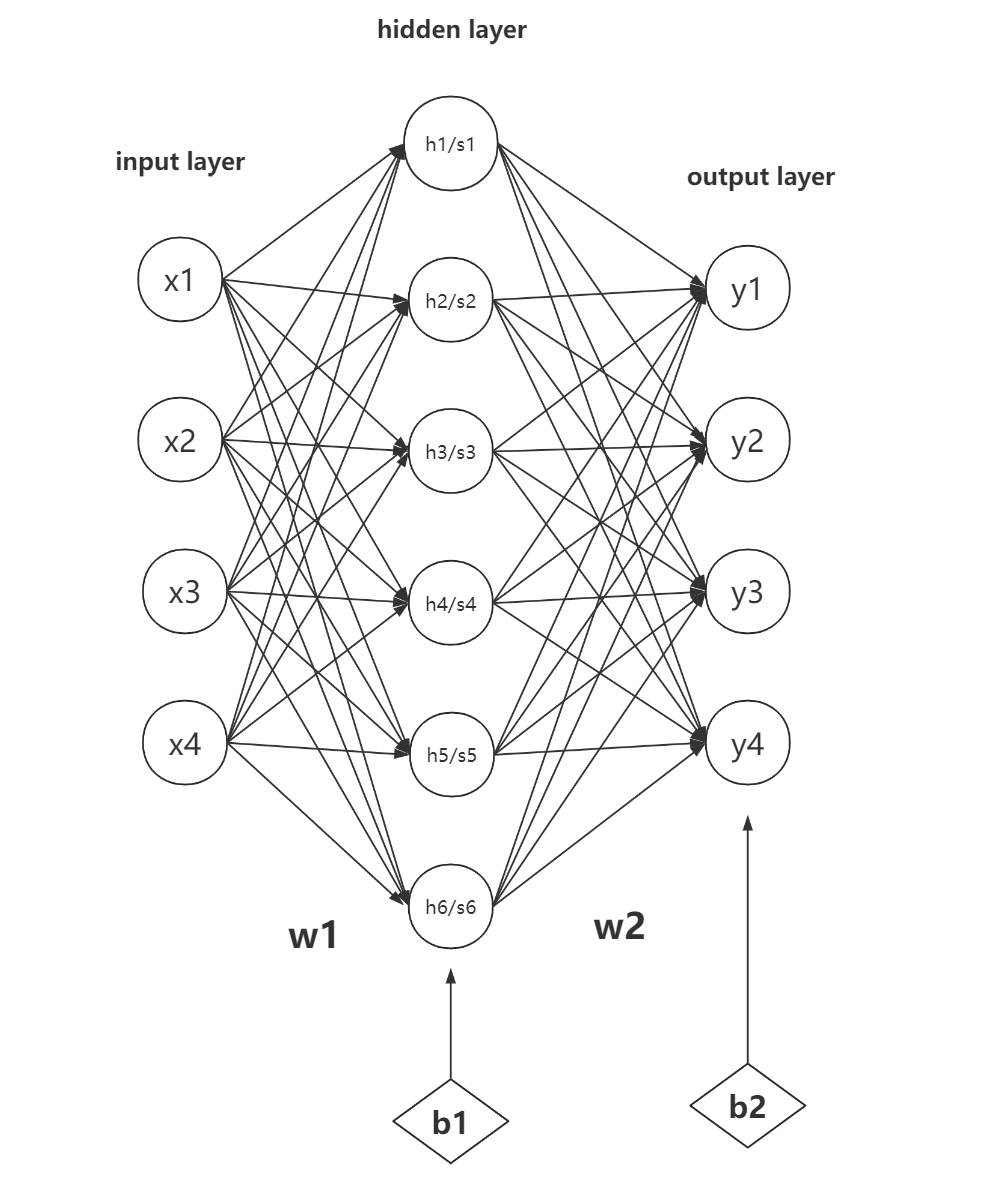
- input layer:输入层,可以输入一个向量。
- hidden layer:隐藏层/中间层,用来扩展输入向量的维度,对输入向量中蕴含的信息进行重排与组合,并在后面的反向转播过程中改进自己的组合方式以学习到我们期望的规律。hidden layer 可以不止一层,但是层数过多可能会出现梯度消失等问题。
- output layer:输出层。
BP 网络数学原理推导
前向计算过程:
在前向传播过程中,我们需要将输入的向量乘以一个变换矩阵来实现线性组合,该矩阵也可以称为权重矩阵,因为该矩阵中的数字代表了输入层中相应神经元蕴含的信息在变化过程中的重要程度。
以 h1 为例, h 1 = x 1 w 11 + x 2 w 21 + x 3 w 31 + x 4 w 41 h_1 = x_1w_{11}+x_2w_{21}+x_3w_{31}+x_4w_{41} h1=x1w11+x2w21+x3w31+x4w41,从这个式子中很容易看出 w 的权重作用。
应用到所有神经元,我们有:
h = x ⋅ w 1 \boldsymbol h = \boldsymbol x · \boldsymbol w_1 h=x⋅w1
由于该组合是线性的,这意味着神经网络中的数据与输入始终都是线性关系,这就无法实现非线性函数的拟合。因此我们需要加一个激活函数 sigmoid,用来将线性数据转换为非线性。同时在做 sigmoid 操作之前需要加上一个偏置向量 b1 来提高拟合模型的灵活性。
s i g m o i d : σ ( x ) = 1 1 + e − x sigmoid:\sigma(x) = {1\over 1+e^{-x}} sigmoid:σ(x)=1+e−x1
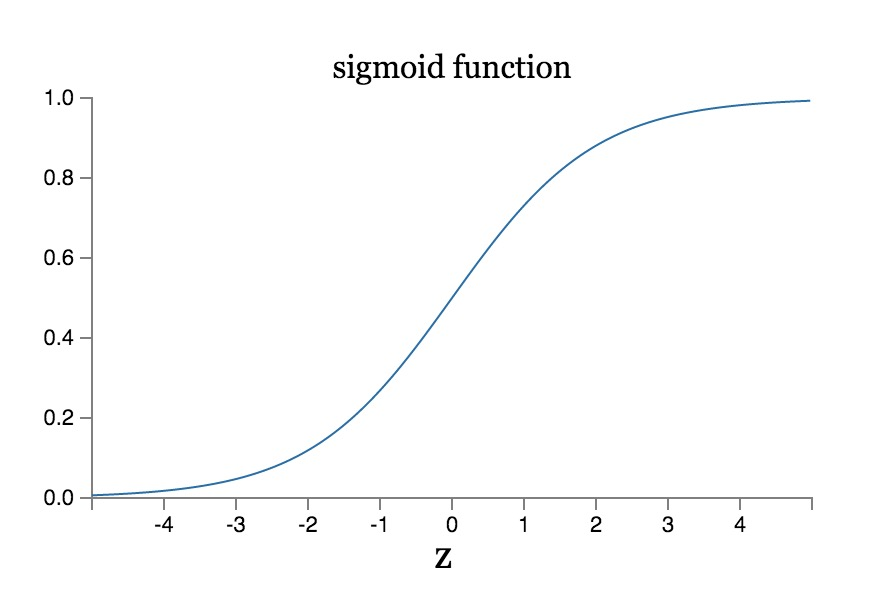
sigmoid 函数也具有一个很好的特性: σ ′ ( x ) = σ ( x ) [ 1 − σ ( x ) ] \sigma^{'}(x) = \sigma(x)[1-\sigma(x)] σ′(x)=σ(x)[1−σ(x)],这一点将会为后续梯度下降过程中的计算带来便利。
回到前向传播过程上来,我们有:
s = s i g m o i d ( h + b 1 ) \boldsymbol s = sigmoid(\boldsymbol h + \boldsymbol b_1) s=sigmoid(h+b1)
对 hidden layer 做相似的操作,只不过这次由升维改为了降维:
y = s ⋅ w 2 + b 2 \boldsymbol y = \boldsymbol s · \boldsymbol w_2 + \boldsymbol b_2 y=s⋅w2+b2
注意到输出层不要 sigmoid,因为 sigmoid 会把所有的负值转换成正值,显然没法拟合 s i n ( x ) sin(x) sin(x) 这种有负值的函数。
这样我们就得到了输出的向量。接下来就是根据输出与期望输出之间的差值来调整网络中的权重矩阵。
反向传播过程:
如何量化网络的输出与我们期望输出之间的差值?我们可以用 MSE(均方误差) 来定义损失函数。
MSE: l o s s = Σ 1 2 ( d i − y i ) 2 loss = \Sigma \frac12(d_i- y_i)^2 loss=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 7195
7195

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











