



 本文探讨了如何将自监督学习应用于自动驾驶运动预测,提出SSL-Lanes方法,通过四个前置任务结合多任务学习,提高模型的精度、泛化能力和推理效率。实验结果显示在复杂驾驶行为预测上效果优于传统方法。
本文探讨了如何将自监督学习应用于自动驾驶运动预测,提出SSL-Lanes方法,通过四个前置任务结合多任务学习,提高模型的精度、泛化能力和推理效率。实验结果显示在复杂驾驶行为预测上效果优于传统方法。
目录
6. Forecasting Success/Failure Classification
论文中文题目:自动驾驶中运动预测的自监督学习
一、背景
在现实世界的城市环境中进行运动预测是自主机器人的一项重要任务,包括预测车辆和行人在内的交通主体的未来轨迹,这对于自动驾驶领域的安全、舒适和高效操作来说绝对至关重要。
运动预测任务传统上是基于运动学约束和具有手工规则的道路地图信息,然而这些方法无法捕捉复杂场景中的长期行为以及与地图结构和其他交通代理的交互。
同时要想实现这些是一个非常具有挑战性的问题。
困难包括驾驶行为的多模态,以及未来的运动可能涉及复杂的机动动作,如换车道、转弯、加速或减速等。
数据驱动的运动预测方法已经取得了巨大的进展。最近的方法使用矢量表示高清地图和智能体轨迹,包括Lane-GCN、Lane-RCNN、TNT等方法。最近,Transformer取得了巨大成功
如transformer、 Multimodal transformer等。
这些方法存在的问题是:架构复杂,推理速度慢,不适合现实世界的设置。
所以考虑到了自监督学习SSL。
自监督学习(SSL)已经成功应用于CNN和GNN中,可以实现高可迁移、泛化性和鲁棒性。但是在自动驾驶运动预测方向的探索工作却比较少。论文首次将自监督学习运用于运动预测,方法名为SSL-Lanes。
二、论文结构
首先证明了将自监督学习纳入运动预测的有效性,然后根据运动预测问题的性质提出了四个前置任务,最后通过设计实验进行验证。
三、数据集
Argoverse提供了一个大规模的数据集,用于训练、验证和测试模型,该数据集任务是在给定2秒的过去观察值的情况下,预测3秒的未来运动。这个数据集有超过30K个在迈阿密(MIA)和匹兹堡(PIT)收集的真实世界驾驶序列。这些序列进一步分成训练集、验证集和测试集,没有任何地理重叠,依次有205942,39472和78143个序列。
| 类别 | 训练集 | 验证集 | 测试集 |
| 数量/序列 | 205942 | 39472 | 78143 |
四、论文内容
1. SSL-Lanes的有效性
自监督学习可以通过多种方式与运动预测相结合。一种方案是使用前置任务(可以视为编码器参数的初始化)进行预训练,然后使用下游解码器进行微调输出结果。另一种方案是冻住编码器,而只训练解码器。第三种方案是联合训练前置任务和主要任务,即作为一种多任务学习设置。这里选择了第三种方案,即多任务学习。
进行联合训练时,考虑我们的运动预测任务和一个自监督任务,输出和训练过程可以表示为:
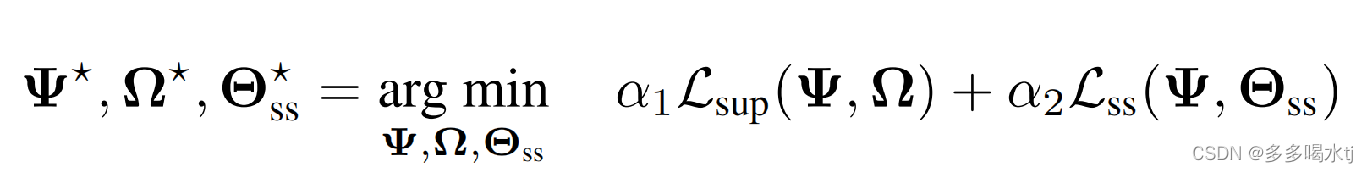
式中,最右边的Lss(·,·)为自监督任务的损失函数,等号左边的第三项Θss为相应的线性变换参数,α1, α2∈R>0为监督损失和自监督损失的权值。
SSL-Lanes的优点如下:
由上式可知,自监督任务可以作为整个网络训练的正则化项。正则化在机器学习中用于防止模型过度拟合,从而提高模型的泛化能力。泛化性是指模型在未见过的数据上表现良好的能力。正确设计的自监督任务会引入数据驱动的先验知识。在自监督学习中,任务的设计和目标的生成是关键,这样的任务设计能够利用数据中的潜在知识和结构,从而为模型提供更丰富的学习信号,进而提高模型的泛化能力。
2. 整体设计
模型的整体结构如图:
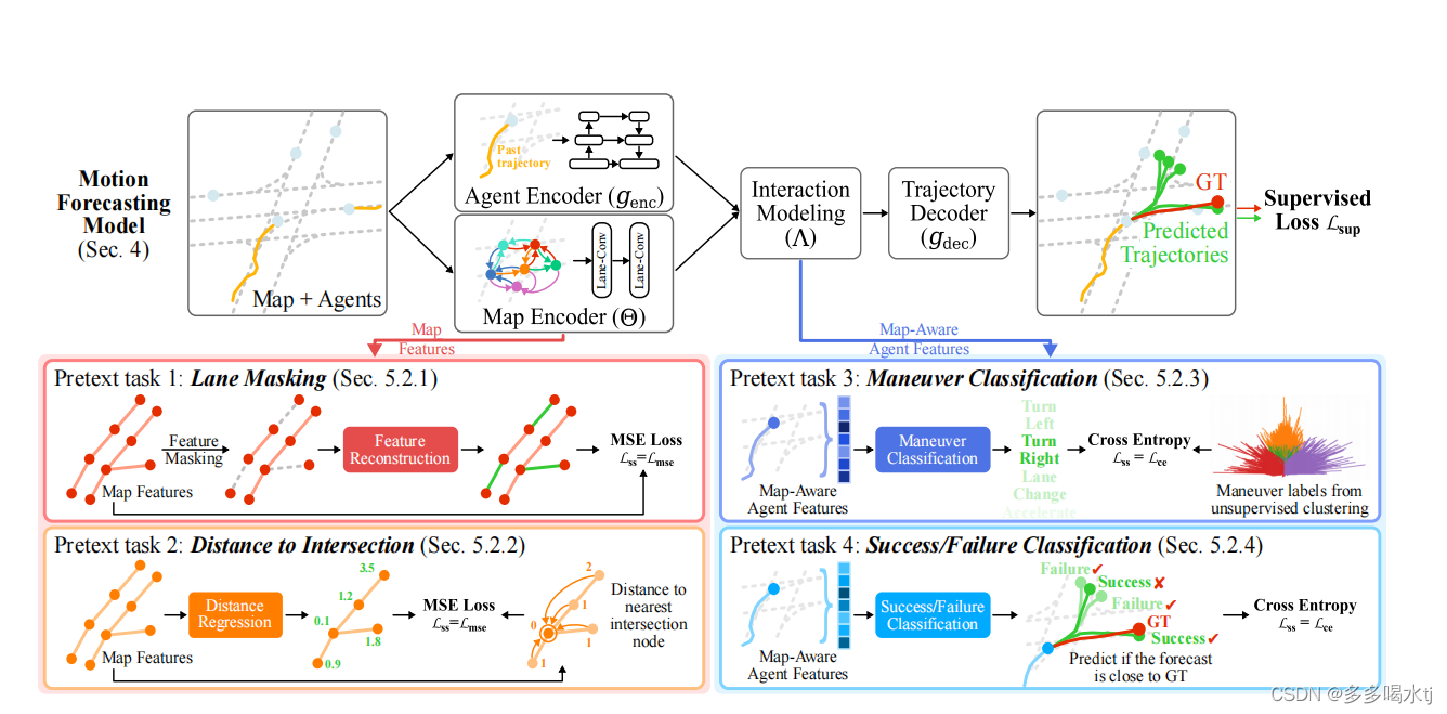
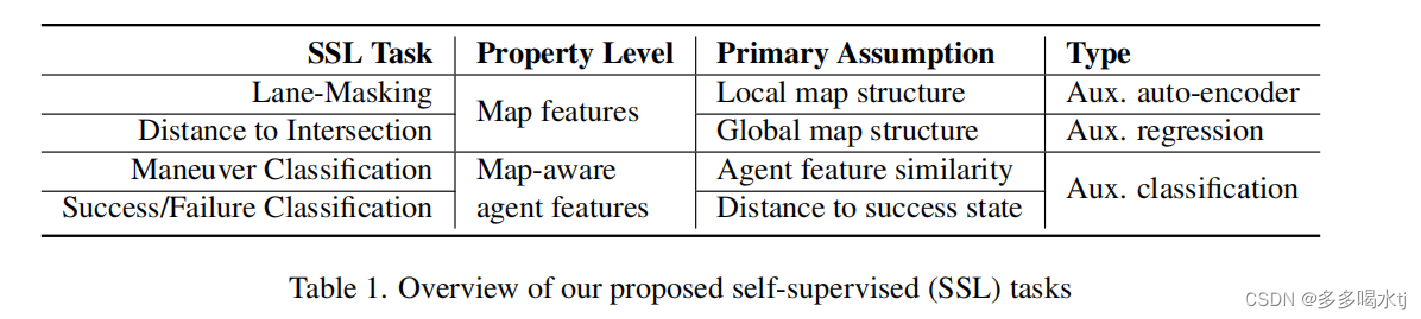
文章提出了四种前置任务,任务一是Lane-masking,车道屏蔽,任务二是Distance to Intersection,到路口交叉点的距离,任务三是机动分类,任务四是预测成功或者失败分类。
根据这张图,分析四个前置任务应该处于的位置。
Lane-Masking任务的目标是鼓励地图编码器在正在优化的预测任务之外学习局部结构信息。这是在map encoder这一部分进行的。
距离到交叉口的借口任务,是用于指导地图编码器,通过预测从所有车道节点到交叉口节点的距离(根据最短路径长度)来维护全局拓扑信息。这一部分也应该是在map encoder这一部分进行的。
机动分类这一部分是在交互模型这一部分。
最后的这个任务预测成功失败的目标是预测是否成功到达特定的终点目标,在这个任务中,成功和失败是根据agent终点位置来判断的。
这样的任务可以在模型的"Supervised Loss"部分进行训练,因为在训练过程中,可以使用agent在环境中的运动轨迹来预测是否成功到达目标位置。损失函数可以基于预测和真实 标签(成功或失败)之间的差异来计算。
SSL-Lanes的核心:
基于来自底层地图结构和整体时间预测问题本身的自监督信息,来定义假设性任务,并从未标注的数据中分配不同的伪标签来求解方程。
3. Lane-masking
前置任务Lane-Masking的目标是鼓励地图编码器除了正在优化的预测人物之外学习局部结构信息。在这项任务中,SSL-Lanes通过从受扰动的车道图中恢复特征信息来学习。
一条车道由几个节点组成,SSL-Lanes随机屏蔽每条车道一定百分比的内容,然后要求自监督解码器重建这些特征。
优点如下:
使用掩码来更好地学习局部地图结构,而不是学习地图和车辆之间的交互。这使得任务会更加的简单。
随机屏蔽每条车道的一定百分比。与随机屏蔽任何节点相比,这是一个更强的先验,确保模型关注地图的所有部分。
由于数据集在机动方面的数据不平衡,因此即使使用多模态预测, 基线也会出现遗漏左/右转、车道变换、加速/减速的情况。SSL-Lanes假设更强的地图特征可以帮助多模态预测头推断出一些与地图拓扑对齐的预测结果。例如,即使车辆在十字路口直行,但也存在由本地地图结构引导的加速/减速或左/右转的可能。
4. Distance to Intersection
Lane-Masking从局部结构的角度出发,基于遮挡并试图预测地图的局部属性。进一步提出了Distance to Intersection前置任务,以指导地图编码器通过预测从所有车道节点到交叉节点的距离(根据最短路径长度)来维护全局拓扑信息。
Distance to Intersection要回归每个车道节点到预先标记的交叉路口节点的距离。论文使用广度优先搜索(BFS)生成伪标签,进一步训练模型。
好处:假设车辆的速度、加速度、主要运动方向的变化,会随着车辆接近或远离交叉路口而发生更大的变化,因此显式鼓励模型在交叉路口附近学习路口的几何结构是有益的,并且可以缩小地图特征编码器的搜索空间,进而有效的简化推理。此外,论文还希望提高交叉口附近可行驶区域的合规性,这对目前的运动预测模型来说是一个值得关注的问题。
5. Maneuver Classification
下一个前置任务是机动分类。
Lane-Masking和Distance to Intersection前置任务都基于从高精地图中提取特征和拓扑信息。但是,前置任务也可以从整体预测任务本身构建。因此,SSL-Lanes提出了Maneuver Classification前置任务,目标是构建伪标签以根据车辆的驾驶行为将其划分为不同的集群,并使用无监督聚类算法来获取车辆的机动信息。
论文发现车辆端点上的约束k-means[44]最适合将轨迹样本平均划分为C个集群,集群包含维持原速、加速、减速、左转、右转和变道。
k-means算法是一种常用的无监督机器学习算法,用于将数据样本划分为k个簇(或集群),使得每个样本都属于离其最近的簇的中心点。它是一种迭代算法,通过不断调整簇的中心点来优化聚类效果。
过程中使用交叉熵损失将每个车辆划分到对应的集群中。
好处:
假设如果可以识别驾驶员的意图,那么车辆的未来运动将与该机动相匹配,从而减少车辆可能的终点集合。此外,论文还期望具有相似动作的车辆应该有一致的语义表示。
详细说明分类过程:
看过代码之后,对其的流程有了更深的理解。
分类时会使用到3个主要的参数,可信度,转向标志和曲率标志。
置信度主要用来衡量车辆行驶轨迹的可信度,在自动驾驶等领域中,如果置信度很高,系统可以更加自信地执行相关决策,而如果置信度较低,系统可能会更加谨慎地考虑其他因素或采取措施,以确保安全和准确性。
当车辆行驶轨迹的起始点和终点所在的车道方向与地图中的道路拓扑结构不太匹配时,可能会导致可信程度较低的轨迹。可能存在道路结构,例如交叉口、转弯等情况,导致道路方向变得模糊或不稳定。置信度比较小,就将标志置为-1.
转向标志。根据车辆行驶轨迹的起始点和终点,判断车辆是否在行驶过程中需要执行转弯操作,它通过获取轨迹起始点和终点最近的中心线,并获取这两个点的车道转向信息。如果判断出来了转向,将标志置为-1.
轨迹的曲率标志。用于判断车辆行驶轨迹的起始点和终点所在车道是否存在曲线,即车道的曲率是否有所改变。可以用来判断是否变道,它通过获取轨迹起始点和终点最近的中心线,并计算这两个中心线方向的曲率。如果曲率发生了一定的变化,也将标志位置为-1.
(1)首先是在数据集中选择轨迹,分别判断轨迹的置信度、转弯标志和曲率标志。如果上述标志中有任何一个为-1,将该轨迹也加入列表,如果上述标志全部为正或为0,且以50%的概率加入轨迹。
然后将其路径以虚线形式显示在图形中。
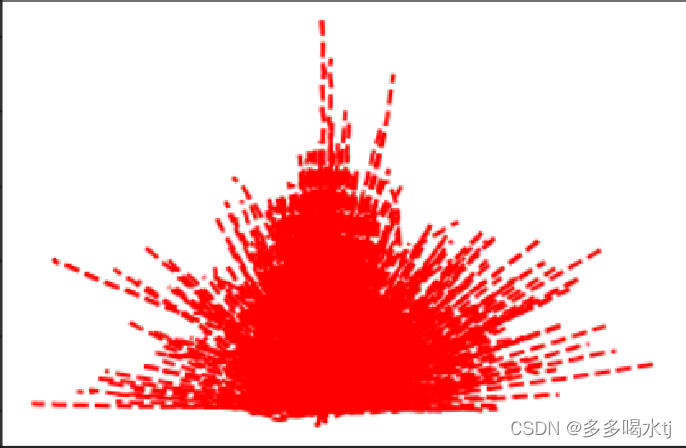
(2)将轨迹数据根据轨迹的结束点的角度信息进行筛选和显示,以便对特定角度范围内的轨迹和超过某个角度的轨迹进行可视化。红色虚线表示角度小于20的轨迹,蓝色虚线表示角度大于20的轨迹。
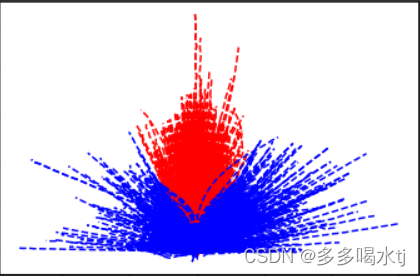
(3)接下来使用一个 Cop-KMeans 聚类算法。这是一种基于凸优化原理的聚类方法,用于在存在离群点的情况下进行聚类。
使用 cop_kmeans 函数来对特定轨迹集群进行聚类,并对聚类结果进行可视化。择角度小于20的轨迹的最后一个点(即最后的坐标)作为输入数据集。
使用 cop_kmeans 函数将这些数据点进行聚类,将轨迹分为3个簇(k=3)。对满足角度大于20的轨迹(通过索引 idx_turn 访问)将轨迹分为2个簇。

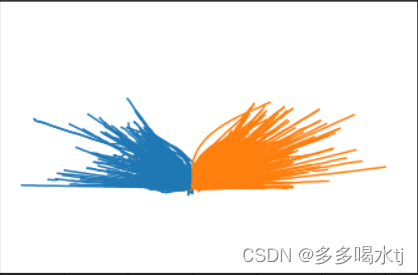
(4)然后可以将两组聚类结果进行合并,一共有5种情况。
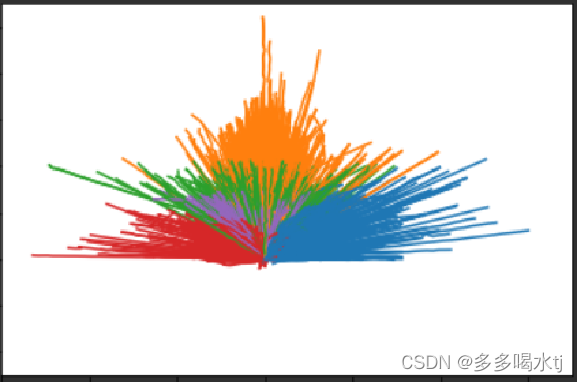
(5)这些直线的绘制可以用于在图形上标示出聚类结果的中心点位置,不同颜色和线宽可以帮助区分不同的中心点。这通常用于分析聚类结果并标示出集群的位置。
(6)
接下来确定轨迹的意图,一共有6种意图:intentions = ['straight-same',
'straight-slow',
'straight-fast',
'left-turn',
'right-turn',
'lane-change']
。它首先计算轨迹的终点与每个聚类中心之间的余弦距离,然后根据距离选择与轨迹终点最相似的聚类中心,余弦距离表示向量之间的相似度,值越接近0表示向量越相似。就是在五个之中选择。可以分成三部分,左转、右转和直行。
对于直行,就是选择的聚类中心与中间三个 "same"、"slow" 或 "fast" 意图相关。就需要进行进一步的分析。像代码中所展示的,转弯标记是1,说明没有发生转弯,但是置信度标记为-1,说明发生了状态的变化,不是单纯的直行,在这种情况下,设置为变道。
接下来开就是区别直线加速、减速、原速,遍历前3个聚类中心,计算轨迹终点与每个聚类中心之间的欧氏距离(将slow/fast.same区分开来),选择距离最小的聚类中心
(欧式距离(Euclidean distance)是指在几何空间中,两个点之间的直线距离)
一般而言,聚类中心会在算法的每一次迭代中进行调整,以逐步优化聚类结果。在聚类完成后,得到的聚类中心将用于对新的数据点进行分类,从而识别出数据点所属的类别或簇。
右转:
左转:
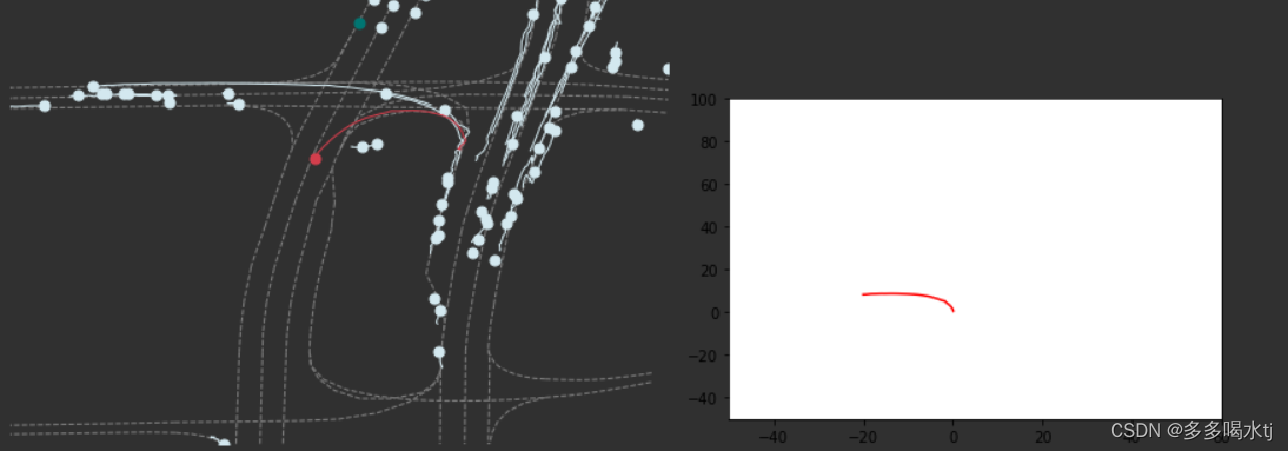
变道:
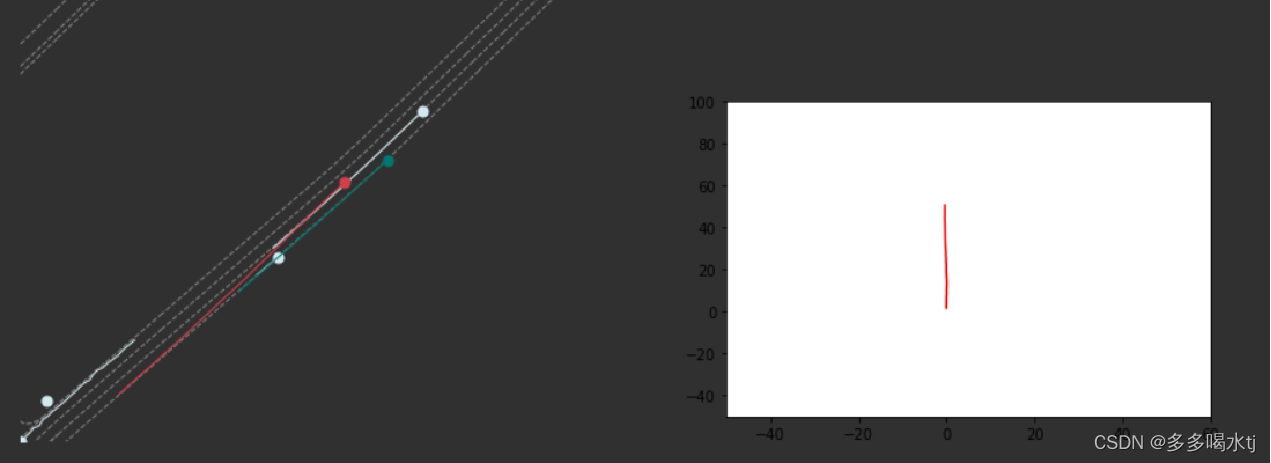
直线减速:
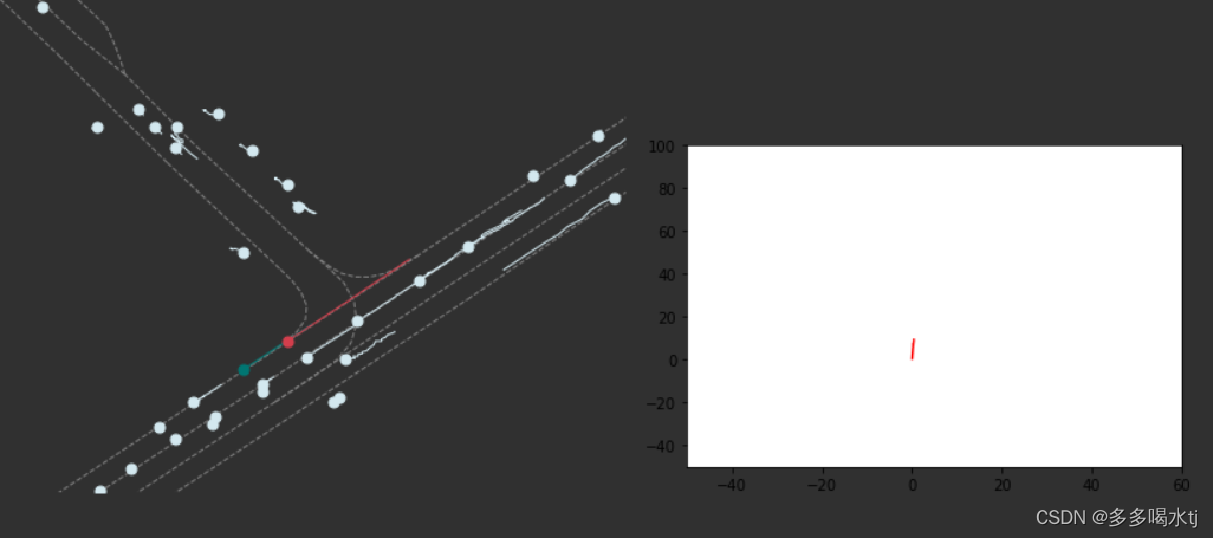
直线匀速:
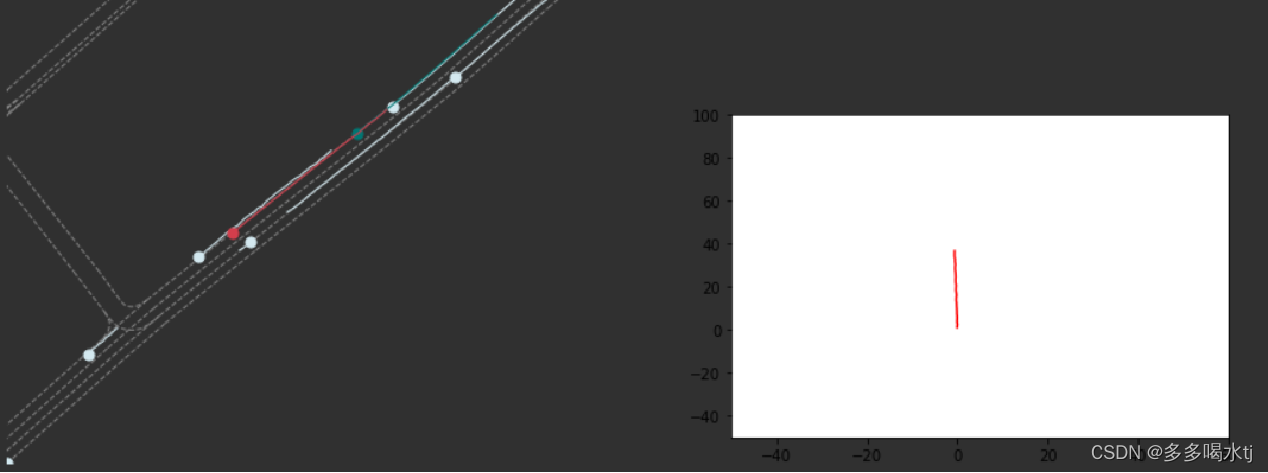
6. Forecasting Success/Failure Classification
与提供对未来粗粒度预测的机动分类相比,自监督机制还可以通过车辆轨迹生成的goal-reaching任务提供丰富的学习信息。因此,进一步提出Forecasting Success/Failure Classification前置任务,其训练一个专门用于实现端点目标的代理。希望通过此项前置任务来限制模型预测远离正确终点的轨迹距离。
方法也是通过收集伪标签。如果最终预测的端点误差小于2m,则认为轨迹预测成功(c=1),否则为失败(c=0)。
优点是:
从概念上讲,收集的成功目标状态的数量越多,模型对预测任务的理解就越好。假设对于数据集中给出的大多数样本的最终端点与车辆移动的方向不对齐,这项任务会提供更强的增强。
对这个前置任务进行详细地说明:
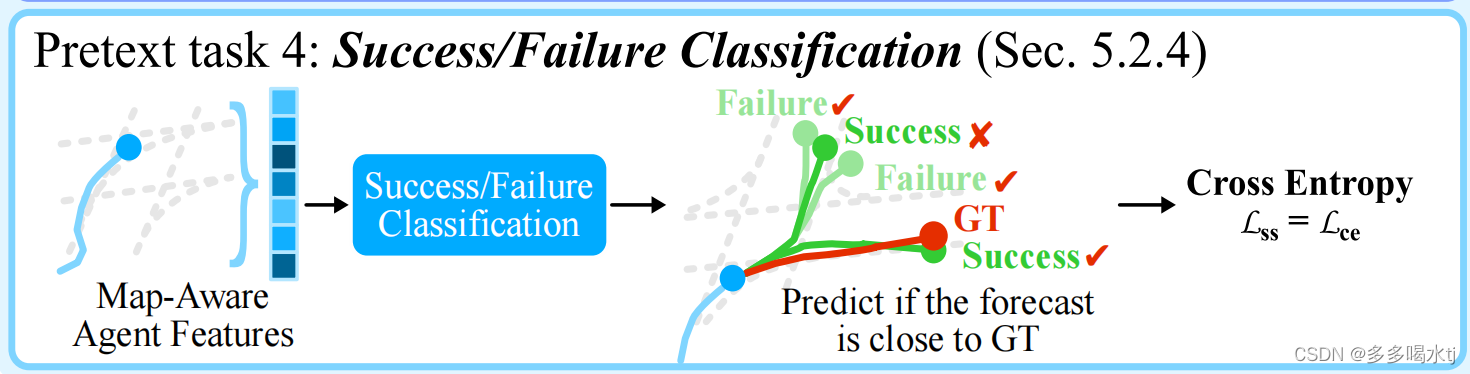
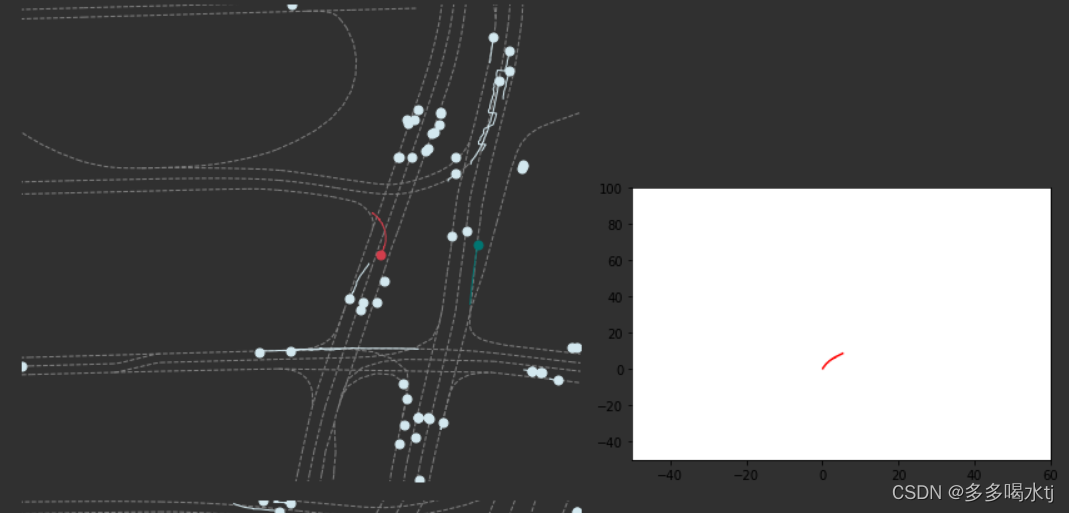
图中:
Success:轨迹结束点附近的2米范围内只有少数成功的例子。
failure:场景中的其余点可以被视为失败的例子。
对于第四个前置任务,像图中的这个实例,红色为实际轨迹,绿色是预测出的轨迹,对于这四个绿色轨迹进行成功失败预测,对于最上面这个轨迹我们预测它是失败的,而实际上它确实是失败的,所以是对号,对于第二条轨迹,我们预测它是成功的,但是实际上这条轨迹是失败的,所以是错号,同理,最下面这条我们预测它是成功的,实际上这条轨迹与实际轨迹一致,所以是对号。
在这个预训练任务中,主要的瓶颈是正样本(目标物体)的数量远少于负样本(非目标物体)的数量。这是因为在单个记录的地面实况轨迹的结束点附近的2米范围内只有少数成功的例子,而场景中的其余点可以被视为失败的例子。这就出现了类别不平衡的问题,在类别不平衡的情况下,训练模型可能会面临一个问题,即很容易忽略数量较少的重要类别,从而影响模型性能。
于是使用焦点损失这一方式来训练。
Focal Loss(焦点损失)是一种用于解决类别不平衡问题的损失函数,特别适用于目标检测和图像分类等任务。通过降低容易分类的样本的权重,以便让模型更加关注难分类的样本,从而解决类别不平衡问题。
Focal Loss的公式如下:

左边的FL(pt) 表示Focal Loss,即聚焦损失的值。
主要参数是pt,(模型预测为正样本的概率,即)是指预测的分类概率。
(不读αt 是一个调整因子,可以根据实际情况进行设置,通常可以用来平衡正负样本的权重。γ 是一个可调参数,控制了焦点(focus)的程度。较小的 γ 会减弱焦点的效果,而较大的 γ 会增强焦点。)
当 pt 较大时,也就是模型对某个样本的预测很自信,该样本对损失的贡献较小;而当 pt较小时,模型对该样本的预测不自信,该样本对损失的贡献会被放大。这就实现了对难以分类的样本给予更多关注的效果,从而有效地解决了类别不平衡的问题。
7. 汇总
前两个任务和后两个任务处在不同的level上,第一个任务中会学习地图局部结构,第二个任务更侧重于地图的全局结构,第三个任务会利用agent的特征相似性进行分类,第四个任务则是尽可能向成功状态进行预测。
五、learning
由于所有的模块都是可微的,所以作者以端到端的方式来训练模型。SSL=Lanes可以以端到端的方式训练模型,最终的损失函数如下所示:
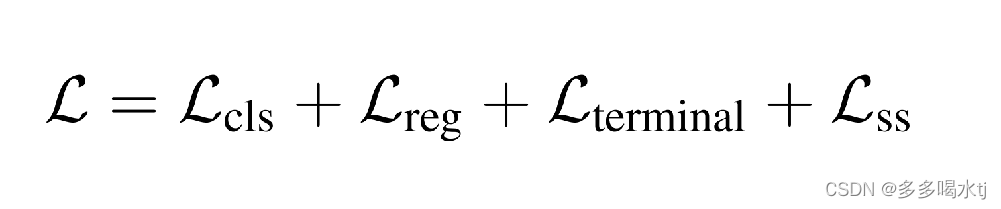
使用分类化、回归和自监督损失的和来训练模型,前面设置的四种前置任务主要影响第四项的结果。
六、 实验验证
用于评估结果的指标有以下几种:
ADE为在所有时间上真实轨迹和预测轨迹之间的平均位移误差。
FDE为最终时间的真实轨迹和预测轨迹之间的位移误差。
脱靶率MR为FDE在阈值(2 m)内的未能成功预测的百分比。
我们为每个场景计算K个可能的轨迹,其中使用K = 1和K = 6。
minADE和minFDE分别是前K个预测中的最小ADE和FDE。
值越小,说明误差越小,效果更好。
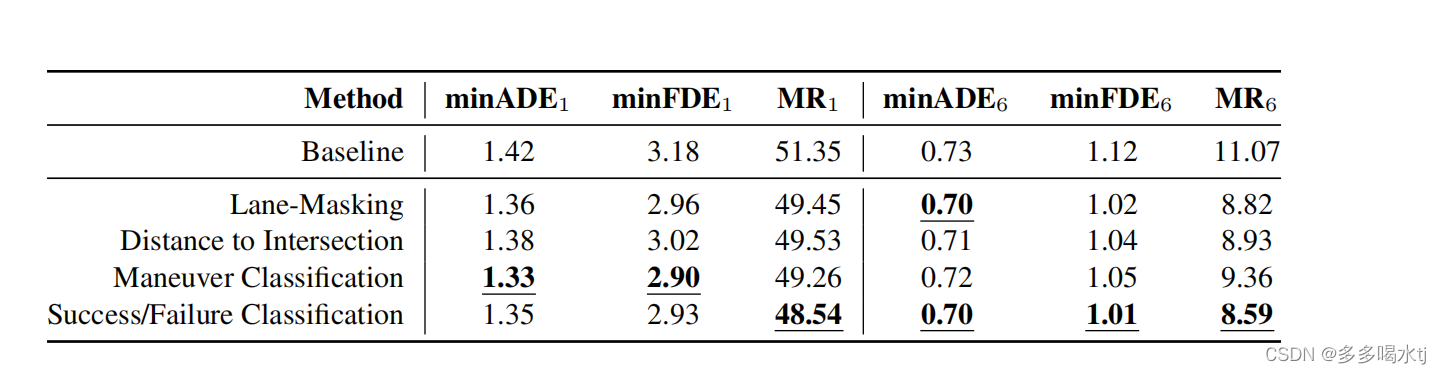
论文对提出的四项自监督前置任务展开实验,与baseline 相比,可以看出每个模块都有效果。
以一种更加直观的方式,进行定性的分析:
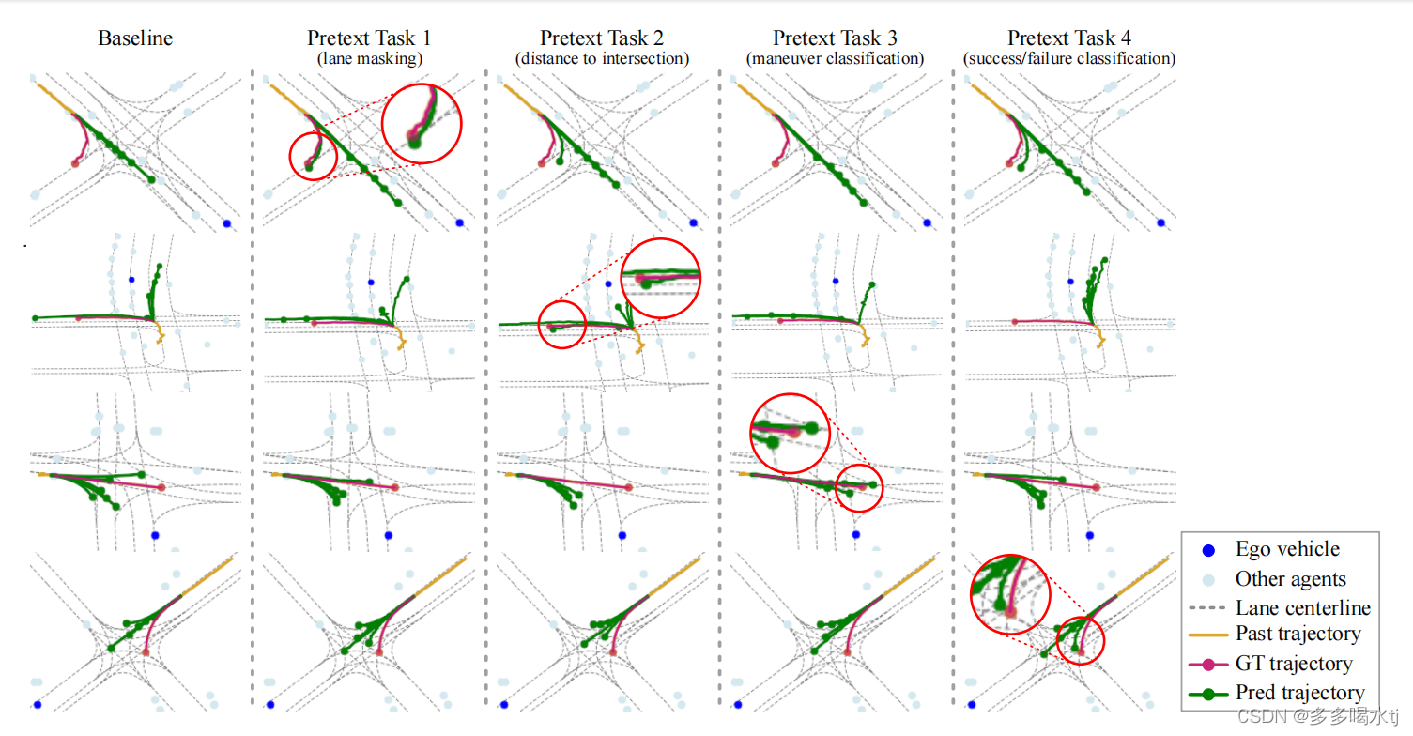
如图所示是几个困难情况下不同假设性任务的定性结果,在第一行中,车道掩膜成功地捕获了右转。对于第二行,预测到交叉口的距离对捕捉左转帮助最大。在第三行中,交叉路口处的加速度最好由机动分类的模型来捕获。最后,在第四行中,对成功的最终目标状态进行分类在捕捉左转方面是最有效的。
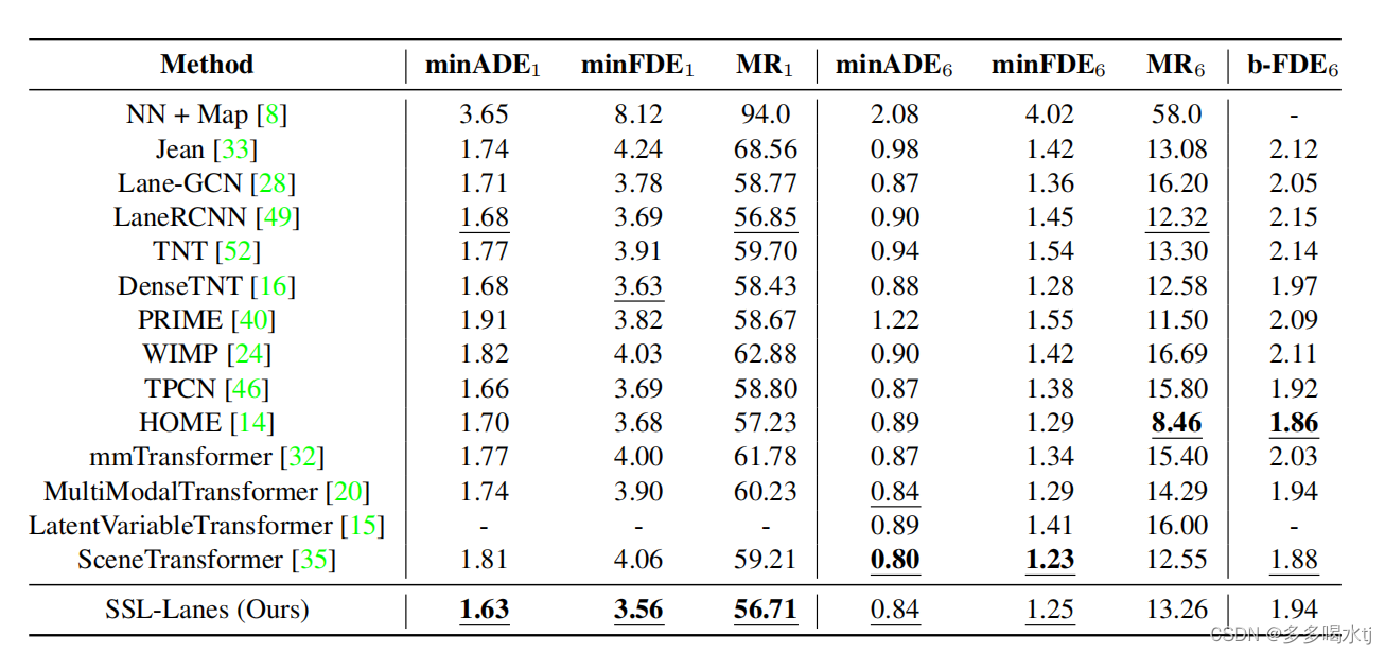
然后与其他的方法进行对比,论文的SSL-Lanes方法取得了更好的性能。
七、分析预测
为什么自监督学习可以提升运动预测的性能?
假设使用SSL前置任务有益的原因:
1是基于拓扑的上下文预测假设地图在较小邻域中的特征相似性或平滑度,这种基于上下文的特征表示可以极大地提高预测性能,尤其是在邻域较小的情况下;
2是聚类和分类建设特征相似意味着目标标签相似,并且可以将具有相似特征的远距离节点组合在一起,以提升泛化性;
3是使用不平衡数据集进行监督学习会导致性能显著下降。数据集中的大部分数据样本都在中间路段,但有相当多的数据样本涉及直线行驶同时保持速度。
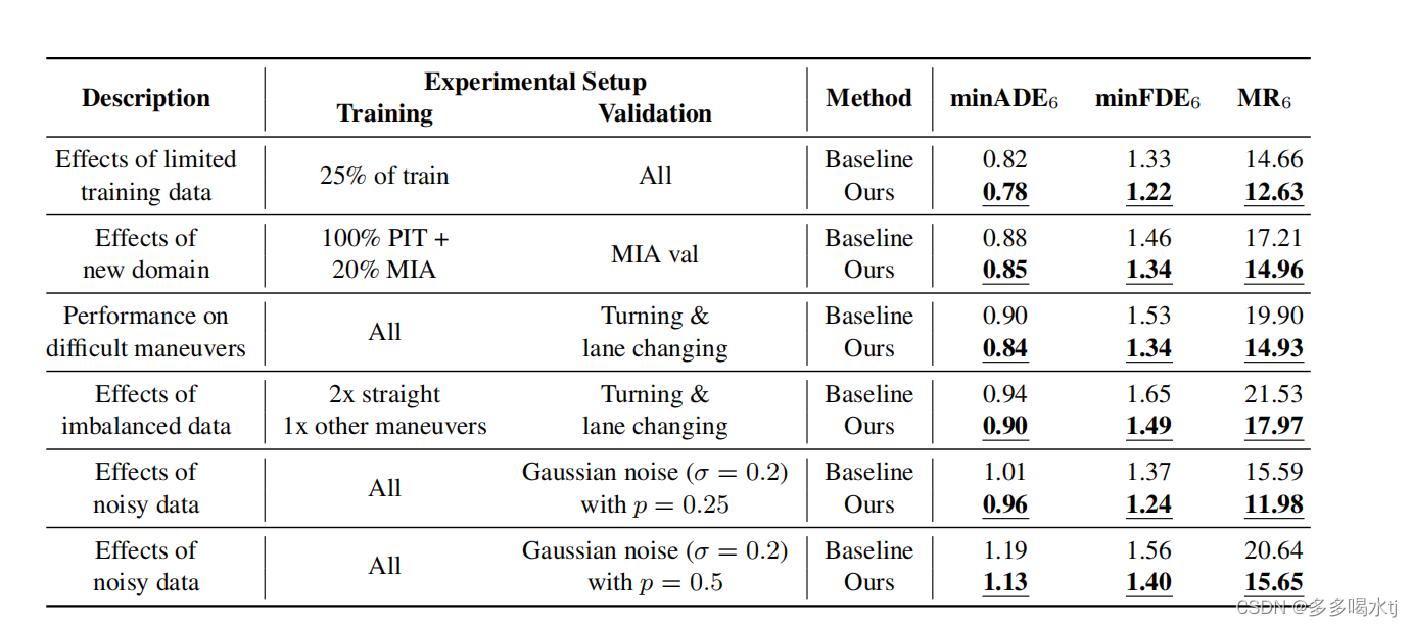
然后作者设计了6种不同的训练和测试设置,经过实验验证,证明结果显示,基于SSL的任务确实提供了更好的泛化能力,因此可以证明比单纯基于监督训练的方法更有效。
八、结论
论文提出的SSL-Lanes以伪标签的形式利用从训练数据生成的监督信号,并将其与标准运动预测模型集成,设计了四个前置任务,可以利用地图结构和车辆动态之间的相似性来生成伪标签。SSL-Lanes的主要优点是它具有高精度、低架构复杂性和高推理速度。实验结果也表明,每个前置任务都有性能提升,尤其是在左/右转和减速/减速等困难情况下。最后,论文还提供了关于SSL-Lanes为何可以改善运动预测的假设和实验。
九、不足
SSL-Lanes一个限制是,无监督损失和监督损失的权重比例是1:1,没有进行调整。并且论文的实验也只使用了一个前置任务,并未探索它们之间的组合。未来,作者将探索前置任务的有效组合并自动进行平衡,性能更进一步的提升是可预见的。另一个限制是,论文没有专门考虑多个高度交互的车辆。未来,作者将进一步探索道路车辆之间的交互如何影响数据集的SSL损失。最后,论文仅在同一数据集上与纯监督训练相比,探索隐式数据不平衡方面的泛化性,未来将尝试推广到其他数据集上且无需重新训练。

















 540
540

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









