






 本文详细介绍了改进的k-NN分类器,包括使用插入排序加速k个最近邻查找,引入欧氏和曼哈顿距离选择,以及实现带权重的投票和leave-one-out测试。讨论了这些因素对模型性能的影响及适用场景。
本文详细介绍了改进的k-NN分类器,包括使用插入排序加速k个最近邻查找,引入欧氏和曼哈顿距离选择,以及实现带权重的投票和leave-one-out测试。讨论了这些因素对模型性能的影响及适用场景。
0.主题
对昨天的 k \textit{k} k-NN分类器进行的一些补充。
1.程序
1. 重新实现computeNearests
computeNearests,即求
k
\textit{k}
k 个最近邻,结合插入排序,可以用一次扫描实现这个功能。具体的,我们需要维护两个个能存储
k
\textit{k}
k 个元素的数组,一个用于存储距离,一个用于存储数据点的下标,程序的执行逻辑如下:
- 求训练集中的一个数据点与当前测试数据点间的距离
- 当数组未存满 k \textit{k} k 个元素,或者当前两点距离小于数组中第 k \textit{k} k 大值的时候,用插入排序将该距离放入距离数组,始终维持距离数组中的元素保持升序。同步调整数据点数组中的值。
- 跳转至第1步,至训练集中所有元素均被扫描则终止。
具体实现如下:
/**
************************************
* Compute the nearest k neighbors.
*
* @param paraCurrent current instance. We are comparing it with all others.
* @return the indices of the nearest instances.
************************************
*/
public int[] computeNearests( int paraCurrent ) {
int[] resultNearests = new int[ numNeighbors ];
double[] resultDistances = new double[ numNeighbors ];
int index = 0;
double[] tempDistances = new double[ dataset.numInstances( ) ];
for ( int i = 0; i < tempDistances.length; i++ ) {
if ( i == paraCurrent ) {
continue;
} // Of if
tempDistances[ i ] = distance( paraCurrent, i );
int tempPos;
if ( index < numNeighbors ) {
tempPos = index;
index++;
} else if ( resultDistances[ numNeighbors - 1 ] > tempDistances[ i ] ) {
tempPos = numNeighbors - 1;
} else {
continue;
} // Of if
while ( tempPos > 0 ) {
if ( resultDistances[ tempPos - 1 ] > tempDistances[ i ] ) {
resultDistances[ tempPos ] = resultDistances[ tempPos - 1 ];
resultNearests[ tempPos ] = resultNearests[ tempPos - 1 ];
} else {
resultDistances[ tempPos ] = tempDistances[ i ];
resultNearests[ tempPos ] = i;
break;
} // Of if
tempPos--;
} // Of while
if ( tempPos == 0 ) {
resultDistances[ tempPos ] = tempDistances[ i ];
resultNearests[ tempPos ] = i;
} // Of if
} //Of for i
System.out.println("The nearest of " + paraCurrent + " are: " + Arrays.toString(resultNearests));
return resultNearests;
} // Of computeNearests
2. setDistanceMeasure() 方法
增加了该方法,可以自由的在曼哈顿距离和欧氏距离之间切换了。当修改的距离度量非法时,distance方法会给出提升,因此这里就不再考虑非法情况。
/**
*********************
* Chose the type of distance.
*
* @param paraDistance The given distance measure.
*********************
*/
public void setDistanceMeasure( int paraDistance ) {
distanceMeasure = paraDistance;
} // Of setDistanceMeasure
3. setNumNeighors() 方法
增加该方法后,可以自由的选择
k
\textit{k}
k 值了,当选择的
k
\textit{k}
k 非法时,程序给出提示,并使用默认的
k
\textit{k}
k 值。
/**
*********************
* Chose the number of neighbor.
*
* @param paraK The given number.
*********************
*/
public void setNumNeighors( int paraK ) {
if ( ( paraK <= 0 ) || ( paraK > trainingSet.length) ) {
System.out.println("The number of neighbor is illegal, We'll use the default values!");
return;
}
numNeighbors = paraK;
} // Of setNumNeighors
4. weightedVoting() 方法
该方法考虑了
k
\textit{k}
k 个最近邻中,不同远近邻居的权重。具体的策略为,最近的数据点可以投
k
\textit{k}
k 票,第二近的数据点投
k
−
1
\textit{k} - 1
k−1 票,以此类推,最远的(即第
k
\textit{k}
k 远的邻居) 投
1
\text{1}
1票。
可以描述为,第
i
\textit{i}
i 近的邻居投票数为
k
−
i
+
1
\textit{k} - \textit{i} + 1
k−i+1 。这就保证了距离越近的邻居话语权越大,越远的话语权越小。由于在今天重新实现的computeNearests方法中,我们始终维护长度为
k
\textit{k}
k 的按距离升序的数组,因此在这里区分
k
\textit{k}
k 个邻居的远近也就是很容易的事情了。
/**
************************************
* weightedVoting using the instances.
*
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
************************************
*/
public int weightedVoting( int[] paraNeighbors ) {
int[] tempVotes = new int[ dataset.numClasses( ) ];
for ( int i = 0; i < paraNeighbors.length; i++ ) {
tempVotes[ ( int ) dataset.instance( paraNeighbors[ i ] ).classValue( ) ] += numNeighbors - i + 1;
} // Of for i
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for ( int i = 0; i < dataset.numClasses( ); i++ ) {
if ( tempVotes[ i ] > tempMaximalVoting ) {
tempMaximalVoting = tempVotes[ i ];
tempMaximalVotingIndex = i;
} // Of if
} // Of for i
return tempMaximalVotingIndex;
} // Of weightedVoting
5. 测试
测试选择距离度量为欧氏距离,
k
\textit{k}
k 为
8
\text{8}
8,投票方式为带权重的投票,测试代码如下:
/**
*********************
* The entrance of the program.
*
* @param args Not used now.
*********************
*/
public static void main( String args[ ] ) {
KnnClassification tempClassifier = new KnnClassification("G:/Program Files/Weka-3-8-6/data/iris.arff");
tempClassifier.setDistanceMeasure( 1 );
tempClassifier.splitTrainingTesting( 0.8 );
tempClassifier.setNumNeighors( 8 );
tempClassifier.predict( );
System.out.println("The accuracy of the classifier is: " + tempClassifier.getAccuracy());
} // Of main
程序执行结果如下:
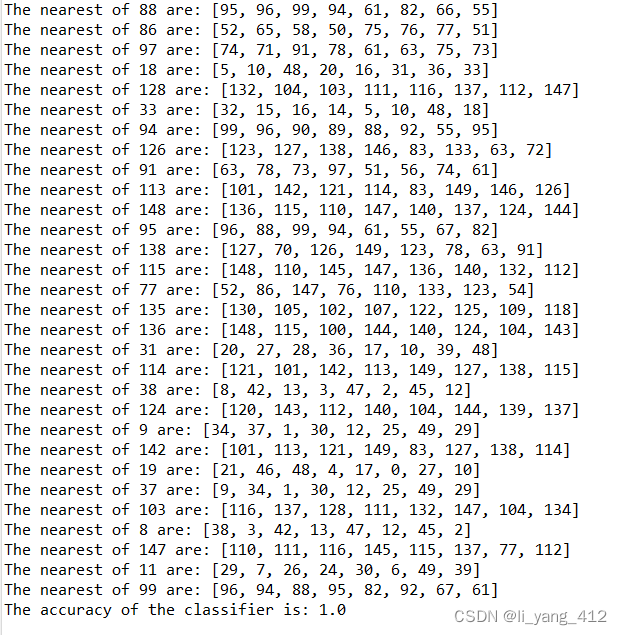
2. leave-one-out测试
所谓 leave-one-out,就是说,每次选择一个数据点来测试,而其余的数据点全部用于训练,每一个数据点都会被选来测试一次。
本来想把 leave-one-out 写成一个方法,但是各个方法之间的依赖挺多的,要进行 leave-one-out 需要对很多方法进行修改,所以干脆重新弄了个类,在之前的基础上进行简单的修改来进行leave-one-out测试。
代码如下:
package machinelearning.knn;
import java.io.FileReader;
import java.util.Arrays;
import weka.core.*;
public class KnnLeaveOneOut {
/**
* Manhattan distance.
*/
public static final int MANHATTAN = 0;
/**
* Euclidean distance.
*/
public static final int EUCLIDEAN = 1;
/**
* The distance measure.
*/
public int distanceMeasure = EUCLIDEAN;
/**
* The number of neighbors.
*/
int numNeighbors = 7;
/**
* The whole dataset.
*/
Instances dataset;
/**
* The predictions.
*/
int[] predictions;
/**
*********************
* The first constructor.
*
* @param paraFilename The arff filename.
*********************
*/
public KnnLeaveOneOut( String paraFilename ) {
try {
FileReader fileReader = new FileReader( paraFilename );
dataset = new Instances( fileReader );
dataset.setClassIndex( dataset.numAttributes( ) - 1 );
fileReader.close( );
} catch ( Exception ee ) {
System.out.println("Error occurred while trying to read \'" + paraFilename
+ "\' in KnnClassification constructor.\r\n" + ee);
System.exit( 0 );
} // Of try
} // Of the first constructor
/**
*********************
* Predict for the whole data set. The results are stored in predictions.
* #see predictions.
*********************
*/
public void predict( ) {
predictions = new int[ dataset.numInstances( ) ];
for ( int i = 0; i < predictions.length; i++ ) {
predictions[ i ] = predict( i );
} // Of for i
} // Of predict
/**
*********************
* Predict for given instance.
*
* @return The prediction.
*********************
*/
public int predict( int paraIndex ) {
int[] tempNeighbors = computeNearests( paraIndex );
int resultPrediction = weightedVoting( tempNeighbors );
return resultPrediction;
} // Of predict
/**
*********************
* Chose the type of distance.
*
* @param paraDistance The given distance measure.
*********************
*/
public void setDistanceMeasure( int paraDistance ) {
distanceMeasure = paraDistance;
} // Of setDistanceMeasure
/**
*********************
* The distance between two instances.
*
* @param paraI The index of the first instance.
* @param paraJ The index of the second instance.
* @return The distance.
*********************
*/
public double distance( int paraI, int paraJ ) {
double resultDistance = 0;
double tempDifference;
switch ( distanceMeasure ) {
case MANHATTAN:
for ( int i = 0; i < dataset.numAttributes( ) - 1; i++ ) {
tempDifference = dataset.instance( paraI ).value( i ) - dataset.instance( paraJ ).value( i );
if ( tempDifference < 0 ) {
resultDistance -= tempDifference;
} else {
resultDistance += tempDifference;
} // Of if
} // Of for i
break;
case EUCLIDEAN:
for ( int i = 0; i < dataset.numAttributes( ) - 1; i++ ) {
tempDifference = dataset.instance( paraI ).value( i ) - dataset.instance( paraJ ).value( i );
resultDistance += tempDifference * tempDifference;
} // Of for i
break;
default:
System.out.println("Unsupported distance measure: " + distanceMeasure);
} // Of switch
return resultDistance;
} // Of distance
/**
*********************
* Get the accuracy of the classifier.
*
* @return The accuracy.
*********************
*/
public double getAccuracy( ) {
// A double divides an int gets another double.
double tempCorrect = 0;
for ( int i = 0; i < predictions.length; i++ ) {
if ( predictions[ i ] == dataset.instance( i ).classValue( ) ) {
tempCorrect++;
} // Of if
} // Of for i
return tempCorrect / predictions.length;
} // Of getAccuracy
/**
************************************
* Compute the nearest k neighbors.
*
* @param paraCurrent current instance. We are comparing it with all others.
* @return the indices of the nearest instances.
************************************
*/
public int[] computeNearests( int paraCurrent ) {
int[] resultNearests = new int[ numNeighbors ];
double[] resultDistances = new double[ numNeighbors ];
int index = 0;
double[] tempDistances = new double[ dataset.numInstances( ) ];
for ( int i = 0; i < tempDistances.length; i++ ) {
if ( i == paraCurrent ) {
continue;
} // Of if
tempDistances[ i ] = distance( paraCurrent, i );
int tempPos;
if ( index < numNeighbors ) {
tempPos = index;
index++;
} else if ( resultDistances[ numNeighbors - 1 ] > tempDistances[ i ] ) {
tempPos = numNeighbors - 1;
} else {
continue;
} // Of if
while ( tempPos > 0 ) {
if ( resultDistances[ tempPos - 1 ] > tempDistances[ i ] ) {
resultDistances[ tempPos ] = resultDistances[ tempPos - 1 ];
resultNearests[ tempPos ] = resultNearests[ tempPos - 1 ];
} else {
resultDistances[ tempPos ] = tempDistances[ i ];
resultNearests[ tempPos ] = i;
break;
} // Of if
tempPos--;
} // Of while
if ( tempPos == 0 ) {
resultDistances[ tempPos ] = tempDistances[ i ];
resultNearests[ tempPos ] = i;
} // Of if
} //Of for i
System.out.println("The nearest of " + paraCurrent + " are: " + Arrays.toString(resultNearests));
return resultNearests;
} // Of computeNearests
/**
************************************
* Voting using the instances.
*
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
************************************
*/
public int simpleVoting(int[] paraNeighbors) {
int[] tempVotes = new int[ dataset.numClasses( ) ];
for ( int i = 0; i < paraNeighbors.length; i++ ) {
tempVotes[ ( int ) dataset.instance( paraNeighbors[ i ] ).classValue( ) ]++;
} // Of for i
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for ( int i = 0; i < dataset.numClasses( ); i++ ) {
if ( tempVotes[ i ] > tempMaximalVoting ) {
tempMaximalVoting = tempVotes[ i ];
tempMaximalVotingIndex = i;
} // Of if
} // Of for i
return tempMaximalVotingIndex;
} // Of simpleVoting
/**
************************************
* weightedVoting using the instances.
*
* @param paraNeighbors The indices of the neighbors.
* @return The predicted label.
************************************
*/
public int weightedVoting( int[] paraNeighbors ) {
int[] tempVotes = new int[ dataset.numClasses( ) ];
for ( int i = 0; i < paraNeighbors.length; i++ ) {
tempVotes[ ( int ) dataset.instance( paraNeighbors[ i ] ).classValue( ) ] += numNeighbors - i + 1;
} // Of for i
int tempMaximalVotingIndex = 0;
int tempMaximalVoting = 0;
for ( int i = 0; i < dataset.numClasses( ); i++ ) {
if ( tempVotes[ i ] > tempMaximalVoting ) {
tempMaximalVoting = tempVotes[ i ];
tempMaximalVotingIndex = i;
} // Of if
} // Of for i
return tempMaximalVotingIndex;
} // Of weightedVoting
/**
*********************
* Chose the number of neighbor.
*
* @param paraK The given number.
*********************
*/
public void setNumNeighors( int paraK ) {
if ( ( paraK <= 0 ) || ( paraK >= dataset.numInstances( ) ) ) {
System.out.println("The number of neighbor is illegal, We'll use the default values!");
return;
}
numNeighbors = paraK;
} // Of setNumNeighors
/**
*********************
* The entrance of the program.
*
* @param args Not used now.
*********************
*/
public static void main( String args[ ] ) {
KnnLeaveOneOut tempClassifier = new KnnLeaveOneOut("G:/Program Files/Weka-3-8-6/data/iris.arff");
tempClassifier.setDistanceMeasure( 1 );
tempClassifier.setNumNeighors( 9 );
tempClassifier.predict( );
System.out.println("The accuracy of the classifier is: " + tempClassifier.getAccuracy());
} // Of main
} // Of class KnnLeaveOneOut
在该测试中,距离度量选择欧氏距离,
k
\textit{k}
k 值选择为
9
9
9,投票方式为带权重的投票。
程序执行结果如下:
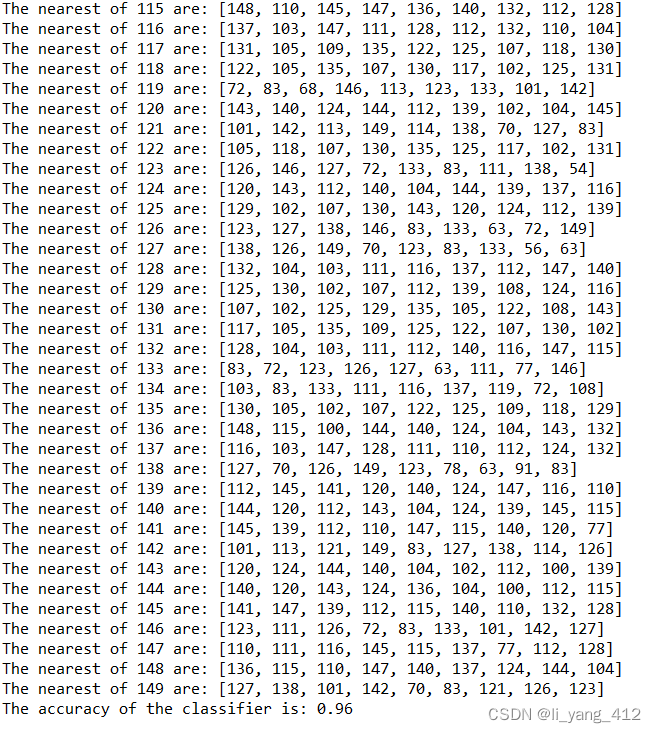
3. 体会
- 影响 k \textit{k} k-NN结果的因素有距离度量,投票方式, k \textit{k} k 值选择。今天增加的几个方法就是用于灵活的调节这几个因素。
- leave-one-out可以看做把数据集划分为训练集和大小为1的测试集,每个数据点都要做一次测试集。也就是说leave-one-out需要的计算要更多,一般时间复杂度太高的就不太适合用leave-one-out了。另一方面,当数据集足够大的时候,选择按比例将数据集划分为训练集和测试集比较合理,这样时间成本更低些,数据集比较小的时候,就可以考虑leave-one-out,因为可以将数据充分的利用起来。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









