






1.模型下载:
1.1魔搭社区:
pip install modescope1.1.1使用命令行下载:
#无论是使用命令行还是ModelScope SDK,模型会下载到~/.cache/modelscope/hub默认路径下。
#下载整个模型repo(到默认cache地址)
modelscope download --model 'Qwen/Qwen2-7b'
#下载整个模型repo到指定目录
modelscope download --model 'Qwen/Qwen2-7b' --local_dir 'path/to/dir'
#指定下载到local_dir目录
modelscope download --model 'Qwen/Qwen2-7b' --include '*.json' --local_dir './local_dir'
#指定下载单个文件(以'tokenizer.json'文件为例)
modelscope download --model 'Qwen/Qwen2-7b' tokenizer.json
#指定下载多个个文件
modelscope download --model 'Qwen/Qwen2-7b' tokenizer.json config.json
#指定下载某些文件
modelscope download --model 'Qwen/Qwen2-7b' --include '*.safetensors'
#下载时,过滤指定文件
modelscope download --model 'Qwen/Qwen2-7b' --exclude '*.safetensors'1.1.2使用SDK下载:
#使用snapshot_download下载整个模型仓库
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('iic/nlp_xlmr_named-entity-recognition_viet-ecommerce-title')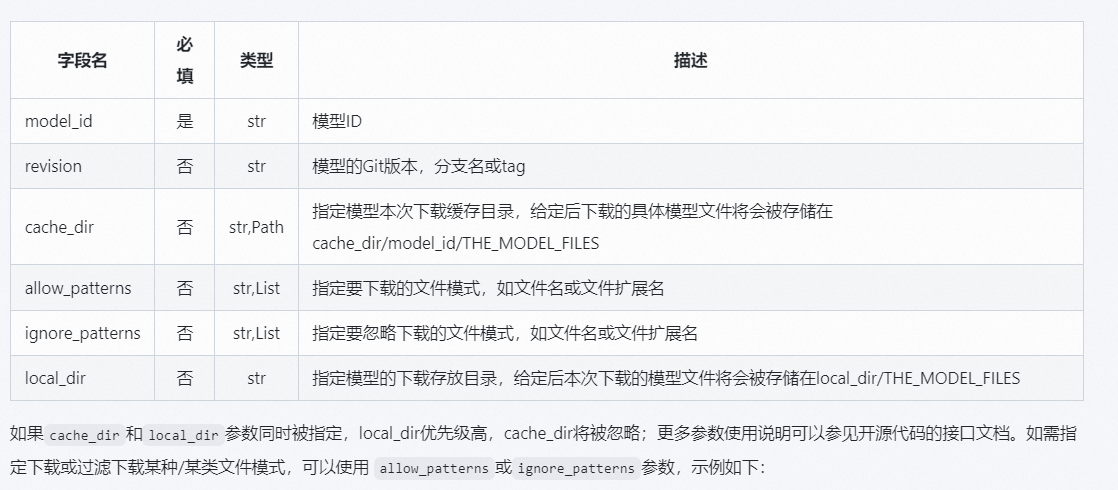
#指定下载某些文件
#指定下载Qwen/QwQ-32B-GGUF中q4_k_m量化版本到path/to/local/dir目录下
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('Qwen/QwQ-32B-GGUF',allow_patterns='qwq-32b-q4_k_m.gguf',local_dir='path/to/local/dir')
#过滤指定文件
#将deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B仓库除figures子目录外的所有文件下载到指定的path/to/local/dir目录
from modelscope.hub.snapshot_download import snapshot_download
model_dir = snapshot_download('deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B',ignore_patterns='figures/',local_dir='path/to/local/dir')#下载模型指定文件
#使用model_file_download下载模型指定文件
from modelscope.hub.file_download import model_file_download
model_dir = model_file_download(model_id='Qwen/QwQ-32B-GGUF',file_path='qwq-32b-q4_k_m.gguf')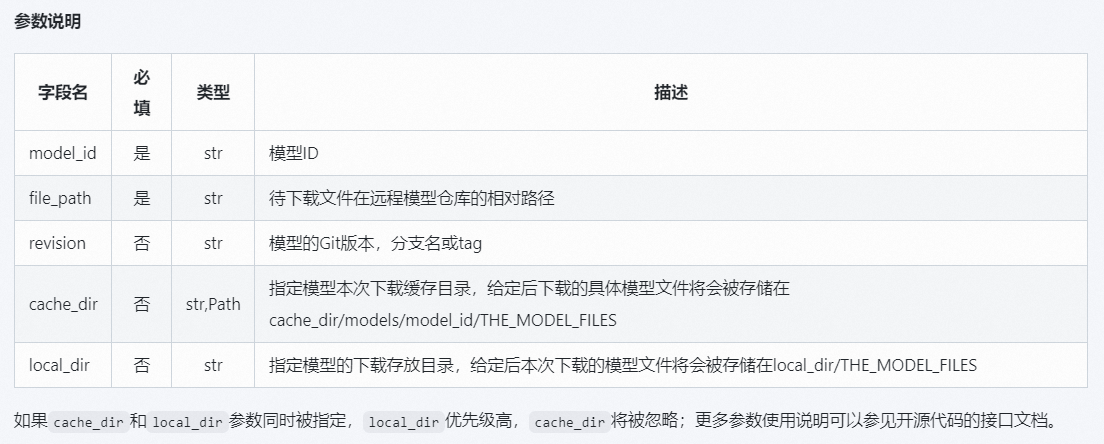
1.1.3通过Git下载:
2模型加载
2.1 transformers:
2.1.1 判断模型类型:纯文本模型、视觉模型、多模态模型?
方法 1:查看 config.json
- 进入模型目录(如
./my_model/txt_model)。 - 打开
config.json文件。 - 查找以下关键字段:
AutoModelForCausalLM:如果model_type是gpt2、llama、mistral等 → 纯文本模型。AutoModelForImageClassification:如果model_type是vit、swin等 → 视觉模型。VisionEncoderDecoderModel:如果model_type是vision-encoder-decoder→ 多模态模型。
方法 2:使用 AutoConfig 自动检测
from transformers import AutoConfig
config = AutoConfig.from_pretrained("./my_model/txt_model")
print(config.model_type) # 输出模型类型,如 "gpt2", "llama", "vit"
print(config.architectures) # 输出模型架构,如 ["GPT2LMHeadModel"]方法 3:尝试用 AutoModel 加载
Hugging Face 的 AutoModel 会根据 config.json 自动选择合适的模型类:
from transformers import AutoModel
model = AutoModel.from_pretrained("./my_model/txt_model")
print(type(model)) # 查看模型的实际类型
#可能的输出:
# <class 'transformers.models.gpt2.modeling_gpt2.GPT2LMHeadModel'> → 文本生成模型。
# <class 'transformers.models.vit.modeling_vit.ViTModel'> → 视觉模型。
# <class 'transformers.models.vision_encoder_decoder.modeling_vision_encoder_decoder.VisionEncoderDecoderModel'> → 多模态模型。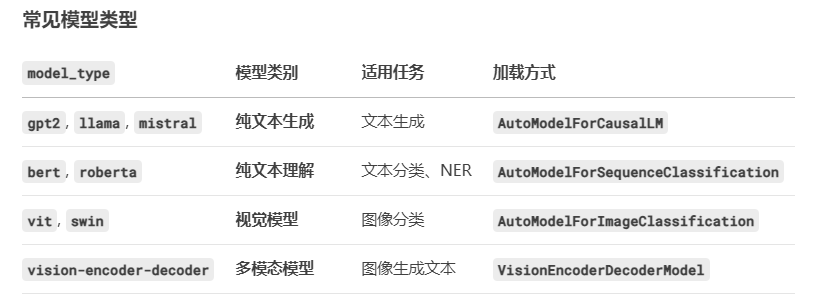
2.1.2加载本地部署模型
# 加载多模态模型
from transformers import VisionEncoderDecoderModel
model_path2 = "./my_model/PDF_analysis"
model = VisionEncoderDecoderModel.from_pretrained(model_path2)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









