







摘要——卷积神经网络在多模式协作领域越来越受到关注。近年来,基于CNN的方法在多源遥感数据分类中取得了显著的效果。然而,它在互补提取方面仍然面临挑战。在本文中,对抗性互补学习(ACL)策略被嵌入到称为ACL-NN的CNN模型中,用于提取多源数据的互补信息。所提出的ACL-NN能够通过进行对抗性的最大-最小博弈,从多源数据中过滤出常见模式和特定模式。特别是,与模态无关的常见模式构成了土地覆盖的基本表示,而特定模式与提供补充表示的常见模式线性无关。因此,互补信息被映射到紧凑的和有区别的表示。为了消除奇异噪声,设计了一个可学习模式采样模块(PSM)来提取特定模式之间的互斥关系。在三个数据集上进行的大量实验表明,与几种分类技术相比,所提出的ACL-NN具有优越性。
最近地球观测的成功归功于遥感的发展。遥感数据显示出空间、光谱和偏振特性,这取决于所用传感器的类型和测量的辐射[1]。其中,高光谱图像(HSI)值得特别关注,并提供了从可见光谱到红外光谱的高度相关信息,这促进了令人满意的分类结果[2]。然而,空间分量的分辨率受到信噪比要求的限制。幸运的是,多源遥感使全方位观测成为可能[3],[4]。合成孔径雷达(SAR)是一种高分辨率的相干成像雷达系统,具有全天候和全时观测的能力[5]。此外,多光谱图像(MSIs)和光探测与测距(LiDAR)分别具有表示形态和高程信息的优势,这与HSI是互补的。因此,如何将多源遥感数据完全融合成为一个关键问题。
集成多源信息的一种常见方法是数据融合。数据融合融合了不同数据源的优势,以重建更高质量的图像[6]。在[7]中,将输入图像解混合为纯反射率和相关的混合系数,从而实现了数据融合。Akhtar等人[8]提出了HSI超分辨率的非参数贝叶斯稀疏表示。Zhang和Prasad[9]提出了一种用于数据融合的鲁棒公式,其中稀疏系数受到自适应局部权重的约束。董等人[10]基于空间-光谱稀疏先验,通过高光谱字典和稀疏码联合估计高分辨率HSI。在[11]中,通过耦合稀疏张量分解将HSI和MSI融合。之后,开发了基于子空间的低张量多组正则化用于数据融合[12]。在[13]中,HSI和MSI通过深度卷积神经网络(CNN)融合,该网络结合了学习的深度先验。然而,数据融合更适合于提高均质传感器的数据质量,如HSI/MSI、MSI/全色图像等,其对异构数据的适用性差,容易导致信息丢失。
由于特征工程在图像解释中的成功[14],[15],研究人员已经通过特征融合进行了大量的协同分类实验。对于特征融合,将不同数据源的特征联合转换到高维空间中,然后设计分类器进行土地覆盖识别。支持向量机(SVM)和极限学习机(ELM)在土地覆盖分类中以其高效性而著称。在[16]中,通过SVM对HSI和激光雷达数据中投影的多源特征进行了联合分类。最近,消光剖面(EP)已被广泛用于表示空间特征,这试图有助于遥感数据分类[17],[18]。在[19]中,通过稀疏和低秩分量分析将基于EP的空间特征和光谱特征合并。在[20]中,采用EP从HSI和LiDAR中提取空间和高程信息,然后通过正交总变分分析将特征合并到较低维空间中。为了强调异构特征的相关性,多核学习(MKL)自然地在多个基核之间建立线性组合来学习最优基核。在[21]中,通过核对齐(KA)选择次优核,然后进行MKL来探索空间-光谱和高程属性的最佳组合。张等人[22]将主动学习(al)和MKL相结合,命名为集合MKL-al,以从HSI和激光雷达数据中识别额外的信息性和代表性样本。此外,一些最值得注意的方法也取得了很好的性能,如基于图的方法[23]、随机森林[24]、流形对齐[25]和分割[26]。然而,上述方法的成功采用取决于广泛的领域专业知识和先验知识,这既耗时又费力。
自从Krizhevsky等人[27]采用CNN进行图像识别以来,不同的基于CNN的扩展在检测、分割和自然语言处理方面取得了优异的性能[28],[29],[30],[31]。最近,基于CNN的方法在多源图像分类方面进行了大量尝试,也取得了很有希望的结果[32],[33]。例如,Ghamisi等人[34]利用CNN对叠加的EP和光谱特征进行分类。后来,Chen等人[35]提出了一种端到端的CNN,其中通过完全连接(FC)层融合从多光谱/高光谱和激光雷达数据中提取的特征。在[36]中,特征提取器是专门为不同的数据源设计的。在[37]中,将细胞神经网络耦合以相互学习,然后分别对特征融合和决策融合进行最大化和加权求和策略。近年来,一些特征交互方法已广泛应用于协同分类中。在[38]中,不同卷积层的潜在表示相互作用,形成联合表示。在[39]中,离开感知CNN被设计为集成多源特征。Gao等人[40]设计了一个深度交叉注意力模块(CAM)来强调相关性。李等人[41]构建了一个基于图的网络,其中利用转换图来增强HSI和MSI的关联。在[42]中,开发了一种多尺度交互式融合网络来融合多尺度信息。考虑到多源遥感数据的信息异质性和不平衡性,提出了非对称特征融合方案。在[43]中,独立批量归一化(BN)层的参数用于控制特征传播。在[44]中,非对称融合是通过移位特征融合和特征选择实现的。张等人[45]开发了一种基于结构优化传递的融合分类方案。李等人[46]设计了一个用于HSI和激光雷达数据分类的三重半监督深度网络。
尽管上述基于CNN的方法已经取得了很好的性能,但它们仍然存在以下问题。首先,冗余特征信息——如图1(a)所示,传统方法难以过滤出不同的特征模式,这不可避免地导致信息冗余[25],[47]。因此,迫切需要通过挖掘常见和特定的模式来构建互补特征,如图所示。第1(b)段。第二,干扰奇异噪声——如图1(b)所示,常见模式和特定模式分别表示土地覆盖的基本表示和辅助表示。事实上,补充表示受到干扰奇异性噪声(冗余频谱和斑点噪声)的影响,这削弱了不同模式叠加的互补性以及分类性能。因此,有必要探究特定模式之间的互斥关系。
为了解决上述问题,提出了一种基于对抗性互补学习的CNN(ACL-CNN)来对多源图像进行协同分类。首先,采用具有相同结构的四组编码器进行特征嵌入,其中使用具有共享权重的两组编码器作为公共编码器来提取公共模式。此外,具有独立参数的另外两组编码器是用于提取特定模式的特定编码器。在区分阶段,最大-最小对抗策略驱动模型准确区分模态标签,而特定模式与常见模式相关。在生成阶段,常见模式与情态无关,而特定模式是常见模式的线性独立性。为了在分类任务中探索特定模式的有意义信息,从而最大限度地提高收益,设计了模式采样模块(PSM),对特定模式进行加权积分进行分类。使用三个多源数据集对不同配置进行了广泛的实验,以验证其有效性。结果表明,与其他相关分类方法相比,所提出的ACL-CNN具有优越的性能优势。
所提出的ACL-CNN的主要贡献总结如下。1) 开发了一个ACL-CNN来挖掘多源遥感数据的互补优势,用于土地覆盖分类。利用通过互补学习策略优化的公共和特定编码器来提取不同数据源之间的公共模式和特定模式。然后,对具体的模式进行加权综合,以实现优势互补。2) 一方面,将常见模式输入到模态分类器中,以通过交叉熵(CE)损失来识别其模态标签。另一方面,特定模式受到均方误差(mse)损失的约束,以确保其与常见模式的线性独立性。ACL策略是通过在生成阶段最小化损失和在非歧视阶段最大化来执行的。因此,在生成阶段生成模态独立的通用模式和互补的特定模式。3) 为了消除奇异噪声,设计了一种PSM来提取特定模式之间的互斥关系。有意义的信息被明确强调,而不必要的信息被抑制。因此,奇异性噪声的问题得到了缓解。
本文的其余部分组织如下。第二节描述了拟议的分类框架。第三节通过讨论参数配置并与相关工程进行比较,验证拟议方法的性能。最后,第四节以一些评论和直接的未来研究路线结束了本文。
二、建议的分类框架。
在同一地理区域上获得的共同登记的多源遥感数据表示为[X1,X2,…,Xm,Y]。这里,[X1,X2,…,Xm]是以多源数据的相应像素为中心的补丁对,m是模态的数量,Y是标签。如图6所示,2,首先将补丁对馈送到生成器以获得嵌入特征,然后利用鉴别器通过对抗性策略过滤出常见和特定的模式。最后,设计了PSM来平衡不同特定模式的贡献。因此,实现了ACL,如下所述:
A.用于互补学习的编码器网络和模态分类器一般来说,多源遥感数据的常见和特定模式构成了紧凑和有区别的特征表示。然而,常见-特定模式的信息重叠会降低分类性能。具体而言,包含特定信息的共同模式会导致信息冗余,而包含共同模式的特殊模式会降低互补性。因此,本文设计了一个生成器(编码器)和鉴别器(模态分类器)来过滤出常见和特定的模式。
1) 编码器网络:以HSI和SAR图像为例,设计了用于特征嵌入的编码器。具体来说,使用两个独立优化的特定编码器来提取特定模式,并使用其他两个具有共享权重的公共编码器来提取不同模态的公共模式,如下所示: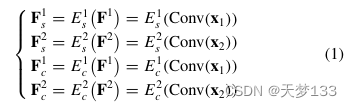 其中Conv(·)表示为卷积算子,用于匹配x1和x2之间的维度。x1,x2∈[x1,x2]表示补片对。F1s和F2s分别是HSI和SAR图像的特定模式。F1c和F2c是共同的图案。E1 s、E2 s、E1 c和E2 c是具有相同结构的编码器网络。编码器网络设计为ConvBN(d,d)→ ConvBN(d,d)→ ConvBN(d,d)。这里,b表示特定模式的维度。ConvBN由卷积层、BN层和ReLU函数组成。
其中Conv(·)表示为卷积算子,用于匹配x1和x2之间的维度。x1,x2∈[x1,x2]表示补片对。F1s和F2s分别是HSI和SAR图像的特定模式。F1c和F2c是共同的图案。E1 s、E2 s、E1 c和E2 c是具有相同结构的编码器网络。编码器网络设计为ConvBN(d,d)→ ConvBN(d,d)→ ConvBN(d,d)。这里,b表示特定模式的维度。ConvBN由卷积层、BN层和ReLU函数组成。
2) 模态分类器:为了生成与模态无关的常见模式,对抗性学习策略已经被实践并证明是有效的[48],[49]。模态分类器作为鉴别器来执行,鉴别器用于判断来自公共编码器的公共模式是否属于同一模态。模态分类器设计为FcBN(d,d)→FC(d,m)。这里,m·表示模态的数量。FcBN由FC层、BN层和ReLU功能组成。CE损失用于如下优化模态分类器:
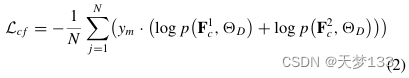
其中N是批量大小,ym是模态标签的一个热编码。HSI的模态标签为[1,0],而SAR模态的标签为[0,1]。p(·,D)表示模态分类器D的预测概率。在生成阶段,编码器网络通过生成与模态无关的常见模式来欺骗模态分类器,而在判别阶段,模态分类器试图正确区分常见模式的模态标签。因此,通过最大-最小博弈,多源公共模式是模态独立的。
为了提取与常见模式互补的多源数据的特定模式,采用mse损失来约束线性独立性,如下所示:
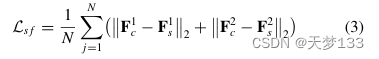
其中,‖·‖2表示L2范数。类似地,在生成阶段,特定编码器尝试生成与公共模式不相关的特定模式。在辨别阶段,我们试图使常见模式与特定模式相一致。因此,产生了不同模态的特定模式。一般来说,对抗性学习策略用于从多源数据中过滤出常见模式[F1c,F2c]和特定模式[F1S,F2s]。通过以下求和进一步增强了常见模式:
![]()
B.用于特征完整性的共享解码器上述常见编码器和特定编码器具有相同的结构;然而,它们是用不同的参数进行优化的。因此,常见模式和特定模式自然保持线性独立,容易造成捷径优化。为了驱动模型学习,共享解码器被设计为FcBN(2d,d)→ FC(d,d),其被计算用于特征重构如下:
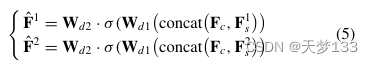
其中,trl F1和trl F2是重构的特征。Wd1和Wd2表示共享解码器中的两个FC层的权重矩阵。concat(·)是沿通道维度的串联算子,σ(·)为ReLU函数。重建特征的质量通过mse损失来评估,如下所示:
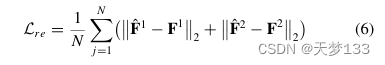
其中,trl F1和trl F2是重构的特征。因此,保证了特征的完整性,并将常见模式和特定模式引导到互补的优点中。
C.PSM和特征集成分类器
1)模式采样模块:常见和特定的模式具有以有针对性的方式表示数据特征的能力。常见的模式是土地覆盖的基本代表,而特定的模式则被用作补充代表。然而,一些冗余频谱和散斑噪声混合在特定图案中,这为分类提供了较小的贡献甚至负增益。因此,如图3所示,PSM被设计用于重新加权不同特定模式的分布。首先,将特定图案沿高度维度连接起来,如下所示:
![]()
通过注意力向量重新加权每个模式。通过采样方法获得的特征指数表示如下
![]()
其中ω=[π1,π2,…,πc],π={0,1}mx 1。采样权重是一个离散变量,表示每个通道位置的互斥关系(0或1)。考虑到互斥关系的优化,采用Gumbel softmax技巧对离散变量进行重新参数化[50]。具体来说,ω表示如下:
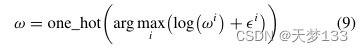
其中oi是类概率,εi是随机变量,i∈{1,2,…,m}。Gumbel分布是单纯形上的连续分布,可以对其进行采样以生成随机变量ε。ε表示如下:
![]()
在实践中,argmax(·)运算不是差分运算。因此,argmax的连续和微分近似是通过softmax函数实现的,如下所示:
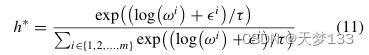
其中t-0是温度参数。当温度接近0时,来自Gumbel softmax分布的样本是热的,并且与分类分布相同。因此,采样的特定模式计算如下:
![]()
其中Fs∈Rc×m×1是采样的特定模式。hsum(·)是沿高度维度的平均算子。最后,通过如下连接公共模式和重新采样的特定模式来生成输出特征:
![]()
其中F∈R2c×1×1表示输出特征。
2) 分类器:对于土地覆盖分类,使用类别f ier来预测标签,其设计为FcBN(2d,d)→FC(d,C)。这里,C表示类的数量。通过接收输出特征F来生成概率分布。为了区分不同类别的特征,CE损失用于如下优化:
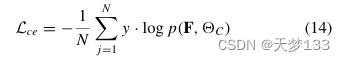
其中y是类标签的一个热门编码,p(·,C)是分类器C的预测概率。
D.优化算法和ACL-NN的分析在本文中,所提出的方法是使用ACL策略进行端到端优化的。特别是,生成器(编码器)和鉴别器(模态分类器)作为最大-最小游戏运行,目标是在优化时击败对方。共享解码器和分类器分别用于特征完整性和标签预测。因此,发电损耗Lgen和判别损耗Ldis定义如下:
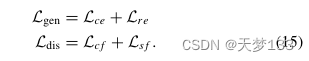
对抗性学习策略是通过交替最小化和最大化总损失来实现的,如下所示:
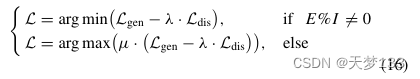
其中L是总损失,λ是用于平衡生成损失和辨别损失之间的权重的超参数。根据经验,判别损失在优化过程中更容易收敛。因此,利用间隔I=5来调整发生器和鉴别器的交替训练。也就是说,鉴别器每I个时期优化一次。µ=1.0用于调整区分阶段的权重。采用随机梯度下降(SGD)算法对整个算法进行了300个历元的训练。所有实验均在Pytorch 1.9.0软件平台上实现。硬件环境由Intel Core i7-9700@3.00-GHz CPU、40 GB DDR4和Nvidia GTX 3070Ti GPU组成。图4和图5显示了训练损失与时期数量之间的关系。从曲线中可以发现,生成损耗趋于稳定收敛,这符合准确分类的期望。辨别损失从曲线的低点逐渐上升到大约0.07。这意味着模态分类器难以区分常见模式,并且特定模式与常见模式线性无关。如图6所示,5,总损失倾向于与对抗性最大-最小博弈收敛。此外,图6说明了奥格斯堡数据集上不同模块的中间特征可视化;从而直观地显示了有效性。具体来说,我们随机选择比例特征进行可视化,包括原始特征、常见模式、常见和特定模式,以及PSM的输出特征。从图。6(a)和(b),观察到不同类别的原始特征不易区分,并且公共模式的基本表示直到限制了特征区分。在本文中,将常见模式和特定模式进行集成,以生成复杂的特征表示,与极常见模式相比,这显著提高了特征判别能力,如图所示。第6(c)段。图6(d)表明PSM进一步消除了特征冗余;因此,同一类的特征是相互重合的,而不同类的特征之间存在较大的差异,这表明了所提出的框架的有效性。
III、 实验结果与讨论
在本节中,对实验数据的描述和“配置”进行了清晰的说明,然后进行了全面的“实验”,以验证“提出的ACL细胞神经网络及其所有组件的有效性。
- 实验数据
Berlinda是由空间分辨率为30m的HyMap高光谱传感器在Berlina进行的测量,该传感器可以在网站上免费下载。1 HyMap高分辨率传感器记录了从可见光到400–2500nm红外波长的土地覆盖物的光谱信息。与地理位置相对应的SAR图像是从欧洲航天局(ESA)下载的神舟一号卫星的双极化(VV–VH)单视复合体(SLC)。将SAR数据输入到基于SNAP工具箱的预处理工作流中,2包括位校正、辐射测量校正、穿透等。柏林场景的像素数为1723×476。奥格斯堡数据集包含HS、SAR和数字表面模型(DSM)图像,这些图像分别由HySpexsensor、Sentinel-1卫星的C波段SAR传感器和DLR-3K系统捕获。HSI具有180个光谱带,范围从400到2500nm。DSMimage和“SARimage”分别提供了后盖的升降和极化信息。奥格斯堡场景中有332x485个像素。
YellowRiverEstuarydata集由HS、SAR和MS图像组成,分别提供丰富的光谱、偏振和文本信息。利用紫原1—02号卫星在山东省黄河河口拍摄了HSI和MSI。MSI和MSI的空间分辨率分别为30和10m。其中近红外波段76个,短波红外波段90个。与地理位置相对应的SAR图像由Sentinel-1卫星拍摄。黄河流域是一个960×1170像素的大型企业。三个数据集的伪彩色图像如图所示。7。柏林和奥格斯堡数据集的地面实况(GT)图是通过使用OpenStreetMap数据生成的[51]。YellowRiverEstuaryd数据集被标记为油田投资。表I中列出了培训测试样本的数量。此外,数据扩充是在后台使用的。具体来说,农业脆弱性种子是为旋转、翻转和噪声生成的。因此,训练样本的数量被扩展了好几倍。这里,80%的训练样本用于训练,其余20%用于验证。
B.实验设置设计了三组实验来评估所提出的方法在多源遥感图像分类任务中的性能。
1) 考虑到不同的邻域大小r、判别损失的超参数λ和编码器网络的深度n,测量了三个数据集的分类结果。此外,通过烧蚀实验验证了所提出的ACL-NN模块中组件的有效性。候选集定义为[r=7,9,11,13,15,17]、[λ=0.001,0.005,0.01,0.1]和[n=2,3,4,5]。
2) 为了进行比较,使用了几种相关技术对多源数据进行分类,包括SVM[52]、局部二进制模式和ELM(LBP-ELM)[53]、共享和特定特征学习(S2FL)[25]、双分支CNN(TBCNN)[36]、耦合CNN(CPCNN)[37]和深度特征交互网络(DFINet)[40]。特别是对叠加的多源图像进行了SVM和LBP-ELM处理。其他方法通过特征融合实现信息集成。
3) 最后进行了实验,进一步分析了该方法的鲁棒性。具体而言,基于候选集[20%、40%、60%、80%]的训练样本数量用于验证少镜头场景中的分类性能。此外,该方法还可扩展地部署在三个数据源的协同分类场景中。总体准确度(OA)主要用于评估性能。此外,还考虑了平均精度(AA)、类别精度(CA)和kappa系数(kappa)定量分析。对于实验2),生成分类图以评估一些典型区域的性能
C.实验1:参数分析
1)邻域大小分析:对于逐像素分类,通过中心像素的图像补丁来获得邻域信息,以增强特征表示。OA与不同邻域大小r之间的关系如图所示。8。这里,从候选集合[r.7,9,11,13,15,17]中选择最接近的borhood大小。对于柏林和黄河口数据集,当r从7增加到13时,OA值不断增加。当r=13时,OA值接近最大值,增加了1%以上。因为较大的邻域大小稀释了中心像素,所以随着r增加到大于13,OA值略有增加甚至减小。这是一个合理的选择。对于Augsburg数据集,OA值在r=11时达到最大值,因此选择11作为最佳邻域大小。
2) 权重超参数分析:对于ACL,识别损失用于区分模态标签和特征模式。定义了一个超参数λ来平衡发电损失和区分国家损失的贡献。根据经验,λ设置为[0.001,0.002,0.005,0.01]。OA和重量hyperram醚之间的关系列于表II中。随着判别损失的权重增加到0.005,分类性能逐渐恶化。当λ=0.001时,所提出的ACL-NN在三个数据集上实现了良好的性能。
3) 编码器深度分析:常见/特定编码器由几个串联的卷积层组成。然而,增加卷积层的数量会引入大量需要优化的参数。这对训练集的数量提出了更高的要求。接下来,我们讨论卷积层数对OA的影响。如图9所示,深度为2的编码器无法满足准确率分类的需要。也就是说,高级语义特征依赖于更深层次的编码器。研究发现,深度为4的编码器考虑了模型优化和特征嵌入。
4) 消融实验:在本节中,通过消融实验讨论了所提出的ACL-NN的组件,包括鉴别器和PSM。a) 模式采样模块:表III中的索引1-4描述了不同融合方法的有效性。具体而言,选择了几个注意力模块进行性能验证,包括连接(Concat)运算器、挤压和激励模块(SEM)[54]、CAM[55]和PSM。当采用Concat对特定图案进行积分时,精度的提高显然是有限的。这是因为特定图案中的噪声元素降低了增益。SEM表明,通道注意力是在Concat的特征上实现的。因此,进一步提高了分类精度。CAM通过注意力权重来强调有意义的信息,以获得有竞争力的表现。相比之下,PSM实现了卓越的优先性能,并且PSM可以轻松扩展到具有更多模式的其他场景。
b) 鉴别器:表III中的索引5报告了OA和鉴别器之间的关系。PSM*意味着在没有鉴别器的情况下提取公共和特定模式。结果表明,该鉴别器有效地过滤了多源数据中的常见模式和特定模式,在三个数据集上分别使分类准确率提高了至少7.65%、3.03%和4.03%。这证实了ACL提取的常见模式和特定模式更具鉴别性。
D.实验2:分类性能和分析本节重点验证所提出的ACL-NN相对于一些最著名的分类技术的性能。第III-B节中涉及的分类指标通过表格进行报告。对于定性分析,展示了由具有最佳和次优性能的方法生成的分类图。
1) 柏林数据集的结果:从表IV中可以看出,以柏林场景为中心,所提出的方法在OA、AA和Kappa方面实现了一致的改进,这主要是由于对建筑区域(2类、3类和7类)的强大识别能力。在所有的竞争对手中,基于CNN的方法优于SVM和LBP-ELM。这是意料之中的,因为这些方法自动联合多源特征,这提供了比SVM和LBP-ELM中的级联更具判别力的信息。在几种基于CNN的方法中,DFINet实现了第二高的OA值。然而,OA值仍比所提出的方法低5.56%。此外,DFINet图10中的分类图往往相当嘈杂,主要是因为一些工业区和住宅区被错误地分类为商业区。所提出的方法能够生成清晰的分类图,更接近土地覆盖的真实分布。
2) Augsburg数据集的结果:以Augsburg场景为中心,分类图如图所示。11,而CA、OA、AA和Kappa值如表V所示。作为一般评论,所提出的ACL-NN在全局度量方面取得了显著改进。例如,所提出的方法始终优于其他竞争对手,在OA、AA和Kappa方面至少提高了1.3%、0.3%和0.0206%。如表五所示,频谱分类器(SVM和LBP-ELM)未能获得令人满意的结果,这可以通过可学习特征融合来克服。特征融合方法实现了相对接近的性能,而所提出的方法在区分建筑区域方面仍然很好。如图11所示,可以更准确地识别住宅区和工业区,从而更好地划定边界。3) 在黄河口数据集上的结果:以黄河口场景为中心,与性能次优的方法相比,所提出的方法在OA方面提高了约2.5%。从表VI中可以看出,所提出的ACL-NN在有碱蓬和Tamarix森林(2类和3类)的复杂地区获得了更高的精度。对于SVM和LBP-ELM,OA值与ACL-NN的OA值几乎没有差异。这是因为Tamarix森林(3级)的精度相对较低,导致AA值较低。如图6所示,如图12(a)所示,具有第二高OA值的CPCNN受到伪影和碎片的影响,从而生成视觉上有噪声的分类图。相反,所提出的ACL-NN生成的分类图具有更少的错误标记像素。此外,如图7(c)所示,HSI中的一些区域被云层覆盖。相比之下,无论天气条件如何,相应的“SAR图像都有能力生成观测结果”。因此,通过自适应地增强SAR图像的互补表示来实现云遮蔽区域的陆地覆盖分类。
总的来说,与竞争对手相比,所提出的方法在定量和定性分析方面取得了最佳性能。这些比较表明,ACC策略能够过滤出不同的模式,从而消除特征歧视。
E.实验3:分析性能扩展在实际应用中,大多数技术的覆盖分类都暴露了各种数据源的限制或标签不足。因此,本节进一步分析了所提出方法的性能扩展。1) 使用三种模式分析性能:奥格斯堡数据集有一个额外的DSM图像,其中包含丰富的高程信息。黄河河口数据集的MSI提供了互补的纹理信息。因此,所提出的ACL CNN是在遥感数据的基础上进一步实现的。模态贝尔分别定义为[1,0,0]、[0,1,0]和[0,0,1]。歧视损失和世代损失重新定义如下:
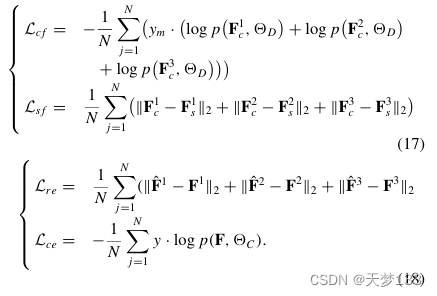
三种模式的结果如表VII所示。比较方法(SVMandLBP-ELM)通过连接HSI、SAR图像和DSM/MS图像来接收三种模态。可以观察到,SVMand-LBP ELM略微提高了性能,而所提出的CAL-CNN在使用三种模式的八月和黄河河口数据集SWITTHREEMODALIES上的DIFERENT方法对表VII的类别-特定类别-准确度(%)达到了一致的目标验证2.13%和1.32%。具体而言,对于Augsburgscene,具有规避信息的RSM图像将分类准确度第4类(低植物)和第6类(商业区)分别显著提高了6.06%和6.90%。对于黄河口场景,4类(潮溪)和5类(滩涂)的发生率大大提高。这表明纹理信息有利于转换类型的认知。总的来说,所提出的ACL CNNI可以将分类任务扩展到更多的模式,从而进一步增强互补信息的提取。
2) OA与训练样本数之间的关系分析:基于CNN的网络模型需要大量的标记样本进行优化。然而,在遥感图像注释的任务中,实地调查是必不可少的,这既耗时又费力。如图所示。13,随机选择不同比例[20%、40%、60%、80%]的训练样本进行模型验证。为了更好地进行分析,没有显示某些比较方法的曲线。一般来说,与其他竞争对手相比,所提出的ACL-NN能够保持相对优越的OA值。对于基于CNN的方法,当训练样本的比例小于60%时,分类性能显著降低,尤其是对于TBCNN。这是因为与TBCNN相比,CPCNN通过模型耦合减少了模型参数,DFINet通过多个损失函数引导有偏估计,从而减少了对训练样本的依赖。与DFINet类似,所提出的ACL-NN通过多个损失函数进行联合优化。因此,将解正则化到较小的范围内,从而提高了在少镜头场景中的性能。
四、结论
本文提出了一个ACL-CNN,旨在提高分类性能。总的来说,拟议的ACL-CNN从两个方面受益。一个是对抗性的最大-最小游戏,用于过滤多源数据的常见模式和特定模式。共同模式能够基本描述土地覆盖的特征。线性独立于公共模式的特定模式提供了补充信息。然而,产生了紧凑和有区别的特征。另一个是消除单一噪声的PSM。特定模式之间的相互排斥关系由PSM提取。使用三个多源数据集进行的实验结果证明了拟议方法引入的显著改进。因此,有意义的信息被保留,而不必要的信息被抑制。此外,所提出的ACL-NN提供了一种高效的机制来将其自身扩展到具有更多模态的场景。尽管所提出的ACL-NN提供了高准确性和灵活性,但随着时间的推移,仍有一些未解决的问题可能会带来挑战。特别是,我们未来的工作将针对以下方向:1)损失函数权重参数的自适应分配,2)引入先进的数据增强或迁移方案,以提高少镜头场景的模型鲁棒性

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









