






 本文详细阐述了Spring Bean的初始化过程,包括Bean的加载方式、BeanDefinition解析、BeanFactoryPostProcessor的作用,以及单例与多例模式的选择及其生命周期。深入讲解了Aware接口和BeanPostProcessor在Bean创建中的角色。
本文详细阐述了Spring Bean的初始化过程,包括Bean的加载方式、BeanDefinition解析、BeanFactoryPostProcessor的作用,以及单例与多例模式的选择及其生命周期。深入讲解了Aware接口和BeanPostProcessor在Bean创建中的角色。
一、Bean的初始化过程
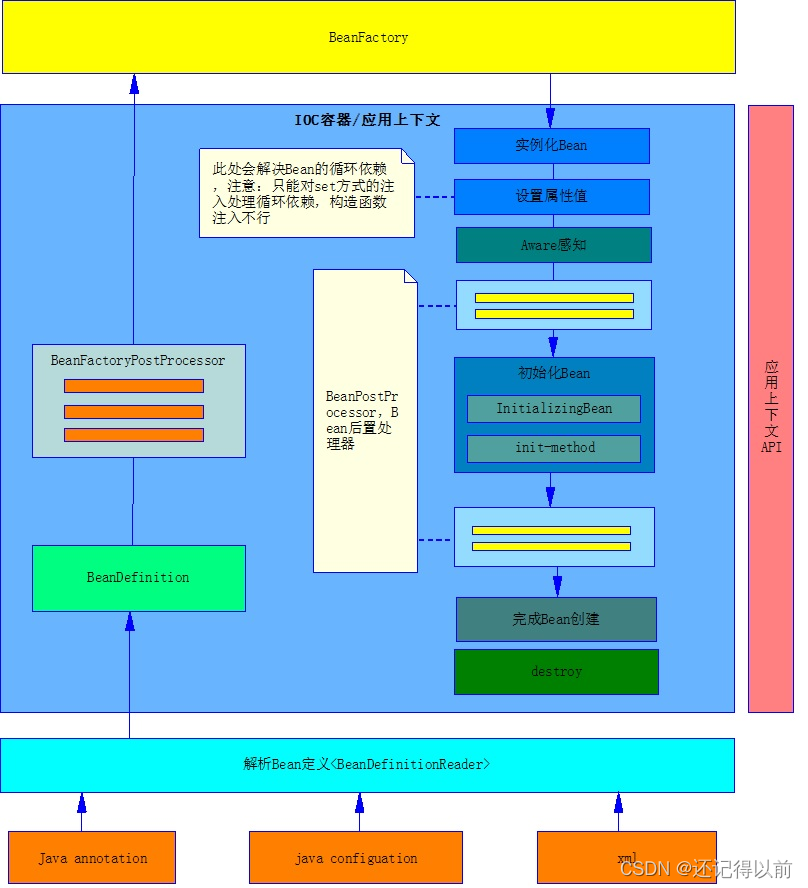
Spring Bean的生命周期:
1、通过XML、Java annotation(注解)以及Java Configuration(配置类)
等方式加载Spring Bean
2、BeanDefinitionReader:解析Bean的定义。在Spring容器启动过程中,
会将Bean解析成Spring内部的BeanDefinition结构;
理解为:将spring.xml中的<bean>标签转换成BeanDefinition结构
有点类似于XML解析
3、BeanDefinition:包含了很多属性和方法。例如:id、class(类名)、
scope、ref(依赖的bean)等等。其实就是将bean(例如<bean>)的定义信息
存储到这个对应BeanDefinition相应的属性中
例如:
<bean id="" class="" scope=""> -----> BeanDefinition(id/class/scope)
4、BeanFactoryPostProcessor:是Spring容器功能的扩展接口。
注意:
1)BeanFactoryPostProcessor在spring容器加载完BeanDefinition之后,
在bean实例化之前执行的
2)对bean元数据(BeanDefinition)进行加工处理,也就是BeanDefinition
属性填充、修改等操作
5、BeanFactory:bean工厂。它按照我们的要求生产我们需要的各种各样的bean。
例如:
BeanFactory -> List<BeanDefinition>
BeanDefinition(id/class/scope/init-method)
<bean class="com.zking.spring02.biz.BookBizImpl"/>
foreach(BeanDefinition bean : List<BeanDefinition>){
//根据class属性反射机制实例化对象
//反射赋值设置属性
}6、Aware感知接口:在实际开发中,经常需要用到Spring容器本身的功能资源
例如:BeanNameAware、ApplicationContextAware等等
BeanDefinition 实现了 BeanNameAware、ApplicationContextAware
7、BeanPostProcessor:后置处理器。在Bean对象实例化和引入注入完毕后,
在显示调用初始化方法的前后添加自定义的逻辑。(类似于AOP的绕环通知)
前提条件:如果检测到Bean对象实现了BeanPostProcessor后置处理器才会执行
Before和After方法
BeanPostProcessor
1)Before
2)调用初始化Bean(InitializingBean和init-method,Bean的初始化才算完成)
3)After
完成了Bean的创建工作
8、destory:销毁
二、Bean的单例与多例模式
1)单例:
优点:减少内存的使用,也是bean默认的创建方式
缺点:会存在变量污染的问题
2)多例:
优点:不存在变量污染
缺点:耗内存
3)单例与多例选择:
是否会对bean对象中的属性进行修改,如果会使用多例,如果不会使用单例。
4)单例的生命周期
伴随容器的生成与销毁
5)多例的生命周期
bean在使用的时候才进行初始化,销毁与容器五个,与java的垃圾回收机制有关

















 1048
1048

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









