









YOLOv3 (You Only Look Once Version 3) 是 YOLO 系列目标检测算法的第三个版本,继 YOLOv1 和 YOLOv2(YOLO9000)之后的又一次重要改进。YOLOv3 在精度、速度、以及对小物体的检测能力上都有显著提升,并且增加了一些新的技术,如更强的网络架构、更有效的目标检测方法等。
YOLOv3 的主要特点与改进
1. 更深的网络架构(Darknet-53)
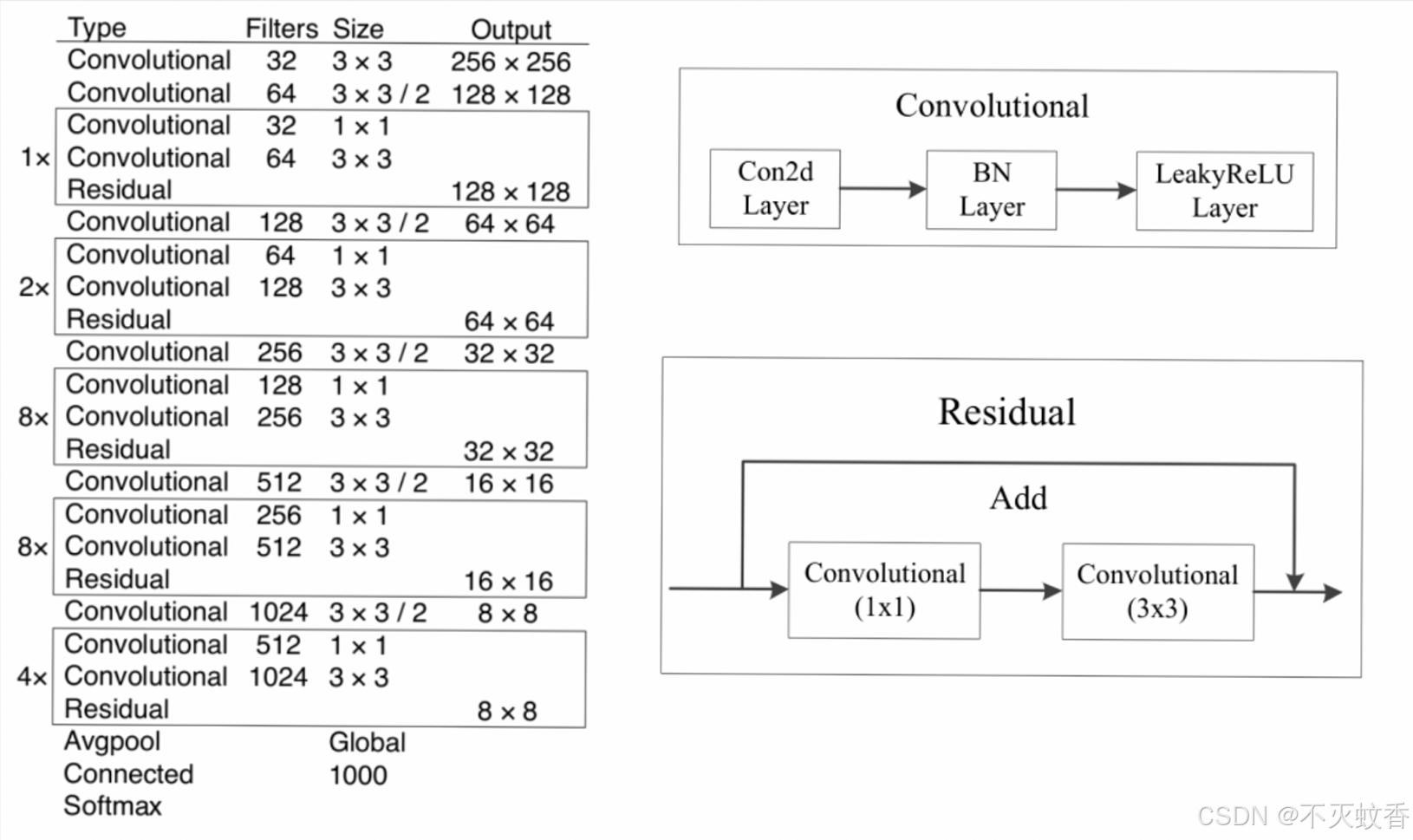
- YOLOv3 使用了一个新的特征提取网络 Darknet-53,这是一个比 YOLOv2 中的 Darknet-19 更深的卷积神经网络(CNN)。Darknet-53 是由 53 层卷积层和残差连接构成,它在图像特征提取上表现出了更强的能力,尤其是在更复杂的场景下。
- 相比于 YOLOv2,Darknet-53 更适合处理高分辨率图像,因此可以更好地检测小物体。
2. 多尺度预测(预测不同尺度的物体)

- YOLOv3 采用了 多尺度预测(Multi-Scale Prediction),即在不同的尺度上进行目标检测。它在网络的不同层次上进行物体的检测,每一层都会预测不同大小物体的位置和类别。
- 网络的输出由三个不同的尺度组成(高层、中层、底层),这使得 YOLOv3 在小物体和大物体的检测上都能保持较好的平衡,尤其是对于小物体的检测表现更加优秀。
- 具体来说,YOLOv3 会从最后的三个卷积层分别输出三个不同尺寸的特征图,从而预测不同大小物体。
3. 改进的目标检测框架:使用逻辑回归进行类别预测
- 在 YOLOv2 中,类别预测采用了 sigmoid 激活函数和交叉熵损失函数,而 YOLOv3 则采用了 逻辑回归(Logistic Regression)来为每个边界框的类别分配概率。
- YOLOv3 使用了多标签的逻辑回归,而不是每个类别一个独立的概率输出,这样可以更好地处理多类别情况。
- 这种改进使得 YOLOv3 在处理多物体和重叠物体的情况下表现更加稳定,尤其是对于物体类别较多时,能更好地进行分类。
4. 引入了更精确的目标框(Bounding Box)预测
- YOLOv3 采用了 独立的 x, y, w, h 回归,并使用了更精确的预测方法来提高目标框的预测精度。
- YOLOv3 不仅优化了对物体位置(x, y)的预测,还通过 IoU(Intersection over Union) 来评估框的质量,进一步提高了对物体边界的准确定位。
5. 使用了更精确的 BCE 损失函数(Binary Cross-Entropy Loss)
- 在 YOLOv3 中,损失函数的计算方式更为精细,采用了 BCE损失(Binary Cross-Entropy Loss)来减少误差。这让 YOLOv3 在边界框的回归和类别分类方面都表现得更加精确。
6. 更高效的训练过程:使用 Darknet-53 替代 Darknet-19
- YOLOv3 在训练中采用了 Darknet-53,它通过残差连接(Residual Connections)和更深的网络层次进一步提高了模型的表现力。相比于 YOLOv2 中的 Darknet-19,YOLOv3 的训练过程能够提取更多的信息,尤其是当目标检测涉及到多个类别或者复杂背景时。
- Darknet-53 是一个强大的特征提取器,能处理更复杂的图像,减少了多物体重叠、大小变化等场景下的漏检和误检。
7. 支持多个框架:Darknet, TensorFlow, PyTorch
- YOLOv3 支持多个框架,原生支持 Darknet(YOLO的原始框架),同时也可以转换为 TensorFlow、PyTorch 和其他深度学习框架进行训练和推理,这使得 YOLOv3 具有更强的灵活性。
YOLOv3 的网络架构
YOLOv3 网络结构的总体框架如下:
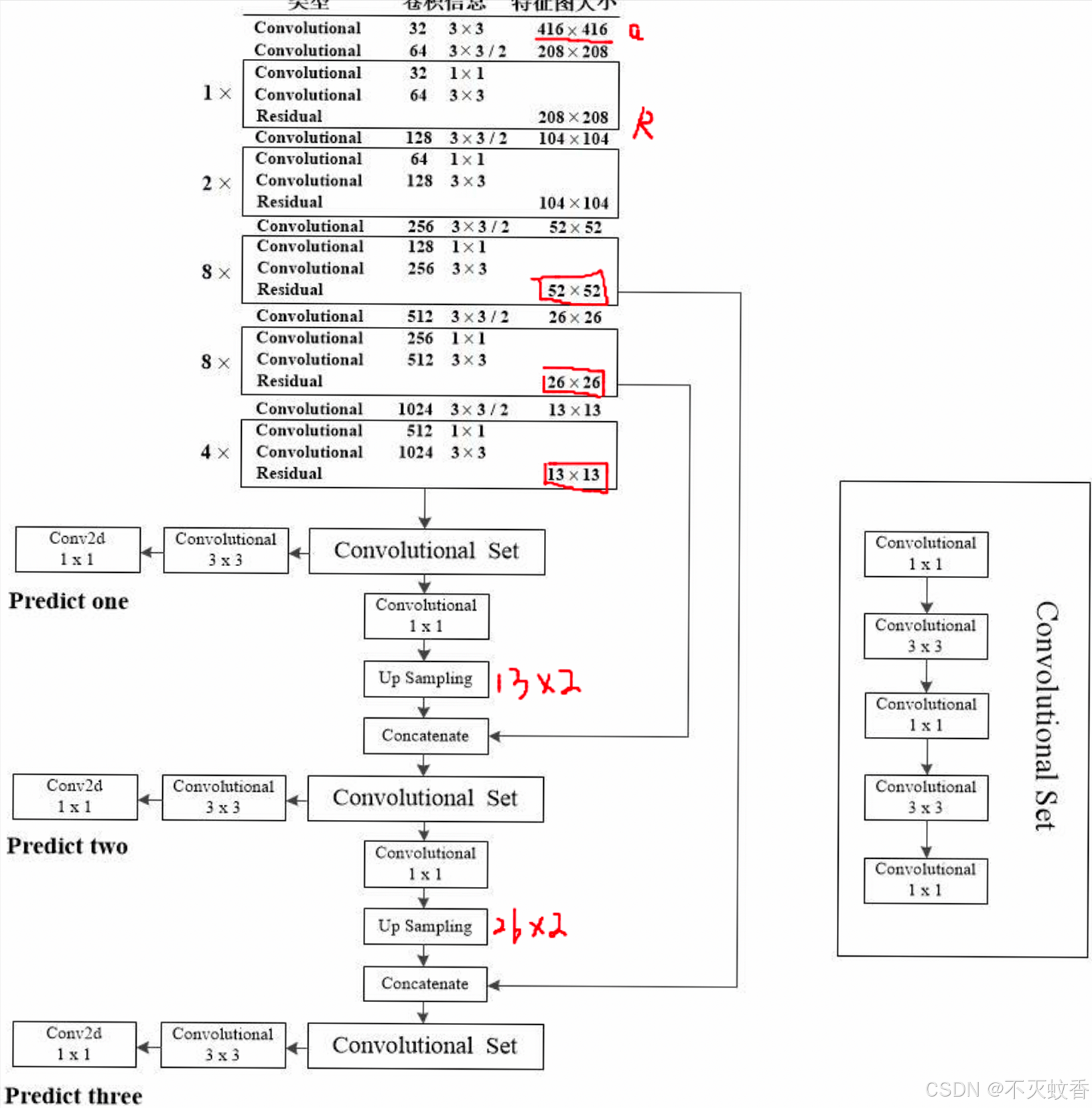
-
输入层:
- YOLOv3 接受一个固定大小的输入图像,通常为 416×416 或 608×608,在网络中会对输入图像进行缩放,使其适应网络的输入要求。
-
Darknet-53(特征提取层):
- 使用 Darknet-53 作为特征提取网络,通过卷积层和残差连接提取图像特征。这个阶段的输出包含丰富的高层次特征信息。
-
检测头(Detection Head):
- YOLOv3 在网络的多个层次上进行物体的检测,输出每个边界框的 x, y, w, h (位置与大小)、置信度和类别概率。
- 网络会生成多个尺寸的输出,以适应不同大小的物体。
-
输出层:
- 最终输出的张量的维度为 S × S × (B × 5 + C),其中:
- S × S:网格的大小(通常为 13×13, 26×26, 52×52 等)。
- B:每个网格单元的锚框数量(YOLOv3 通常使用 3 个锚框)。
- 5:每个锚框的预测信息(位置:x, y, w, h 和置信度)。
- C:类别数(不同的物体类别,YOLOv3 可以进行多类别检测)。
- 最终输出的张量的维度为 S × S × (B × 5 + C),其中:
YOLOv3 损失函数
YOLOv3 的损失函数主要由三部分组成:
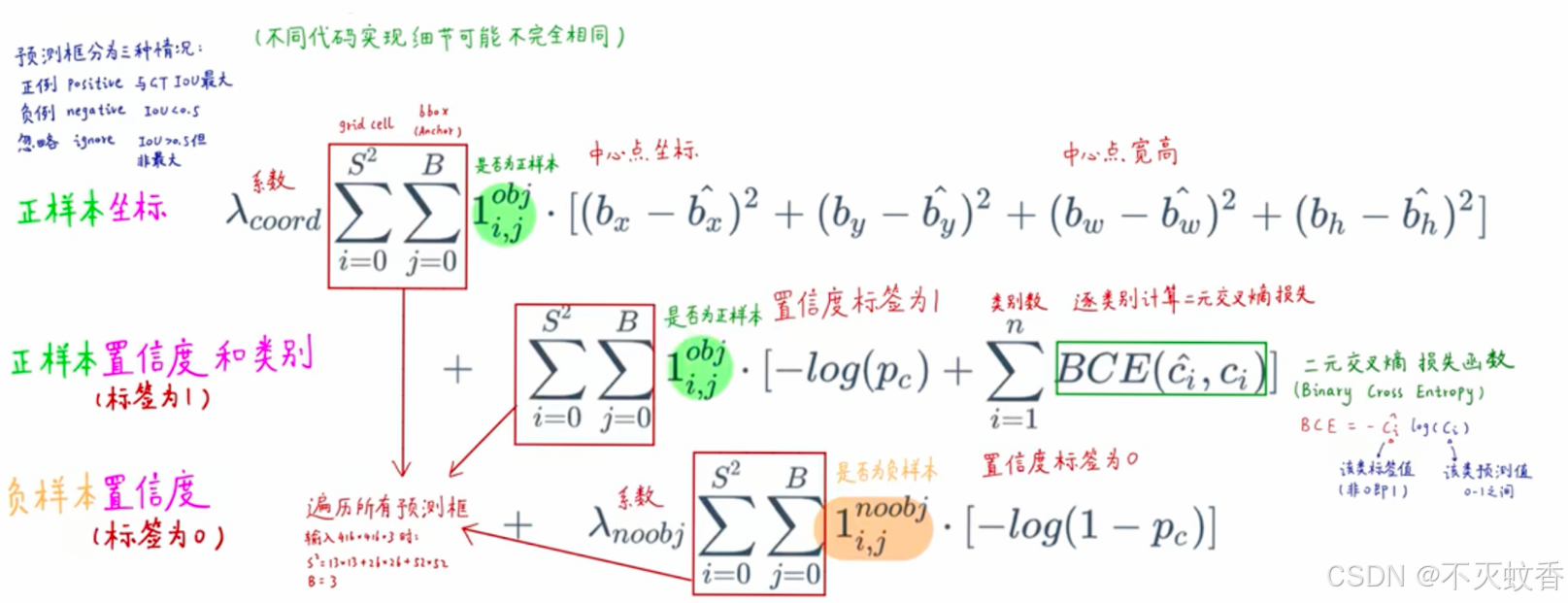
- 定位损失(Localization Loss):通过回归边界框位置(x, y, w, h)的预测来计算误差。
- 置信度损失(Confidence Loss):计算预测的置信度与真实值之间的差异。
- 类别损失(Classification Loss):使用 BCE(Binary Cross-Entropy)损失计算类别概率预测的误差。
YOLOv3 的优缺点
优点:
-
高效的实时目标检测:
- YOLOv3 保持了 YOLO 系列一贯的高效性,能够进行实时的目标检测。
-
精度提升:
- 相较于 YOLOv2,YOLOv3 在多个尺度上进行预测,因此对于不同尺寸的物体(尤其是小物体)的检测性能大大提升。
-
支持多类别检测:
- YOLOv3 支持多达 80 种物体的检测,适合应用在复杂环境中,能够处理大规模的物体类别问题。
-
灵活性和兼容性:
- YOLOv3 支持多种框架,包括原生的 Darknet、TensorFlow、PyTorch 等,具有较高的灵活性,能够方便地进行模型的迁移和部署。
缺点:
-
对密集目标的检测仍然有一定挑战:
- 对于密集物体(如大量重叠物体)的检测,YOLOv3 可能仍然存在误检或漏检的情况。
-
训练过程较为复杂:
- YOLOv3 的训练过程相对复杂,需要更多的计算资源(尤其是在训练大规模数据集时),同时对硬件性能要求较高。
-
小物体检测仍然存在挑战:
- 尽管 YOLOv3 在小物体检测上有了一定改进,但仍然不如一些基于区域提议的方法(如 Faster R-CNN)在精度上表现得更好,特别是对于极小物体的检测。
YOLOv3 总结
YOLOv3 是一个在速度和精度上都非常优秀的目标检测模型。它通过多尺度预测、深层的网络架构(Darknet-53)、改进的目标框预测方式等技术,极大地提升了检测精度,尤其是在小物体和多物体场景下的表现。由于其高效性和实时性,YOLOv3 在各种实时目标检测任务中得到了广泛应用,如视频监控、自动驾驶、智能安防等领域。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









