







GoogLeNet 是 Google 提出的卷积神经网络架构,最著名的是在 ILSVRC 2014(ImageNet Large Scale Visual Recognition Challenge)中赢得了冠军。GoogLeNet 引入了很多创新的设计,其中最具代表性的就是 Inception 模块,它大大提高了卷积神经网络的效率,并显著减少了模型的计算复杂度。
GoogLeNet 的主要特点
-
Inception 模块: GoogLeNet 的核心创新是 Inception 模块,它通过并行使用多个不同大小的卷积核(如 1x1, 3x3, 5x5 卷积核)和池化操作来提取不同尺度的特征。这种设计不仅能捕获更丰富的特征,还能有效减少模型参数的数量。
-
1x1 卷积: GoogLeNet 在多个地方使用了 1×1 卷积,这对于减少计算量和参数量非常有效。特别是在 Inception 模块中,1×1 卷积用于降维(即通过减少通道数来减少计算量),这使得网络在保持高性能的同时也能避免计算过多的冗余特征。
-
深度分离卷积(Depthwise Separable Convolutions): 这种方法通过将卷积操作分解为两个步骤来减少计算量:首先执行每个输入通道的卷积,然后执行一个逐点卷积。这不仅减少了计算量,还提高了效率。
-
全局平均池化: 在 GoogLeNet 中,传统的全连接层被替换为 全局平均池化(Global Average Pooling),它通过对每个通道进行全局平均池化(即对每个特征图进行平均),然后直接将其传递到输出层。这不仅减少了模型的参数数量,还能避免过拟合问题。
-
层次深度: GoogLeNet 是一个非常深的网络,包含了多个 Inception 模块。相比于传统的深度卷积网络,GoogLeNet 的结构设计使得它能够达到更高的深度,同时保持较低的参数量。
-
参数量少: GoogLeNet 的设计旨在减少参数的数量,尽管其层数深且复杂,但由于使用了 1×1 卷积和全局平均池化,GoogLeNet 的参数量远远低于许多传统的深层神经网络(如 VGG)。
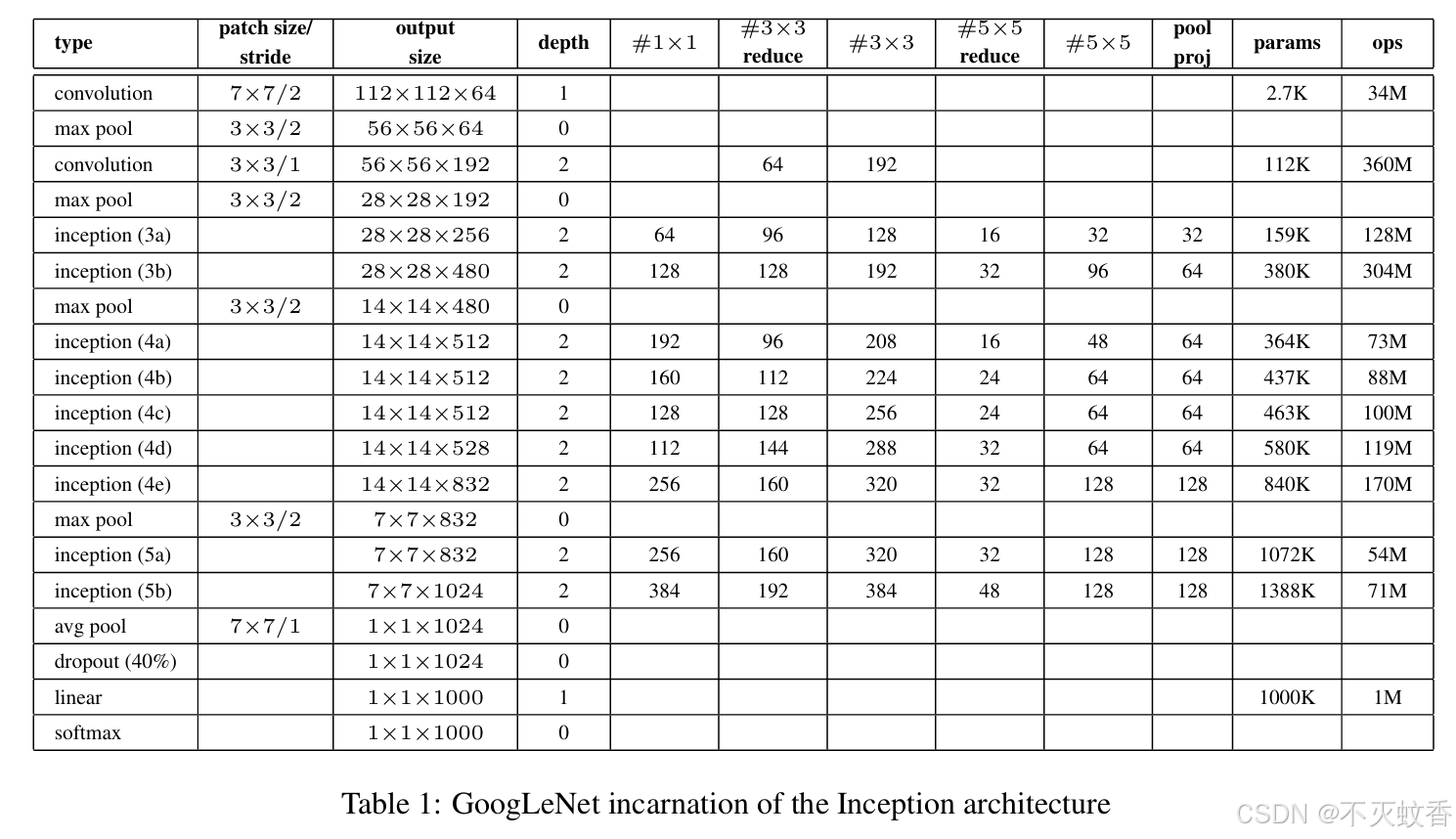
GoogLeNet 网络结构
GoogLeNet 网络的结构由多个 Inception 模块 组成,整个网络的结构如下:
- 输入层:大小为 224×224×3 的图像。
- 卷积层:使用一个 7×7 卷积核,步长为 2,随后是一个 3×3 的最大池化层,步长为 2。
- Inception 模块:多次重复 Inception 模块,每个模块中包含多个卷积操作,分别使用不同尺寸的卷积核(如 1×1、3×3、5×5)以及池化操作。
- 全局平均池化:最后一层是全局平均池化层,大小为 1×1。
- 输出层:一个全连接层用于分类任务,通常是 1000 类。
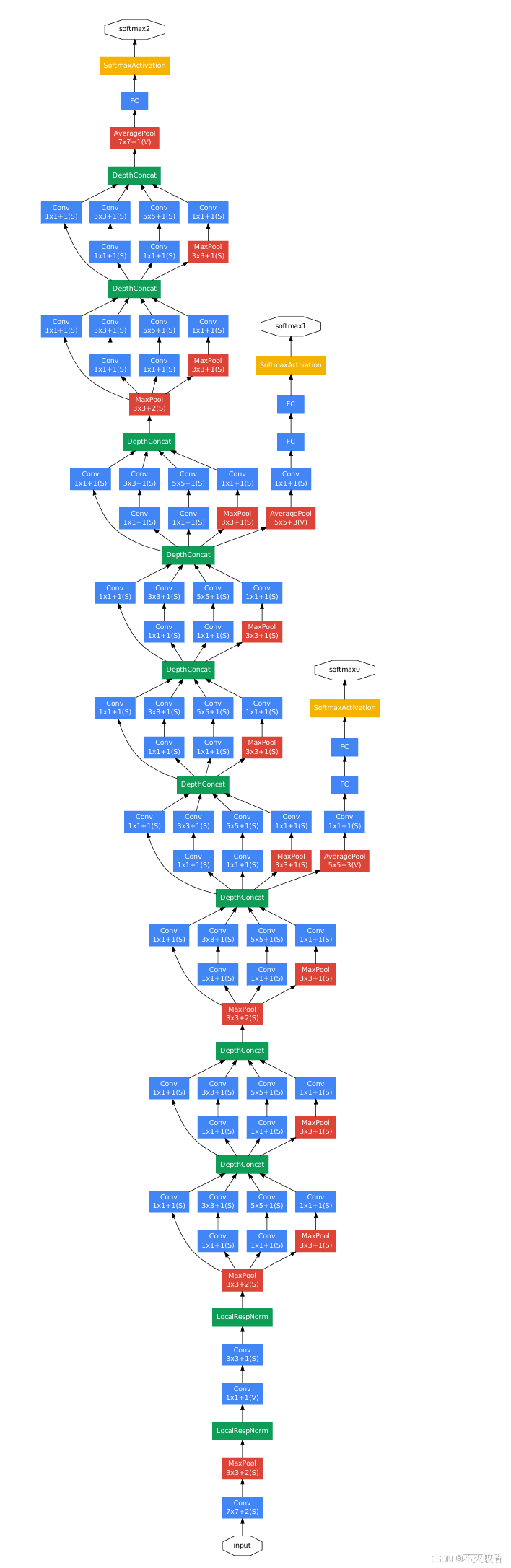
Inception 模块
Inception 模块是 GoogLeNet 的核心创新,它通过并行使用多个卷积层(大小不一的卷积核)和池化层来提取不同尺度的特征。每个模块包括以下几个部分:
- 1x1 卷积:用于降维,减少计算量。
- 3x3 和 5x5 卷积:用于提取不同尺度的特征。
- 3x3 最大池化:捕捉空间位置的局部信息。
- 所有这些操作的输出被连接在一起,作为该 Inception 模块的输出。
Inception 模块示意图:
这种设计使得每个 Inception 模块能够在多个尺度上提取特征,从而增强了模型的表现力。
GoogLeNet 的优缺点
优点:
-
较少的参数:
GoogLeNet 使用了 1x1 卷积和全局平均池化,有效减少了模型的参数量,避免了传统卷积网络中的冗余计算。 -
较高的性能:
在 ImageNet 和其他数据集上,GoogLeNet 显示了比很多其他网络(如 VGG 和 AlexNet)更好的性能。 -
深度与效率的平衡:
通过设计多层次的 Inception 模块,GoogLeNet 实现了更深的网络,而不会增加计算量和参数量。 -
易于扩展:
GoogLeNet 的设计可以非常容易地通过堆叠更多的 Inception 模块来扩展,使得模型能够更好地处理复杂的任务。
缺点:
-
网络结构较复杂:
尽管 Inception 模块非常高效,但它的设计相对复杂。实现和调试这样一个网络相对困难。 -
计算复杂性较高:
尽管参数较少,但由于使用多个不同大小的卷积核和池化层,GoogLeNet 仍然存在一定的计算复杂性,尤其是在推理阶段。 -
训练时间较长:
GoogLeNet 的训练时间相对较长,尤其是在较大数据集上的训练。
GoogLeNet 的应用场景
-
图像分类:
GoogLeNet 在大规模图像分类任务中表现优异,尤其是用于图像分类(如 ImageNet)。 -
目标检测和分割:
GoogLeNet 可以作为目标检测(如 Faster R-CNN)和图像分割任务(如 FCN)的基础网络。 -
迁移学习:
GoogLeNet 经过预训练后,通常用于迁移学习,应用于不同领域的计算机视觉任务,如医学图像分析。
实现代码示例
以下是使用 PyTorch 加载和使用 GoogLeNet 模型的代码示例:
import torch
import torch.nn as nn
class Conv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0):
super(Conv, self).__init__()
self.conv = nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding)
self.bn = nn.BatchNorm2d(out_channels)
self.silu = nn.SiLU()
def forward(self, x):
x = self.conv(x)
x = self.bn(x)
x = self.silu(x)
return x
class MaxPool(nn.Module):
def __init__(self, kernel_size, stride=1, padding=0):
super(MaxPool, self).__init__()
self.pool = nn.MaxPool2d(kernel_size, stride, padding)
def forward(self, x):
x = self.pool(x)
return x
class Dropout(nn.Module):
def __init__(self, p=0.4):
super(Dropout, self).__init__()
self.dropout = nn.Dropout(p)
def forward(self, x):
x = self.dropout(x)
return x
class Linear(nn.Module):
def __init__(self, in_features, out_features):
super(Linear, self).__init__()
self.linear = nn.Linear(in_features, out_features)
self.silu = nn.SiLU()
def forward(self, x):
x = self.linear(x)
x = self.silu(x)
return x
class Softmax(nn.Module):
def __init__(self, in_features, num_classes):
super(Softmax, self).__init__()
self.softmax = nn.Softmax(dim=1)
def forward(self, x):
x = self.softmax(x)
return x
class InceptionV1(nn.Module):
def __init__(self, in_channels, out1x1, red3x3, out3x3, red5x5, out5x5, pool_proj):
super(InceptionV1, self).__init__()
self.branch1 = Conv(in_channels, out1x1, 1)
self.branch2 = nn.Sequential(
Conv(in_channels, red3x3, 1),
Conv(red3x3, out3x3, 3, padding=1)
)
self.branch3 = nn.Sequential(
Conv(in_channels, red5x5, 1),
Conv(red5x5, out5x5 // 2, 3, padding=1),
Conv(out5x5 // 2, out5x5, 3, padding=1)
)
self.branch4 = MaxPool(3, stride=1, padding=1)
self.branch5 = AveragePool(3, stride=1, padding=1)
self.branch6 = Conv(in_channels * 2, pool_proj, kernel_size=1, stride=1)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
branch5 = self.branch5(x)
branch6 = torch.cat([branch4, branch5], dim=1)
branch6 = self.branch6(branch6)
outputs = torch.cat([branch1, branch2, branch3, branch6], dim=1)
return outputs
class LocalRespNorm(nn.Module):
def __init__(self, size=5, alpha=10, beta=0.75):
super(LocalRespNorm, self).__init__()
self.size = size
self.alpha = alpha
self.beta = beta
def forward(self, x):
x = nn.functional.local_response_norm(x, self.size, self.alpha, self.beta)
return x
class AveragePool(nn.Module):
def __init__(self, kernel_size=7, stride=1, padding=0):
super(AveragePool, self).__init__()
self.pool = nn.AvgPool2d(kernel_size, stride, padding)
def forward(self, x):
x = self.pool(x)
return x
class GoogLeNet(nn.Module):
def __init__(self, num_classes=1000, is_train=True):
super(GoogLeNet, self).__init__()
self.is_train = is_train
self.flat = nn.Flatten()
self.conv1 = Conv(3, 64, 7, stride=2, padding=3)
self.maxpool1 = MaxPool(3, stride=2, padding=1)
self.lrn1 = LocalRespNorm(size=5, alpha=10, beta=0.75)
self.conv2 = Conv(64, 64, 1)
self.conv3 = Conv(64, 192, 3, padding=1)
self.lrn2 = LocalRespNorm(size=5, alpha=10, beta=0.75)
self.maxpool2 = MaxPool(3, stride=2, padding=1)
self.inception3a = InceptionV1(192, 64, 96, 128, 16, 32, 32)
self.inception3b = InceptionV1(256, 128, 128, 192, 32, 96, 64)
self.maxpool3 = MaxPool(3, stride=2, padding=1)
self.inception4a = InceptionV1(480, 192, 96, 208, 16, 48, 64)
self.inception4b = InceptionV1(512, 160, 112, 224, 24, 64, 64)
self.avgpool1 = AveragePool(kernel_size=5, stride=3)
self.conv4 = Conv(512, 128, 1)
self.linear1 = Linear(2048, 1024)
self.linear2 = Linear(1024, num_classes)
self.softmax1 = Softmax(1024, num_classes)
self.inception4c = InceptionV1(512, 128, 128, 256, 24, 64, 64)
self.inception4d = InceptionV1(512, 112, 144, 288, 32, 64, 64)
self.avgpool2 = AveragePool(kernel_size=5, stride=3)
self.conv5 = Conv(528, 128, 1)
self.linear3 = Linear(2048, 1024)
self.linear4 = Linear(1024, num_classes)
self.softmax2 = Softmax(1024, num_classes)
self.inception4e = InceptionV1(528, 256, 160, 320, 32, 128, 128)
self.maxpool4 = MaxPool(3, stride=2, padding=1)
self.inception5a = InceptionV1(832, 256, 160, 320, 32, 128, 128)
self.inception5b = InceptionV1(832, 384, 192, 384, 48, 128, 128)
self.avgpool = AveragePool(kernel_size=7, stride=1)
self.dropout = Dropout(0.4)
self.linear = Linear(1024, num_classes)
self.softmax = Softmax(1024, num_classes)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.lrn1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.lrn2(x)
x = self.maxpool2(x)
x = self.inception3a(x)
x = self.inception3b(x)
x = self.maxpool3(x)
x = self.inception4a(x)
x = self.inception4b(x)
if self.is_train:
y0 = self.avgpool1(x)
y0 = self.conv4(y0)
y0 = self.flat(y0)
y0 = self.linear1(y0)
y0 = self.linear2(y0)
y0 = self.softmax1(y0)
x = self.inception4c(x)
x = self.inception4d(x)
if self.is_train:
y1 = self.avgpool2(x)
y1 = self.conv5(y1)
y1 = self.flat(y1)
y1 = self.linear3(y1)
y1 = self.linear4(y1)
y1 = self.softmax2(y1)
x = self.inception4e(x)
x = self.maxpool4(x)
x = self.inception5a(x)
x = self.inception5b(x)
x = self.avgpool(x)
x = self.dropout(x)
x = self.flat(x)
x = self.linear(x)
x = self.softmax(x)
if self.is_train:
return x, y0, y1
else:
return x
GoogLeNet 在计算机视觉领域中的影响深远,它的 Inception 模块为后来的许多网络架构(如 Inception-v3 和 DenseNet)提供了灵感。


















 1061
1061

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









