




一、项目介绍
本项目主要是模仿 muduo 库实现一个以主从 Reactor 为模型,以 OneThreadOneEventLoop 为事件驱动的高并发服务器组件。通过这个服务器组件,我们可以简洁快速的搭建出一个高性能的 TCP 服务器。并且组件内部会提供不同的应用层协议支持,组件使用者可以通过这些协议快速的完成一个应用服务器的搭建。
muduo 源码 – https://github.com/chenshuo/muduo/tree/master/muduo
muduo 介绍 – https://www.cyhone.com/articles/analysis-of-muduo/
二、HTTP服务器
1.概念
HTTP(Hyper Text Transfer Protocol),超文本传输协议是应用层协议,是一种简单的请求-响应协议(客户端根据自己的需要向服务器发送请求,服务器针对请求提供服务,完毕后通信结束)。但是需要注意的是HTTP协议是一个运行在TCP协议之上的应用层协议,这一点本质上是告诉我们,HTTP服务器其实就是个TCP服务器,只不过在应用层基于HTTP协议格式进行数据的组织和解析来明确客户端的请求并完成业务处理。
因此实现HTTP服务器简单理解,只需要以下几步即可
1.搭建一个TCP服务器,接收客户端请求。
2.以HTTP协议格式进行解析请求数据,明确客户端目的。
3.明确客户端请求目的后提供对应服务。
4.将服务结果⼀HTTP协议格式进行组织,发送给客户端
实现一个HTTP服务器很简单,但是实现一个高性能的服务器并不简单,这个单元中将讲解基于Reactor模式的高性能服务器实现。当然准确来说,因为我们要实现的服务器本身并不存在业务,咱们要实现的应该算是一个高性能服务器基础库,是一个基础组件。
2.Reactor模型
Reactor 模式,是指通过一个或多个输入同时传递给服务器进行请求处理时的事件驱动处理模式。服务端程序处理传入多路请求,并将它们同步分派给请求对应的处理线程,Reactor 模式也叫Dispatcher 模式。简单理解就是使用 I/O多路复用统一监听事件,收到事件后分发给处理进程或线程,是编写高性能网络服务器的必备技术之一。
2.1单Reactor单线程:单I/O多路复用+业务处理
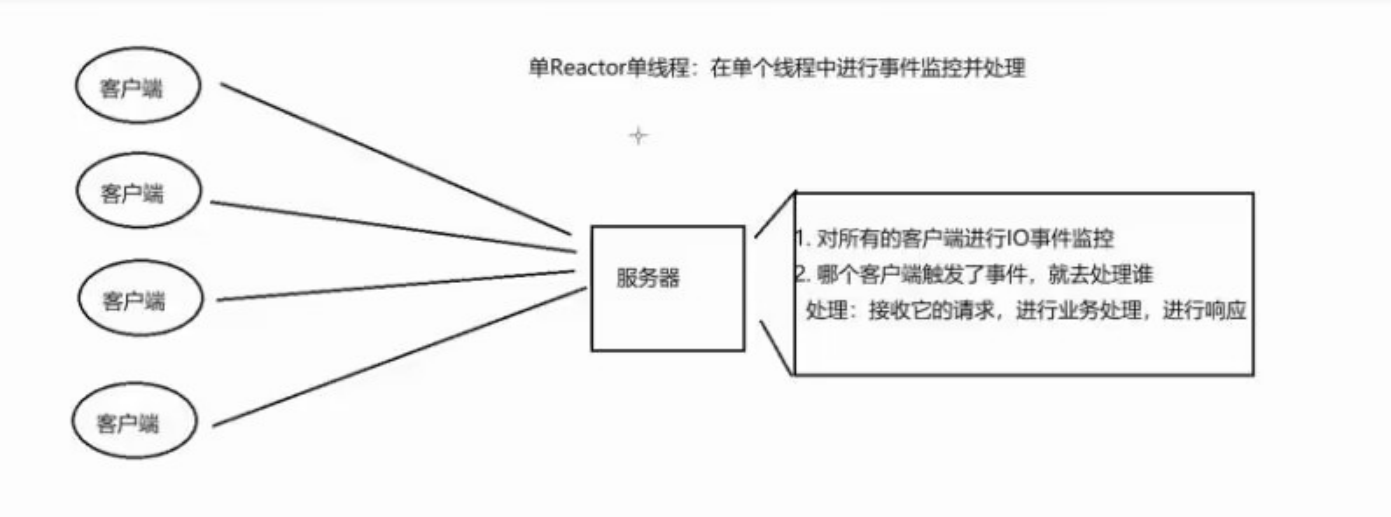
单Reactor单线程:在单个线程中进行事件监控并处理
服务端处理思想:事件驱动触发模式
谁发送了数据,谁触发了事件就处理谁
技术支撑点:I/O多路转接技术
1.通过IO多路复用模型对所有的客户端进行IO事件监控
2.触发事件后,进行事件处理。哪个客户端触发了事件,就去处理谁:接收它的请求,进行业务处理,进行响应
a. 如果是新建连接请求,则获取新建连接,并添加至多路复用模型进行事件监控。
b. 如果是数据通信请求,则进行对应数据处理(接收数据,处理数据,发送响应)。
优点:所有操作均在同一线程中完成,思想流程较为简单,不涉及进程/线程间通信及资源争抢问题。因为是单线程操作,操作都是串行化的,思想较为简单,编码流程也较为简单〈不用考虑进程或者线程间的通信,以及安全问题)
缺点:因为所有的事件监控以及业务处理都是在一个线程中完成的,无法有效利用CPU多核资源,因此很容易造成性能瓶颈
适用场景:适用于客户端数量较少,且处理速度较为快速的场景。(处理较慢或活跃连接较多,会导致串行处理的情况下,后处理的连接长时间无法得到响应)
2.2单Reactor多线程:单I/O多路复用+线程池(业务处理)
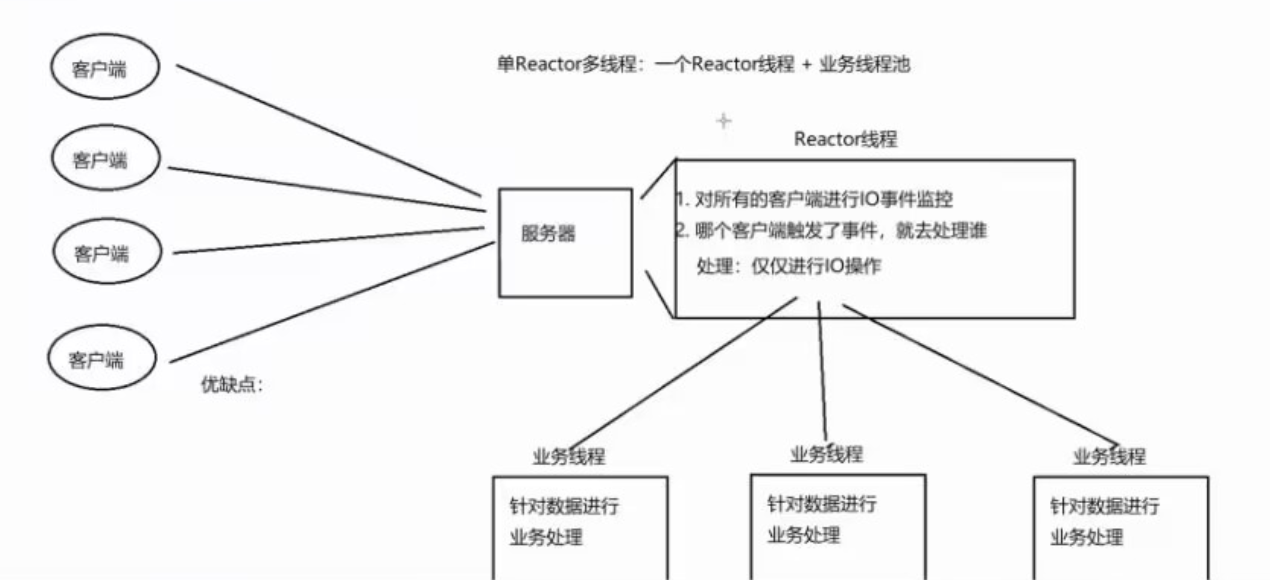
1.Reactor线程通过I/O多路复用模型进行客户端请求监控
2.触发事件后,进行事件处理
对所有的客户端进行IO事件监控,哪个客户端触发了事件,就去处理谁 处理:仅仅进行IO操作
a. 如果是新建连接请求,则获取新建连接,并添加至多路复用模型进行事件监控。
b. 如果是数据通信请求,则接收数据后分发给Worker线程池进行业务处理。
c. 工作线程处理完毕后,将响应交给Reactor线程进行数据响应
优点:充分利用了CPU多核资源,处理效率可以更高,降低了代码的耦合度
缺点:多线程间的数据共享访问控制较为复杂,单个Reactor 承担所有事件的监听和响应,在单线程中运行,高并发场景下容易成为性能瓶颈。在单个Reactor线程中,包含了对所有客户端的事件监控,以及所有客户端的IO操作,不利于高并发场景(每一个时刻都有很多客户端连接),来不及进行新的客户端连接处理
2.3多Reactor多线程:多I/O多路复用+线程池(业务处理)
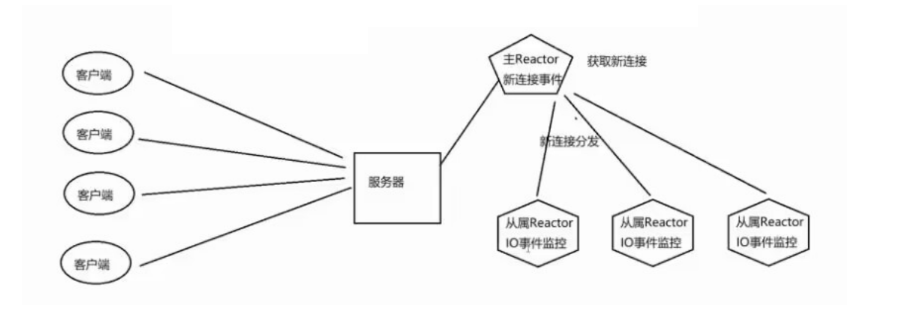
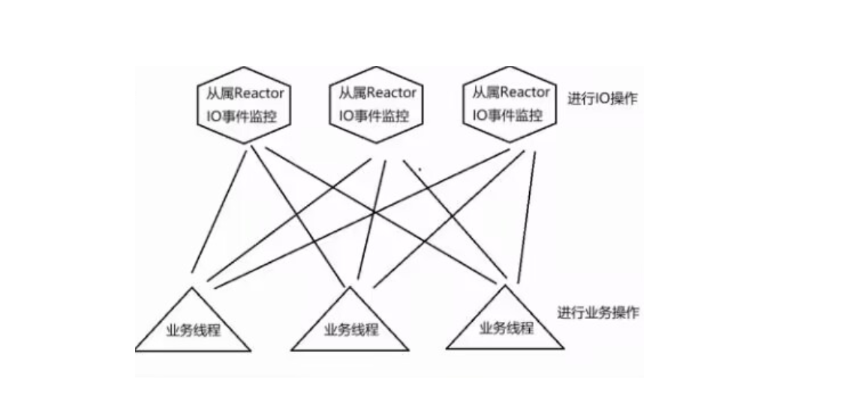
1.在主Reactor中处理新连接请求事件,有新连接到来则分发到子Reactor中监控
2.在子Reactor中进行客户端通信监控,有事件触发,则接收数据分发给Worker线程池
4.Worker线程池分配独立的线程进行具体的业务处理
a. 工作线程处理完毕后,将响应交给子Reactor线程进行数据响应
多Reactor多线程模式:基于单reactor多线程的缺点考虑,如果IO的时候,有连接到来无法处理,因此将连接处理单独拎出来。因此让一个Reactor线程仅仅进行新连接的处理,让其他的Reactor线程进行IO处理,IO Reactor线程拿到数据分发给业务线程池进行业务处理。因此多Reactor多线程模式,也叫做主从Reactor模型。
主Reactor线程:进行新连接事件监控。
**从属Reactor线程:进行lO事件监控 **
业务线程池:进行业务处理
优点:充分利用了CPU多核资源,并且可以进行合理分配,主从Reactor各司其职
但是大家也要理解:执行流并不是越多越好,因为执行流多了,反而会增加CPU切换调度的成本
目标定位:One Thread One Loop主从Reactor模型高并发服务器
咱们要实现的是主从Reactor模型服务器,也就是主Reactor线程仅仅监控监听描述符,获取新建连接,保证获取新连接的高效性,提高服务器的并发性能。主Reactor获取到新连接后分发给子Reactor进行通信事件监控。而子Reactor线程监控各自的描述符的读写事件进行数据读写以及业务处理。即子Reactor完成IO事件监控,IO操作,以及业务处理。One Thread One Loop的思想就是把所有的操作都放到一个线程中进行,一个线程对应一个事件处理的循环。当前实现中,因为并不确定组件使用者的使用意向,因此并不提供业务层工作线程池的实现,只实现主从Reactor,而Worker工作线程池,可由组件库的使用者的需要自行决定是否使用和实现
三、前置知识技术点功能用例
1.C++11中的bind
bind (Fn&& fn, Args&&... args);
官方文档对于bind接口的概述解释:Bind function arguments
我们可以将bind接口看作是一个通用的函数适配器,它接受一个函数对象,以及函数的各项参数,然后返回一个新的函数对象,但是这个函数对象的参数已经被绑定为设置的参数。运行的时候相当于总是调用传入固定参数的原函数。
但是如果进行绑定的时候,给与的参数为 std::placeholders::_1, _2... 则相当于为新适配生成的函数对象的调用预留一个参数进行传递。
基于bind的作用,当我们在设计一些线程池,或者任务池的时候,就可以将将任务池中的任务设置为函数类型,函数的参数由添加任务者直接使用bind进行适配绑定设置,而任务池中的任务被处理,只需要取出一个个的函数进行执行即可。
这样做有个好处就是,这种任务池在设计的时候,不用考虑都有哪些任务处理方式了,处理函数该如何设计,有多少个什么样的参数,这些都不用考虑了,降低了代码之间的耦合度。
#include <iostream>
#include <string>
#include <vector>
#include <functional>
void print(const std::string &str, const int num)
{
std::cout << str << " " << num << std::endl;
}
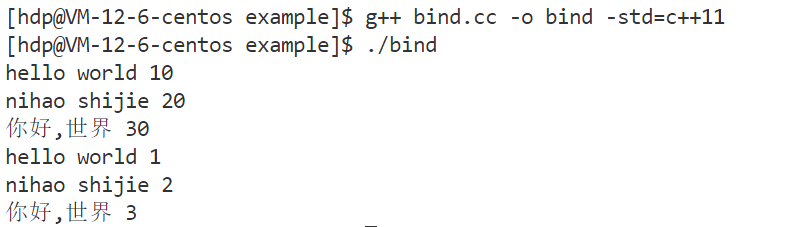
int main()
{
print("hello world", 10);
auto func1 = std::bind(print, "nihao shijie", 20);
func1();
auto func2 = std::bind(print, "你好,世界", std::placeholders::_1);
func2(30);
typedef std::function<void()> Task;
std::vector<Task> array;
array.push_back(std::bind(print, "hello world", 1));
array.push_back(std::bind(print, "nihao shijie", 2));
array.push_back(std::bind(print, "你好,世界", 3));
for (auto &func : array)
{
func();
}
return 0;
}
2.简单的秒级定时任务实现
在当前的高并发服务器中,我们不得不考虑一个问题,那就是连接的超时关闭问题。我们需要避免一个连接长时间不通信,但是也不关闭,空耗资源的情况。这时候我们就需要一个定时任务,定时的将超时过期的连接进行释放。
Linux提供给我们的定时器:
#include <sys/timerfd.h>
int timerfd_create(int clockid, int flags);
clockid:
CLOCK_REALTIME--以系统时间作为计时基准值(如果系统时间发生了改变就会出问题)
CLOCK_MONOTONIC--以系统启动时间进行递增的一个基准值(定时器不会随着系统时间改变而改变)
flags:0-阻塞操作
返回值:文件描述符
int timerfd_settime(int fd, int flags, struct itimerspec *new, struct itimerspec *old);
功能:启动定时器
fd: timerfd_create函数的返回值。文件描述符--创建的定时器的标识符
flags: 0-相对时间, 1-绝对时间;默认设置为0即可.
new: 用于设置定时器的新超时时间
old: 用于接收原来的超时时间
struct timespec {
time_t tv_sec; /* Seconds */
long tv_nsec; /* Nanoseconds */
};
struct itimerspec {
struct timespec it_interval; /* 第一次之后的超时间隔时间 */
struct timespec it_value; /* 第一次超时时间 */
};
Linux下一切皆文件,定时器的操作也是跟文件操作并没有什么区别,而定时器定时的原理每隔一段时间(定时器的超时时间),定时器会在每次超时时,系统就会给这个描述符对应的定时器写入一个8字节数据,表示在上一次读取数据到当前读取数据期间超时了多少次。
创建了一个定时器,定时器定设置的超时时间是3s,也就是说每3s计算一次超时
从启动开始,每隔3s中,系统都会给描述如写入一个1,表示从上一次读取数据到现在超时了1次
假设30s之后才读取数据,则这时候就会读取到一个10,表示上一次读取数据到限制超时了10次
使用案例:
#include <iostream>
#include <string>
#include <sys/timerfd.h>
#include <unistd.h>
#include <cstdint>
int main()
{
int timerfd = timerfd_create(CLOCK_MONOTONIC, 0);
if (timerfd < 0)
{
std::cerr << "timerfd create failed" << std::endl;
exit(1);
}
struct itimerspec ims;
// 第一次超时时间为1s后
ims.it_value.tv_sec = 3;
ims.it_value.tv_nsec = 0;
// 第一次超时后,每次超时的间隔时
ims.it_interval.tv_sec = 3;
ims.it_interval.tv_nsec = 0;
int n = timerfd_settime(timerfd, 0, &ims, nullptr);
if (n < 0)
{
std::cerr << "timefd settime failed" << std::endl;
exit(2);
}
for (;;)
{
uint64_t data;
ssize_t n = read(timerfd, &data, 8);
if (n > 0)
{
std::cout << "超时了,距离上一次超时: " << data << std::endl;
}
}
close(timerfd);
return 0;
}
上边例子,是一个定时器的使用示例,是每隔3s钟触发一次定时器超时,否则就会阻塞在read读取数据这里。
基于这个例子,则我们可以实现每隔3s,检测一下哪些连接超时了,然后将超时的连接释放掉。
时间轮思想:
上述的例子,存在一个很大的问题,每次超时都要将所有的连接遍历一遍,如果有上万个连接,效率无疑是较为低下的。这时候大家就会想到,我们可以针对所有的连接,根据每个连接最近一次通信的系统时间建立一个小根堆,这样只需要每次针对堆顶部分的连接逐个释放,直到没有超时的连接为止,这样也可以大大提高处理的效率。
上述方法可以实现定时任务,但是这里给大家介绍另一种方案:时间轮
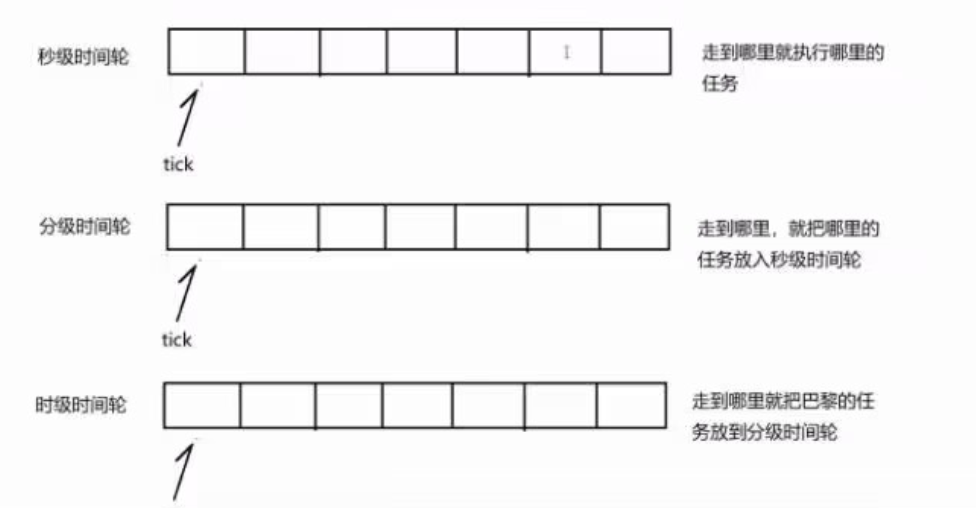
时间轮的思想来源于钟表,如果我们定了一个3点钟的闹铃,则当时针走到3的时候,就代表时间到了。
同样的道理,如果我们定义了一个数组,并且有一个指针,指向数组起始位置,这个指针每秒钟向后走动一步,走到哪里,则代表哪里的任务该被执行了,那么如果我们想要定一个3s后的任务,则只需要将任务添加到tick+3的位置,则每秒钟走一步,三秒钟后tick走到对应位置,这时候执行对应位置的任务即可。
但是,同一时间可能会有大批量的定时任务,因此我们可以给数组对应位置下拉一个数组,这样就可以在同一个时刻上添加多个定时任务了。
当然,上述操作也有一些缺陷,比如我们如果要定义一个60s后的任务,则需要将数组的元素个数设置为60才可以,如果设置一小时后的定时任务,则需要定义3600个元素的数组,这样无疑是比较麻烦的。
因此,可以采用多层级的时间轮,有秒针轮,分针轮,时针轮, 60<time<3600则time/60就是分针轮对应存储的位置,当tick/3600等于对应位置的时候,将其位置的任务指向秒针,秒针轮进行移动。因为当前我们的应用中,倒是不用设计的这么麻烦,因为我们的定时任务通常设置的30s以内,所以简单的单层时间轮就够用了。
但是,我们也得考虑一个问题,当前的设计是时间到了,则主动去执行定时任务,释放连接,那能不能在时间到了后,自动执行定时任务呢,这时候我们就想到一个操作–类的析构函数。
一个类的析构函数,在对象被释放时会自动被执行,那么我们如果将一个定时任务作为一个类的析构函数内的操作,则这个定时任务在对象被释放的时候就会执行。
但是仅仅为了这个目的,而设计一个额外的任务类,好像有些不划算,但是,这里我们又要考虑另一个问题,那就是假如有一个连接建立成功了,我们给这个连接设置了一个30s后的定时销毁任务,但是在第10s的时候,这个连接进行了一次通信,那么我们应该是在第30s的时候关闭,还是第40s的时候关闭呢?无疑应该是第40s的时候。也就是说,这时候,我们需要让这个第30s的任务失效,但是我们该如何实现这个操作呢?
这里,我们就用到了智能指针shared_ptr,shared_ptr有个计数器,当计数为0的时候,才会真正释放一个对象,那么如果连接在第10s进行了一次通信,则我们继续向定时任务中,添加一个30s后(也就是第40s)的任务类对象的shared_ptr,则这时候两个任务shared_ptr计数为2,则第30s的定时任务被释放的时候,计数-1,变为1,并不为0,则并不会执行实际的析构函数,那么就相当于这个第30s的任务失效了,只有在第40s的时候,这个任务才会被真正释放。
上述过程就是时间轮定时任务的思想了,当然这里为了更加简便的实现,进行了一些小小的调整实现。
总结:
1.同一时刻的定时任务只能添加一个,需要考虑如何在同一时刻支持添加多个定时任务
解决方案: 将时间轮的一维数组设计为二维数组(时间轮一位数组的每一个节点也是一个数组)
2.假设当前的定时任务是一个连接的非活跃销毁任务,这个任务什么时候添加到时间轮中比较合适
一个连接30s内都没有通信,则是一个非活跃连接,这时候就销毁。但是一个连接如果在建立的时候添加了一个30s后销毁的任务,但是这个连接30s内人家有数据通信,在第30s的时候不是一个非活跃连接。
思想:需要在一个连接有IO事件产生的时候,延迟定时任务的执行
作为一个时间轮定时器,本身并不关注任务类型,只要是时间到了就需要被执行。
解决方案:类的析构函数+智能指针shared_ptr,通过这两个技术可以实现定时任务的延时
1.使用一个类,对定时任务进行封装,类实例化的每一个对象,就是一个定时任务对象,当对象被销毁的时候,再去执行定时任务(将定时任务的执行,放到析构函数中)
2.shared ptr用于对new的对象进行空间管理,当shared_ptr对一个对象进行管理的时候,内部有一个计数器,计数器为0的时候,则释放所管理的对象
int *a = new int;
std:shared ptr<int> pi(a); --- a对象只有在pi计数为0的时候,才会被释放
std:shared ptr<int> pi1(pi) --当针对pi又构建了一个shared_ptr对象,则pi和pi1计数器为2
当pi和pi1中任意一个被释放的时候,只是计数器-1,因此他们管理的a对象并没有被释放,只有当pi和pi1都被释放了,计数器为0了,这时候才会释放管理的a对象
基于这个思想,我们可以使用shared_ptr来管理定时器任务对象
但是std::shared_ptr pi2(a);但是如果pi2是针对的原始对象构造的。并不会跟pi和pi1,共享计数
使用案例:
#include <iostream>
#include <vector>
#include <memory>
#include <functional>
#include <unordered_map>
#include <unistd.h>
// 定时器任务的回调函数,即超时时执行的任务
using TaskFunc = std::function<void()>;
// 定时器对象销毁的回调函数
using ReleaseFunc = std::function<void()>;
// 定时器任务
class TimerTask
{
private:
uint64_t _id; // 定时器任务对象id
uint32_t _timeout; // 定时任务的超时时间
bool _canceled; // false表示没有被取消,true表示被取消了
TaskFunc _task_cb; // 定时器对象要执行的定时任务
ReleaseFunc _release; // 用于删除TimerWheel中保存的定时器对象信息
public:
TimerTask(const uint64_t &id, const uint32_t &delay, const TaskFunc &cb)
: _id(id), _timeout(delay), _task_cb(cb), _canceled(false) {
}
~TimerTask()
{
if (_canceled == false)
_task_cb();
_release();
}
void Canceled() {
_canceled = true; }
uint32_t DelayTime() {
return _timeout; }
void SetRelease(const ReleaseFunc &cb) {
_release = cb; }
};
// 管理定时器任务的shared_ptr
using PtrTask = std::shared_ptr<TimerTask>;
// 管理定时器任务的weak_ptr
using WeakTask = std::weak_ptr<TimerTask>;
// 时间轮
class TimerWheel
{
private:
std::vector<std::vector<PtrTask>> _wheel;
int _tick; // 当前的秒针,走到哪里释放哪里,就相当于执行哪里的任务
int _capacity; // 表盘的最大数量,即最大延迟时间
std::unordered_map<uint64_t, WeakTask> _timers;
private:
void RemoveTimer(const uint64_t &id)
{
auto it = _timers.find(id);
if (it != _timers.end())
{
_timers.erase(it);
}
}
public:
TimerWheel() : _tick(0), _capacity(60), _wheel(_capacity) {
}
// 添加定时任务
void TimerAdd(const uint64_t &id, const uint32_t &delay, const TaskFunc &cb)
{
PtrTask ptr(new TimerTask(id, delay, cb));
ptr->SetRelease(std::bind(&TimerWheel::RemoveTimer, this, id));
int pos = (_tick + delay) % _capacity;
// 将shared_ptr管理的对象加入到时间轮中
_wheel[pos].push_back(ptr);
// 将shared_ptr管理的对象的weak_ptr加入到哈希表中
_timers[id] = WeakTask(ptr);
}
// 刷新/延迟定时时间
void TimerRefresh(const uint64_t &id)
{
// 通过保存的定时器的weak_ptr构造一个shared_ptr出来,添加到轮子中
auto it = _timers.find(id);
if (it == _timers.end())
{
return;
}
// lock获取weak_ptr管理的对象对应的shared_ptr
PtrTask ptr = it->second.lock();
int delay = ptr->DelayTime();
int pos = (_tick + delay) % _capacity;
_wheel[pos].push_back(ptr);
}
// 取消定时任务
void TimerCancel(const uint64_t &id)
{
auto it = _timers.find(id);
// 没有找到定时任务就没法刷新和延迟,直接退出
if (it == _timers.end())
return;
PtrTask ptr = it->second.lock();
if (ptr)
ptr->Canceled();
}
// 这个函数应该每秒钟被执行一次,相当于秒针向后走了一步
void RunTimerTask()
{
_tick = (_tick + 1) % _capacity;
// 清空指定位置的数组,就会把数组中保存的所有管理定时器对象的shared_ptr释放掉
_wheel[_tick].clear();
}
};
class Test
{
public:
Test() {
std::cout << "Test 构造" << std::endl; }
~Test() {
std::cout << "Test 析构" << std::endl; }
};
void Release(const Test *t)
{
delete t;
}
int main()
{
TimerWheel tw;
Test *t = new Test();
tw.TimerAdd(100, 5, std::bind(Release, t));
for (int i = 0; i < 5; i++)
{
sleep(1);
// 刷新定时任务
tw.TimerRefresh(100);
// 向后移动指针
tw.RunTimerTask();
std::cout << "刷新了定时任务,需要在5秒钟之后进行销毁" << std::endl;
}
for (;;)
{
sleep(1);
std::cout << "------------------" << std::endl;
tw.RunTimerTask(); // 向后移动秒针
}
return 0;
}
3.正则库的简单使用
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。
正则表达式的使用,可以使得HTTP请求的解析更加简单(这里指的时程序员的工作变得的简单,这并不代表处理效率会变高,实际上效率上是低于直接的字符串处理的),使我们实现的HTTP组件库使用起来更加灵活。
我们可以在这里学习相关的语法:正则表达式教程–菜鸟教程
bool std:regex_match (const stdrstring &src, std:smatch &matches, std:regex &e)
src:原始字符串
matches: 正则表达式可以从原始字符串中匹配并提取符合某种规则的数据,提取的数据就放在matches中,是一个类似于数组的容器
e: 正则表达式的匹配规则
返回值:用于确定匹配是否成功
正则表达式的简单案例:
void regex_test()
{
std::string str = "/numbers/1234";
// 匹配以 /numbers/ 为起始位置,后面跟一个或多个数字字符的字符串
// 并且在匹配的过程中提取这个匹配到的数字字符串
std::regex e("/numbers/(\\d+)");
std::smatch matches;
bool ret = std::regex_match(str, matches, e);
if (ret == false)
{
std::cout << "regex_match failed" << std::endl;
}
for (auto &str : matches)
{
std::cout << str << std::endl;
}
}
// 输出结果
/numbers/1234
1234
HTTP请求行的匹配
int main()
{
// HTTP请求行格式: GET /www.baidu.com/login?user=xiaoming&pass=123123 HTTP/1.1\r\n
std::string request = "GET /www.baidu.com/login?user=xiaoming&pass=123123 HTTP/1.1\r\n";
std::smatch matches;
// 请求方法的匹配 GET HEAD POST PUT DELETE
// GET|HEAD|POST|PUT|DELETE 表示匹配并提取其中的任意一个字符串
// [^?*] 表示匹配非问号字符 后边的*表示0次或多次
// \\?(.*) \\? 表示原始的 ? 到字符,(.*)表示提取问哈之后的任意字符0次或多次,直到遇空格
// HTTP/1\\.[01] 表示匹配以 HTTP/1.开始,后边有个0或1的字符串
std::regex e("(GET|HEAD|POST|PUT|DELETE) ([^?]*)(?:\\?(.*))? (HTTP/1\\.[01])(?:\n|\r\n)?");
// (?:\n|\r\n)? (?:...)表示匹配某个格式的字符串,但是不提取
// 最后的?表示的是匹配前面的表达式0次或者1次
bool ret = std::regex_match(request, matches, e);
if (ret == false)
{
std::cout << "regex_match failed" << std::endl;
}
for (auto &str : matches)
{
std::cout << str << std::endl;
}
return 0;
}
4.通用类型any类型的实现
在本项目中,我们要实现一个高并发的服务器组件,能够的接收并处理客户端发送过来的请求,就必然涉及到与客户端的通信,而通信就必然涉及到对套接字的操作;同时,由于 TCP 是面向字节流的,因此服务器在接收客户端数据的时候就可能出现 socket 中的数据不足一条完整请求的情况,此时我们请求处理到一半时就需要停下来等待 socket 中下一次的数据到来。
因此我们需要为客户端连接设置一个请求处理的上下文,用来保存请求接收、解析以及处理的状态,它决定着对于下一次从缓冲区中取出的数据如何进行处理、从哪里开始处理等。同时,对于一条完整的请求,我们还需要对其进行解析,得到各种关键的要素,比如 HTTP 请求中的请求方法、请求URL、HTTP版本等,这些信息都会被保存在请求处理上下文中。
那么我们应该如何保存请求接收、解析以及处理的各种状态信息呢,定义一个 HTTP 请求信息的结构用于填充吗?如果我们的服务器组件仅支持 HTTP 协议这样做是可以的,但我们设计的服务器的目标是要能够支持各种不同的应用层协议,便于我们组件的使用者能够根据自己不同的业务场景定制对应的应用层协议进行使用,因此我们就需要让这个结构能够保存不同类型的数据,此时就需要 any 出场了。
每一个Connection对连接进行管理,最终都不可避免需要涉及到应用层协议的处理,因此在Connection中需要设置协议处理的上下文来控制处理节奏。但是应用层协议千千万,为了降低耦合度,这个协议接收解析上下文就不能有明显的协议倾向,它可以是任意协议的上下文信息,因此就需要一个通用的类型来保存各种不同的数据结构。
在C语言中,通用类型可以使用void*来管理,但是在C++中,boost库和C++17给我们提供了一个通用类型any来灵活使用,如果考虑增加代码的移植性,尽量减少第三方库的依赖,则可以使用C++17特性中的any,或者自己来实现。而这个any通用类型类的实现其实并不复杂,以下是简单的部分实现。
#include <iostream>
#include <typeinfo>
#include <cassert>
#include <unistd.h>
#include <any>
class holder
{
public:
virtual ~holder() {
}
virtual const std::type_info &type() = 0;
virtual holder *clone() = 0;
};
template <class T>
class placeholder : public holder
{
public:
placeholder(const T &val) : _val(val) {
}
// 获取子类对象保存的数据类型
virtual const std::type_info &type() {
return typeid(T); }
// 针对当前的对象自身,克隆出一个新的子类对象
virtual holder *clone() {
return new placeholder<T>(_val); }
virtual ~placeholder() {
}
public:
T _val;
};
class Any
{
private:
holder *_content;
public:
Any() : _content(nullptr) {
}
template <class T>
Any(const T &val) : _content(new placeholder<T>(val)) {
}
Any(const Any &other) : _content(other._content ? other._content->clone() : nullptr) {
}
~Any()
{
if (_content)
delete _content;
}
Any &swap(Any &other)
{
std::swap(_content, other._content);
return *this;
}
// 返回子类对象保存数据的指针
template <class T>
T *get()
{
// 想要获取数据的类型,必须和保存的数据,类型一致
assert(typeid(T) == _content->type());
if (_content == nullptr)
return nullptr;
return &((placeholder<T> *)_content)->_val;
}
// 赋值运算符的重载函数
template <class T>
Any &operator=(const T &val)
{
// 为val构造一个临时的通用容器,然后与当前容器自身进行指针交换,临时对象释放的时候
// 原先保存的数据也就释放
Any(val).swap(*this);
return *this;
}
Any &operator=(const Any &other)
{
Any(other).swap(*this);
return *this;
}
};
class Test
{
public:
Test() {
std::cout << "Test() 构造" << std::endl; }
Test(const Test &t) {
std::cout << "Test(const Test& t) 拷贝构造" << std::endl; }
~Test() {
std::cout << "~Test() 析构" << std::endl; }
};
int main()
{
std::any a;
a = 10;
int *pi = std::any_cast<int>(&a);
std::cout << *pi << std::endl;
a = std::string("hello");
std::string *ps = std::any_cast<std::string>(&a);
std::cout << *ps << std::endl;
// Any a;
// a = 10;
// int *pi = a.get<int>();
// std::cout << *pi << std::endl;
// a = std::string("hello world");
// std::string *ps = a.get<std::string>();
// std::cout << *ps << std::endl;
// {
// Test t;
// a = t;
// }
return 0;
}
下面是C++17中any的使用用例:
int main()
{
std::any a;
a = 10;
int *pi = std::any_cast<int>(&a);
std::cout << *pi << std::endl;
a = std::string("hello");
std::string *ps = std::any_cast<std::string>(&a);
std::cout << *ps << std::endl;
}
需要注意的是,C++17的特性需要高版本的g++编译器支持,建议g++ 7.3及以上版本。
sudo yum install centos-release-scl-rh centos-release-scl
sudo yum install devtoolset-7-gcc devtoolset-7-gcc-c++
source /opt/rh/devtoolset-7/enable
echo "source /opt/rh/devtoolset-7/enable" >> ~/.bashrc
// 查看g++版本
g++ -v
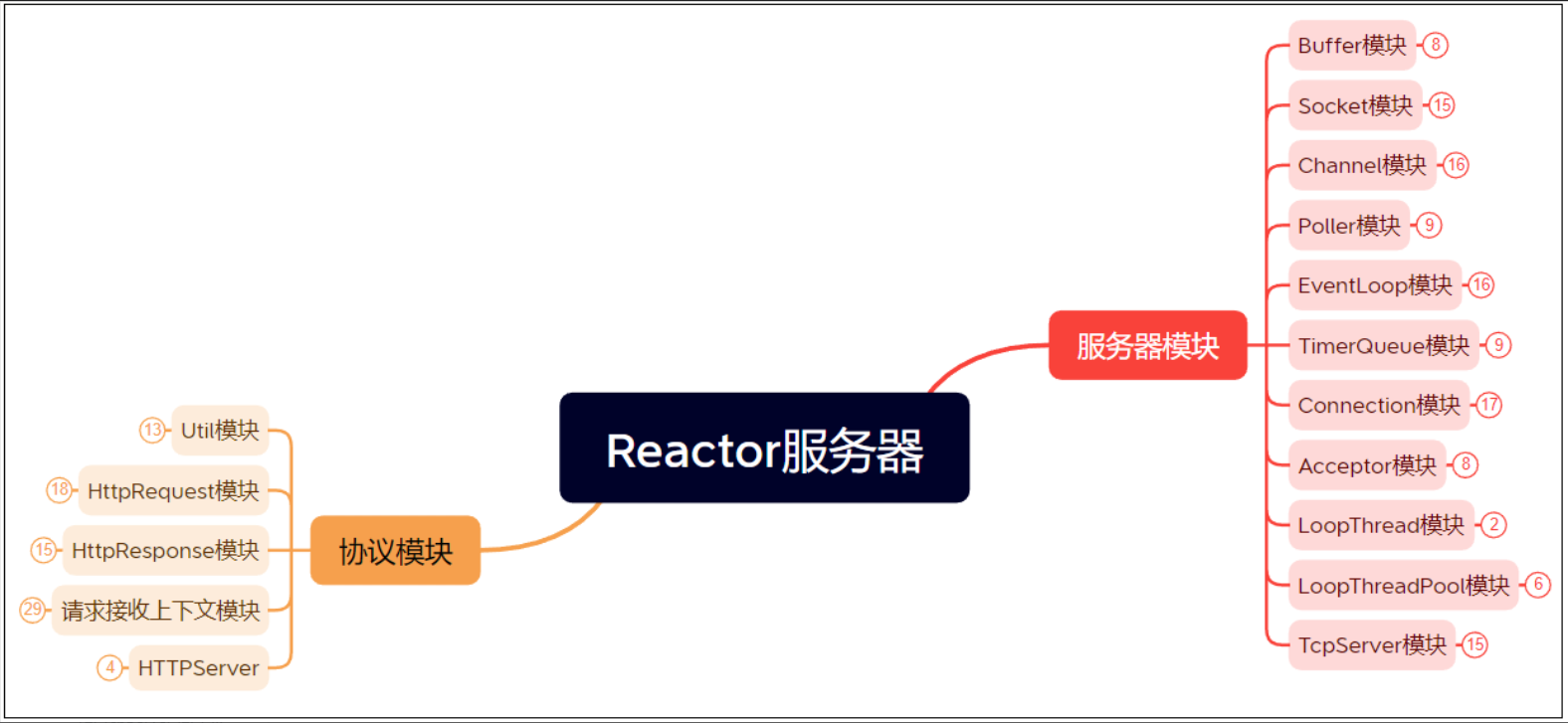
四、功能模块划分
基于以上的理解,我们要实现的是一个带有协议支持的Reactor模型高性能服务器,因此将整个项目的实现划分为两个大的模块:
SERVER模块:实现Reactor模型的TCP服务器
协议模块:对当前的Reactor模型服务器提供应用层协议支持
1.SERVER模块
SERVER模块就是对所有的连接以及线程进行管理,让它们各司其职,在合适的时候做合适的事,最终完成高性能服务器组件的实现。而具体的管理也分为三个方面:
监听连接管理:对监听连接进行管理。
通信连接管理:对通信连接进行管理。
超时连接管理:对超时连接进行管理。
基于以上的管理思想,将这个模块进行细致的划分又可以划分为以下多个子模块:
Buffer 模块:实现通信套接字的用户态缓冲区,防止接收到的数据不是一条完整的数据,同时确保客户端响应的数据在套接字可写的情况下进行发送。
Socket 模块:对 socket 套接字的操作进行封装,使得程序中对于套接字的各项操作更加简便。
Channel 模块:对于一个描述符进行监控事件管理,便于在用户态对描述符的监控事件进行维护。
Connection 模块:对通信连接进行整体管理,一个连接的所有操作都通过此模块来完成,增加连接操作的灵活以及便捷性。
Acceptor 模块:对监听套接字进行管理,为客户端的新建连接创建 Connection 对象,并设置各种回调。
TimerQueue 模块:定时任务模块,让一个任务可以在指定的时间之后被执行。
Poller模块:对任意的描述符进行IO事件监控,本质上就是对 epoll 的各种操作进行封装,从而让对描述符进行事件监控的操作更加简单,此模块是 Channel 模块的一个子模块。
EventLoop 模块:对事件监控进行管理,为了确保线程安全,此模块一个模块对应一个线程,服务器中的所有的事件都是由此模块来完成。
LoopThread 模块:将 EventLoop 与 thread 整合到一起,向外部返回所实例化的 EventLoop 对象,即将 EventLoop 对象与线程一一绑定。
LoopThreadPool 模块:LoopThread 线程池,用于对所有的 LoopThread 进行管理及分配。
TcpServer 模块:对前边所有子模块进行整合,从而提供给组件使用者的可以便捷的完成一个高性能服务器搭建的模块。
1.1Buffer模块
Buffer模块是一个缓冲区模块,用于实现通信中用户态的接收缓冲区和发送缓冲区功能
功能:用于实现通信套接字的用户态缓冲区
意义:
1.防止接收到的数据不是一条完整的数据,因此对接收的数据进行缓存
2.对于客户端响应的数据,应该是在套接字可写的情况下进行发送
功能设计:
1.向缓冲区添加数据
2.从缓冲区中取出数据
1.2.Socket模块
Socket模块是对套接字操作封装的一个模块,主要实现的socket的各项操作。
功能:对socket套接字的操作进行封装
意义:程序中对于套接字的各项操作更加简便
功能设计:
1.创建套接字
2.绑定地址信息
3.开始监听
4.向服务器发起连接
5.获取新连接
6.接收数据
7.发送数据
8.创建一个监听连接
9.创建一个客户端连接
10.设置套接字选项–开启地址端口复用
11.设置套接字阻塞属性–设置为非阻塞
1.3Channel模块
Channel模块是对一个描述符需要进行的IO事件管理的模块,实现对描述符可读,可写,错误事件的管理操作,以及Poller模块对描述符进行IO事件监控就绪后,根据不同的事件,回调不同的处理函数功能。
功能:对于一个描述符进行监控事件的管理
意义:对于描述符的监控事件在用户态更容易维护,以及触发事件后的操作流程更加的清晰
功能设计:
1.对监控事件的管理:
1.1描述符是否可读
1.2描述符是否可写
1.3对描述符监控可读
1.4对描述符监控可写
1.5解除对可读事件监控
1.6解除对可写事件监控
1.7解除所有事件监控
2.对监控事件触发后处理:设置对于不同事件的回调函数,明确触发了某个事件之后应该怎么处理
1.4Connection模块
功能:
1.这是一个对于通信连接进行整体管理的一个模块。对一个连接的操作都是通过这个模块进行的
2.Connection模块,一个连接有任何的事件该怎么处理都是由这个模块来进行处理的,因为组件的设计也不知道使用者要如何处理事件。因此只能是提供一些事件回调函数由使用者设置
意义:这个模块本身来说不是一个单独的功能模块,是一个对连接做管理的模块。增加连接操作的灵活以及使捷性
功能设计:
1.关闭连接
2.发送数据
3.协议切换
4.启动非活跃连接超时释放
5.取消非活跃连接超时释放
6.回调函数设置:
1.连接建立完成的回调
2.连接有新数据接收成功后的回调
3.连接关闭时的回调
4.产生任何事件进行的回调
Connection模块是对Buffer模块,Socket模块,Channel模块的一个整体封装,实现了对一个通信套接字的整体的管理,每一个进行数据通信的套接字(也就是accept获取到的新连接)都会使用Connection进行管理。
Connection模块内部包含有四个由组件使用者传入的回调函数:连接建立完成回调,事件回调,新数据回调,关闭回调。
Connection模块内部包含有两个组件使用者提供的接口:数据发送接口,连接关闭接口
Connection模块内部包含有两个用户态缓冲区:用户态接收缓冲区,用户态发送缓冲区
Connection模块内部包含有一个Socket对象:完成描述符面向系统的IO操作
Connection模块内部包含有一个Channel对象:完成描述符IO事件就绪的处理
具体处理流程如下:
1.实现向Channel提供可读,可写,错误等不同事件的IO事件回调函数,然后将Channel和对应的描述符添加到Poller事件监控中。
2.当描述符在Poller模块中就绪了IO可读事件,则调用描述符对应Channel中保存的读事件处理函数,进行数据读取,将socket接收缓冲区全部读取到Connection管理的用户态接收缓冲区中。然后调用由组件使用者传入的新数据到来回调函数进行处理。
3.组件使用者进行数据的业务处理完毕后,通过Connection向使用者提供的数据发送接口,将数据写入Connection的发送缓冲区中。
4.启动描述符在Poll模块中的IO写事件监控,就绪后,调用Channel中保存的写事件处理函数,将发送缓冲区中的数据通过Socket进行面向系统的实际数据发送。
1.5Acceptor模块
功能:对监听套接字进行管理
意义:
1.当获取了一个新建连接的描述符之后,需要为这个通信连接,封装一个Connection对象,设置各种不同回调
2.注意:因为Acceptor模块本身并不知道一个连接产生了某个事件该如何处理,因此获取一个通信连接后,Connection的封装,以及事件回调的设置都应该由服务器模块来进行
功能设计:回调函数设置,新建连接获取成功的回调设置,由服务器来指定
Acceptor模块是对Socket模块,Channel模块的一个整体封装,实现了对一个监听套接字的整体的管理。
Acceptor模块内部包含有一个Socket对象:实现监听套接字的操作
Acceptor模块内部包含有一个Channel对象:实现监听套接字IO事件就绪的处理
具体处理流程如下:
1.实现向Channel提供可读事件的IO事件处理回调函数,函数的功能其实也就是获取新连接
2.为新连接构建一个Connection对象出来。
1.6TimerQueue模块
功能:定时任务模块,让一个任务可以在指定的时间之后被执行
意义:组件内部,对于非活跃连接希望在N秒之后被释放
功能设计:
1.添加定时任务
2.刷新定时任务:希望一个定时任务重新开始计时
3.取消定时任务
TimerQueue模块是实现固定时间定时任务的模块,可以理解就是要给定时任务管理器,向定时任务管理器中添加一个任务,任务将在固定时间后被执行,同时也可以通过刷新定时任务来延迟任务的执行。这个模块主要是对Connection对象的生命周期管理,对非活跃连接进行超时后的释放功能。
TimerQueue模块内部包含有一个timerfd:Linux系统提供的定时器。
TimerQueue模块内部包含有一个Channel对象:实现对timerfd的IO时间就绪回调处理
1.7Poller模块
功能:对任意的描述符进行lO事件监控
意义:对epoll进行的封装,让对描述符进行事件监控的操作更加简单
功能接口:
1.添加事件监控:Channel模块
2.修改事件监控
3.移除事件监控
Poller模块是对epoll进行封装的一个模块,主要实现epoll的IO事件添加,修改,移除,获取活跃连接功能。
1.8EventLoop模块
功能:
1.进行事件监控管理的模块
2.这个模块其实就是我们所说的one thread one loop中的loop,也是我们所说的reactor
3.这个模块必然是一个模块对应一个线程
意义:
1.对于服务器中的所有的事件都是由EventLoop模块来完成
2.每一个Connection连接,都会绑定一个EventLoop模块和线程,因为外界对于连接的所有操作,都是要放到同一个线程中进行的
思想:
1.对所有的连接进行事件监控,连接触发事件后调用回调进行处理
2.对于连接的所有操作,都要放到EventLoop线程中执行
功能设计:
1.将连接的操作任务添加到任务队列
2.定时任务的添加
3.定时任务的刷新
4.定时任务的取消
EventLoop模块可以理解就是我们上边所说的Reactor模块,它是对Poller模块,TimerQueue模块,Socket模块的一个整体封装,进行所有描述符的事件监控。EventLoop模块必然是一个对象对应一个线程的模块,线程内部的目的就是运行EventLoop的启动函数。
EventLoop模块为了保证整个服务器的线程安全问题,因此要求使用者对于Connection的所有操作一定要在其对应的EventLoop线程内完成,不能在其他线程中进行(比如组件使用者使用Connection发送数据,以及关闭连接这种操作)。
EventLoop模块保证自己内部所监控的所有描述符,都要是活跃连接,非活跃连接就要及时释放避免资源浪费。
EventLoop模块内部包含有一个eventfd:eventfd其实就是Linux内核提供的一个事件fd,专门用于事件通知。
EventLoop模块内部包含有一个Poller对象:用于进行描述符的IO事件监控。
EventLoop模块内部包含有一个TimerQueue对象:用于进行定时任务的管理。
EventLoop模块内部包含有一个PendingTask队列:组件使用者将对Connection进行的所有操作,都加入到任务队列中,由EventLoop模块进行管理,并在EventLoop对应的线程中进行执行。
每一个Connection对象都会绑定到一个EventLoop上,这样能保证对这个连接的所有操作都是在一个线程中完成的。
具体操作流程:
1.通过Poller模块对当前模块管理内的所有描述符进行IO事件监控,有描述符事件就绪后,通过描述符对应的Channel进行事件处理。
2.所有就绪的描述符IO事件处理完毕后,对任务队列中的所有操作顺序进行执行。
3.由于epoll的事件监控,有可能会因为没有事件到来而持续阻塞,导致任务队列中的任务不能及时得到执行,因此创建了eventfd,添加到Poller的事件监控中,用于实现每次向任务队列添加任务的时候,通过向eventfd写入数据来唤醒epoll的阻塞。
1.9TcpServer模块
功能:对前边所有子模块的整合模块,是提供给用户用于搭建一个高性能服务器的模块
意义:让组件使用者可以更加轻使的完成—个服务器的搭建
功能设计:
1.对于监听连接的管理
2.对于通信连接的管理
3.对于超时连接的管理
4.对于事件监控的管理
5.事件回调函数的设置:一个连接产生了一个事件,对于这个事件如何处理,只有组件使用者知道,因此一个事件的处理回调,一定是组件使用者,设置给TcpServer,TcpServer设置给各个Connection连接
这个模块是一个整体TCP服务器模块的封装,内部封装了Acceptor模块,EventLoop ThreadPool模块。
TcpServer中包含有一个EventLoop对象:以备在超轻量使用场景中不需要EventLoop线程池,只需要在主线程中完成所有操作的情况。
TcpServer模块内部包含有一个EventLoop ThreadPool对象:其实就是EventLoop线程池,也就是子Reactor线程池
TcpServer模块内部包含有一个Acceptor对象:一个TcpServer服务器,必然对应有一个监听套接字,能够完成获取客户端新连接,并处理的任务。
TcpServer模块内部包含有一个std::shared_ptr的hash表:保存了所有的新建连接对应的Connection,注意,所有的Connection使用shared_ptr进行管理,这样能够保证在hash表中删除了Connection信息后,在shared_ptr计数器为0的情况下完成对Connection资源的释放操作。
具体操作流程如下:
1.在实例化TcpServer对象过程中,完成BaseLoop的设置,Acceptor对象的实例化,以及EventLoop线程池的实例化,以及std::shared_ptr的hash表的实例化。
2.为Acceptor对象设置回调函数:获取到新连接后,为新连接构建Connection对象,设置Connection的各项回调,并使用shared_ptr进行管理,并添加到hash表中进行管理,并为Connection选择一个EventLoop线程,为Connection添加一个定时销毁任务,为Connection添加事件监控,
3.启动BaseLoop。
2.HTTP协议模块
HTTP协议模块用于对高并发服务器模块进行协议支持,基于提供的协议支持能够更方便的完成指定协议服务器的搭建。而HTTP协议支持模块的实现,可以细分为以下几个模块。
2.1Util模块
这个模块是一个工具模块,主要提供HTTP协议模块所用到的一些工具函数,比如url编解码,文件读写等。
2.2HttpRequest模块
这个模块是HTTP请求数据模块,用于保存HTTP请求数据被解析后的各项请求元素信息。
2.3HttpResponse模块
这个模块是HTTP响应数据模块,用于业务处理后设置并保存HTTP响应数据的的各项元素信息,最终会被按照HTTP协议响应格式组织成为响应信息发送给客户端。
2.4HttpContext模块
这个模块是一个HTTP请求接收的上下文模块,主要是为了防止在一次接收的数据中,不是一个完整的HTTP请求,则解析过程并未完成,无法进行完整的请求处理,需要在下次接收到新数据后继续根据上下文进行解析,最终得到一个HttpRequest请求信息对象,因此在请求数据的接收以及解析部分需要一个上下文来进行控制接收和处理节奏。
2.5HttpServer模块
这个模块是最终给组件使用者提供的HTTP服务器模块了,用于以简单的接口实现HTTP服务器的搭建。
HttpServer模块内部包含有一个TcpServer对象:TcpServer对象实现服务器的搭建
HttpServer模块内部包含有两个提供给TcpServer对象的接口:连接建立成功设置上下文接口,数据处理接口。
HttpServer模块内部包含有一个hash-map表存储请求与处理函数的映射表:组件使用者向HttpServer设置哪些请求应该使用哪些函数进行处理,等TcpServer收到对应的请求就会使用对应的函数进行处理。
整体的模块示意图如下:
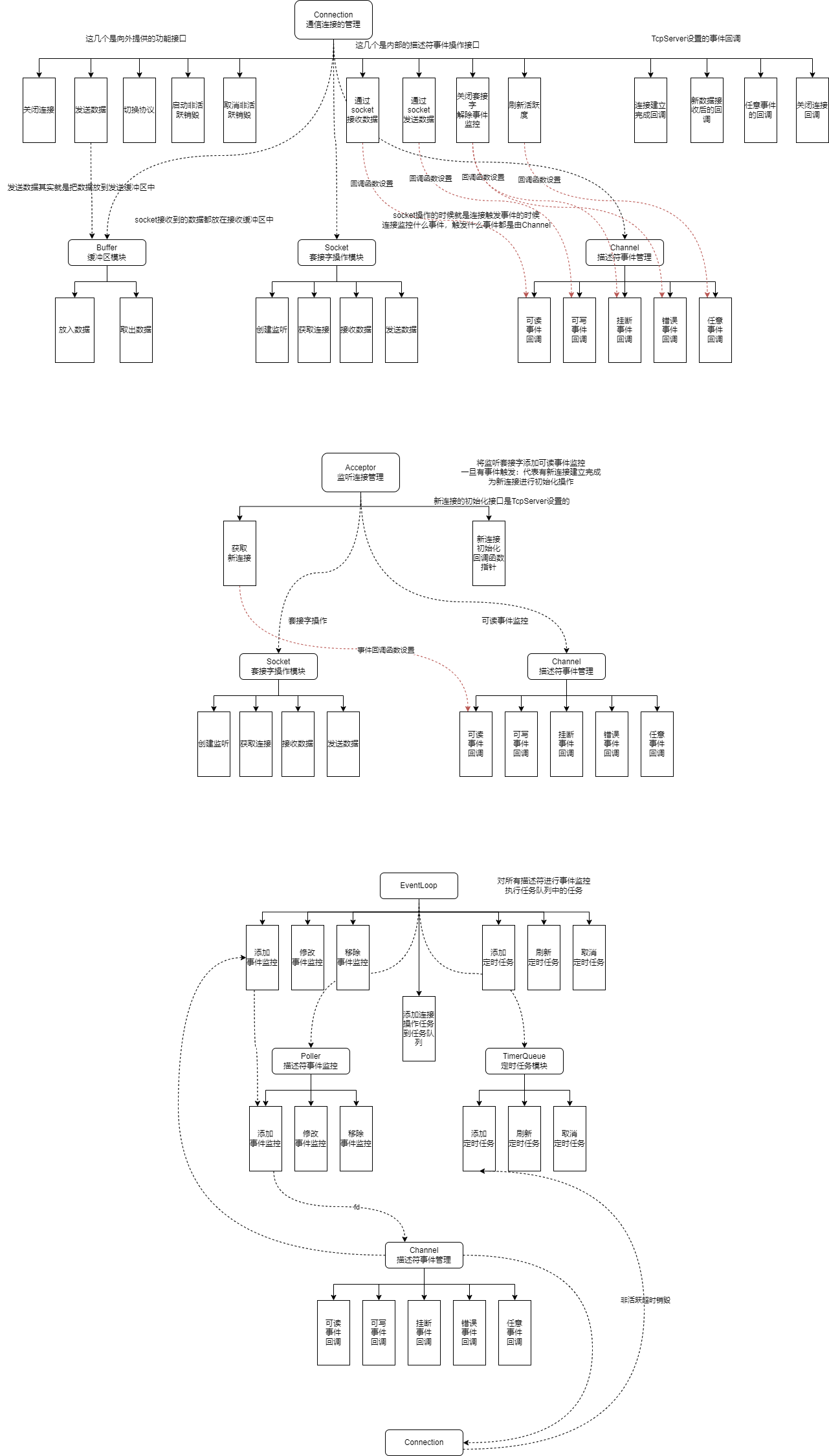
五、模块关系图
Connection 模块关系图,Acceptor 模块关系图,EventLoop 模块关系图
六、SERVER服务器模块实现
1.缓冲区Buffer类实现
Buffer模块:缓冲区模块
提供的功能:存储数据,取出数据
实现思想:
1.实现缓冲区得有一块存储空间,采用vector vector底层其实使用的就是一块线性的空间
2.要素:
1.默认空间的大小
2.当前的读取数据位置
3.当前的写入数据位置
3.操作:
1.写入数据:当前写入位置指向哪里,就从哪里开始写入,如果后续剩余的空间不够了,考虑整体缓冲区空间是否足够(因为读位置也会向后偏移,前边有可能会有空闲空间)如果空间足够,将数据移动到起始位置即可,如果空间不够,就进行扩容,从当前写位置开始扩容足够空间大小,数据一旦写入成功,当前写位置就要向后偏移
2.读取数据:当前的读取位置指向哪里,就从哪里开始读取,前提是有数据可读,可读数据大小:当前写入位置减去当前读取位置
Buffer 模块的设计思想如下:

框架设计:
class Buffer
{
private:
std::vector<char> _buffer;
/*位置是一个相对偏移量,而不是绝对地址*/
uint64_t _read_index;// 读位置
uint64_t _write_index;// 写位置
public:
// 1.获取当前写位置地址
// 2.确保可写空间足够(移动+扩容)
// 3.获取前沿空闲空间大小
// 4.获取后沿空闲空间大小
// 5.将写位置向后移动指定长度
// 6.获取当前读位置地址
// 7.获取可读数据大小
// 8.将读位置向后移动指定长度
// 9.清理功能
};
具体实现:
#define BUFFER_DEFAULT_SIZE 1024
class Buffer
{
private:
std::vector<char> _buffer; // 使用vector进行内存空间管理
uint64_t _reader_idx; // 读偏移
uint64_t _writer_idx; // 写偏移
public:
Buffer() : _reader_idx(0), _writer_idx(0), _buffer(BUFFER_DEFAULT_SIZE) {
}
~Buffer() {
}
public:
// 获取起始地址
char *Begin() {
return &*_buffer.begin(); }
// 获取当前写入起始位置 _buffer的空间起始地址加上写偏移量
char *WritePosition() {
return Begin() + _writer_idx; }
// 获取当前读物起始位置
char *ReadPosition() {
return Begin() + _reader_idx; }
// 获取前沿空闲空间大小(缓冲区末尾)--写偏移之后的空闲空间,总体空间大小减去写偏移
uint64_t TailIdleSize() {
return _buffer.size() - _writer_idx; }
// 获取后沿空闲空间大小(缓冲区起始)--读偏移之前的空闲空间--读偏移之前的空闲空间
uint64_t HeadIdleSize() {
return _reader_idx; }
// 获取可读数据大小 写偏移-读偏移
uint64_t ReadAbleSize() {
return _writer_idx - _reader_idx; }
// 将读偏移向后移动
void MoveReadOffset(const uint64_t &len)
{
if (len == 0)
return;
// 读偏移向后移动的大小,必须小于可读数据大小
assert(len <= ReadAbleSize());
_reader_idx += len;
}
// 将写偏移向后移动
void MoveWriteOffset(const uint64_t &len)
{
if (len == 0)
return;
// 写偏移向后移动的大小,必须小于后边的空闲空间大小
assert(len <= TailIdleSize());
_writer_idx += len;
}
// 确保可写空间足够(整体空间足够了就一定数据,否则就扩容)
void EnsureWriteSpace(const uint64_t &len)
{
// 1.如果末尾空闲空间大小足够,直接返回
if (len <= TailIdleSize())
{
return;
}
// 2.末尾空闲空间不够,则判断加上起始空闲空间大小是否足够,足够就将数据移动到起始位置
else if (len <= TailIdleSize() + HeadIdleSize())
{
// 将数据移动到起始位置
uint64_t readablesize = ReadAbleSize(); // 把当前数据大小先保存起来
// 将数据拷贝到起始位置
// std::copy(ReadPosition(),WritePosition(),Begin());
std::copy(ReadPosition(), ReadPosition() + readablesize, Begin());
_reader_idx = 0; // 将读偏移归0
_writer_idx = readablesize; // 将写位置置为可读数据大小
}
// 3.总体空间不够,则需要扩容,不移动数据,直接给写偏移之后扩容足够空间即可
else
{
_buffer.resize(_writer_idx + len);
}
}
// 写入数据
void Write(const void *buffer, const uint64_t &len)
{
// 1.保证有足够的空间 2.将数据拷贝进去
if (len == 0)
return;
EnsureWriteSpace(len);
const char *d = (const char *)buffer;
std::copy(d, d + len, WritePosition());
}
// 写入数据并且写偏移向后移动
void WriteAndPush(const void *buffer, const uint64_t &len)
{
Write(buffer, len);
MoveWriteOffset(len);
}
// 写入字符串
void WriteString(std::string &data)
{
// return Write(&data[0], data.size());
return Write(data.c_str(), data.size());
}
// 写入字符串并且写偏移向后移动
void WriteStringAndPush(std::string &data)
{
WriteString(data);
MoveWriteOffset(data.size());
}
// 写入一个Buffer对象
void WriteBuffer(Buffer &data)
{
return Write(data.ReadPosition(), data.ReadAbleSize());
}
void WriteBufferAndPush(Buffer &data)
{
WriteBuffer(data);
MoveWriteOffset(data.ReadAbleSize());
}
// 读取数据
void Read(void *buffer, const uint64_t &len)
{
// 要求要获取的数据大小必须小于可读数据大小
assert(len <= ReadAbleSize());
std::copy(ReadPosition(), ReadPosition() + len, (char *)buffer);
}
// 读取数据并读偏移向后移动
void ReadAndPop(void *buffer, const uint64_t &len)
{
Read(buffer, len);
MoveReadOffset(len);
}
// 读取数据放入一个字符串中
std::string ReadAsString(const uint64_t &len)
{
// 要求要获取的数据大小必须小于可读数据大小
assert(len <= ReadAbleSize());
std::string str;
str.resize(len);
Read(&str[0], len);
return str;
}
std::string ReadAsStringAndPop(const uint64_t &len)
{
assert(len <= ReadAbleSize());
std::string str = ReadAsString(len);
MoveReadOffset(len);
return str;
}
// 找到换行字符
char *FindCRLF()
{
char *res = (char *)memchr(ReadPosition(), '\n', ReadAbleSize());
return res;
}
// 获取一行数据
std::string GetOneLine()
{
char *pos = FindCRLF();
if (pos == nullptr)
return "";
// +1是为了将换行字符也取出来
return ReadAsString(pos - ReadPosition() + 1);
}
std::string GetOneLineAndPop()
{
std::string str = GetOneLine();
MoveReadOffset(str.size());
return str;
}
// 清空缓冲区
void Clear()
{
_reader_idx = 0;
_writer_idx = 0;
}
};
2.日志宏的实现
#include <iostream>
#include <ctime>
#include <thread>
// 日志宏实现一
#define NORMAL 0
#define DEBUG 1
#define ERROR 2
#define LOG_LEVEL DEBUG
#define LOG(level,format,...) do{
\
if(level < NORMAL) break;\
time_t t = time(nullptr);/*获取时间戳*/\
struct tm* ltm = localtime(&t);/*将时间戳转换为格式化的时间*/ \
char buffer[32] = {
0};\
strftime(buffer,31,"%H:%M:%S",ltm);/*获取时分秒*/\
/*##解除必须传递可变参数的限制*/\
fprintf(stdout,"[%p %s %s:%d]" format "\n",(void*)pthread_self(),buffer,__FILE__,__LINE__,##__VA_ARGS__);\
}while(0)
#define NOR_LOG(format,...) LOG(NORMAL,format,##__VA_ARGS__)
#define DBG_LOG(format,...) LOG(DEBUG,format,##__VA_ARGS__)
#define ERR_LOG(fromat,...) LOG(ERROR,format,##__VA_ARGS__)
// 日志宏实现二
enum
{
NORMAL,
DEBUG,
WARNING,
ERROR,
FATAL
};
// 将日志等级转换为字符串
const char *level_to_string(int level)
{
switch (level)
{
case NORMAL:
return "NORMAL";
case DEBUG:
return "DEBUG";
case WARNING:
return "WARNING";
case ERROR:
return "ERROR";
case FATAL:
return "FATAL";
default:
return "";
}
}
#define LogMessage(level, format, ...) \
do \
{
\
const char *level_str = level_to_string(level); /*日志等级*/ \
time_t ts = time(nullptr); /*时间戳*/ \
struct tm *lt = localtime(&ts); /*格式化时间*/ \
char buffer[32] = {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











