







 博客围绕C语言展开,C语言作为一种开发语言,在信息技术领域有重要地位。不过因内容缺失,暂无法提供更多关于C语言的关键信息。
博客围绕C语言展开,C语言作为一种开发语言,在信息技术领域有重要地位。不过因内容缺失,暂无法提供更多关于C语言的关键信息。
/*
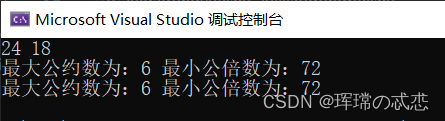
程序: 输入2个数,得最大公约数和最小公倍数
*/
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
//方法一
void Fa1(int m, int n)
{
//辗转相除法求2个数的最大公约数和最小公倍数
//2个数求余时:小 % 大 = 小
//最大公倍数为:2个数相乘除以最大公倍数
int a = m * n;
int t = 0;
while (t = m % n)
{
m = n;
n = t;
}
printf("最大公约数为:%d ", n);
printf("最小公倍数为:%d\n", a / n);
}
//方法二
void Fa2(int m, int n)
{
//先求最小公倍数,再求最大公约数
//最小公倍数是2个数中较大的数的i倍
int i = 1, max = 0;
max = m > n ? m : n;
while (1)
{
if (max * i % m == 0 && max * i % n == 0)
{
break;
}
i++;
}
printf("最大公约数为:%d ", m * n / (max * i));
printf("最小公倍数为:%d\n", max * i);
}
int main()
{
int m = 0, n = 0;
scanf("%d%d", &m, &n);
Fa1(m, n);
Fa2(m, n);
return 0;
}


















 2154
2154

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









